

«`html
Расширение возможностей ИИ с помощью InternVL 1.5: высокое разрешение и двуязычные возможности в открытых моделях
Мультимодальные большие языковые модели (MLLMs) интегрируют обработку текста и визуальных данных для улучшения понимания и взаимодействия искусственного интеллекта с миром. Эта область исследований фокусируется на создании систем, способных понимать и реагировать на сочетание визуальных подсказок и лингвистической информации, имитируя взаимодействие, более близкое к человеческому.
Ограничения открытых моделей и практические решения
Однако часто возникают ограничения в возможностях открытых моделей по сравнению с коммерческими аналогами. Открытые модели часто проявляют недостатки в обработке сложных визуальных данных и поддержке различных языков, что может ограничить их практическое применение и эффективность в различных сценариях.
Исторически большинство открытых MLLMs обучались на фиксированных разрешениях, в основном используя наборы данных, ограниченные английским языком. Такой подход значительно затрудняет их функциональность при работе с изображениями высокого разрешения или содержанием на других языках, что делает сложным успешное выполнение задач, требующих детального визуального понимания или мультиязычных возможностей.
Практические улучшения модели InternVL 1.5
Исследования из Shanghai AI Laboratory, SenseTime Research, Tsinghua University, Nanjing University, Fudan University и The Chinese University of Hong Kong представляют InternVL 1.5, открытую MLLM, разработанную для значительного улучшения возможностей открытых систем в мультимодальном понимании. Эта модель включает три основных улучшения, чтобы сократить разрыв в производительности между открытыми и коммерческими моделями. Три основных компонента:
Во-первых, сильный визионный энкодер InternViT-6B был оптимизирован с помощью стратегии непрерывного обучения, улучшая его возможности визуального понимания.
Во-вторых, динамический подход высокого разрешения позволяет модели обрабатывать изображения до разрешения 4K путем динамической настройки изображений на основе соотношения сторон и разрешения ввода.
Наконец, был тщательно собран высококачественный двуязычный набор данных, охватывающий общие сцены и изображения документов с аннотациями вопрос-ответ на английском и китайском языках.
Эти три шага значительно улучшают производительность модели в задачах OCR и китайского языка. Эти улучшения позволяют InternVL 1.5 успешно конкурировать в различных бенчмарках и сравнительных исследованиях, демонстрируя улучшенную эффективность в мультимодальных задачах.
InternVL 1.5 использует сегментированный подход к обработке изображений, позволяя обрабатывать изображения с разрешением до 4K, разделяя их на плитки размером от 448×448 пикселей, динамически адаптируясь в зависимости от соотношения сторон и разрешения изображения. Этот метод улучшает понимание изображения и облегчает понимание детальных сцен и документов. Улучшенные лингвистические возможности модели обусловлены ее обучением на разнообразном наборе данных, включающем английский и китайский языки, охватывающем различные сцены и типы документов, что улучшает ее производительность в задачах OCR и текстовых задачах на разных языках.
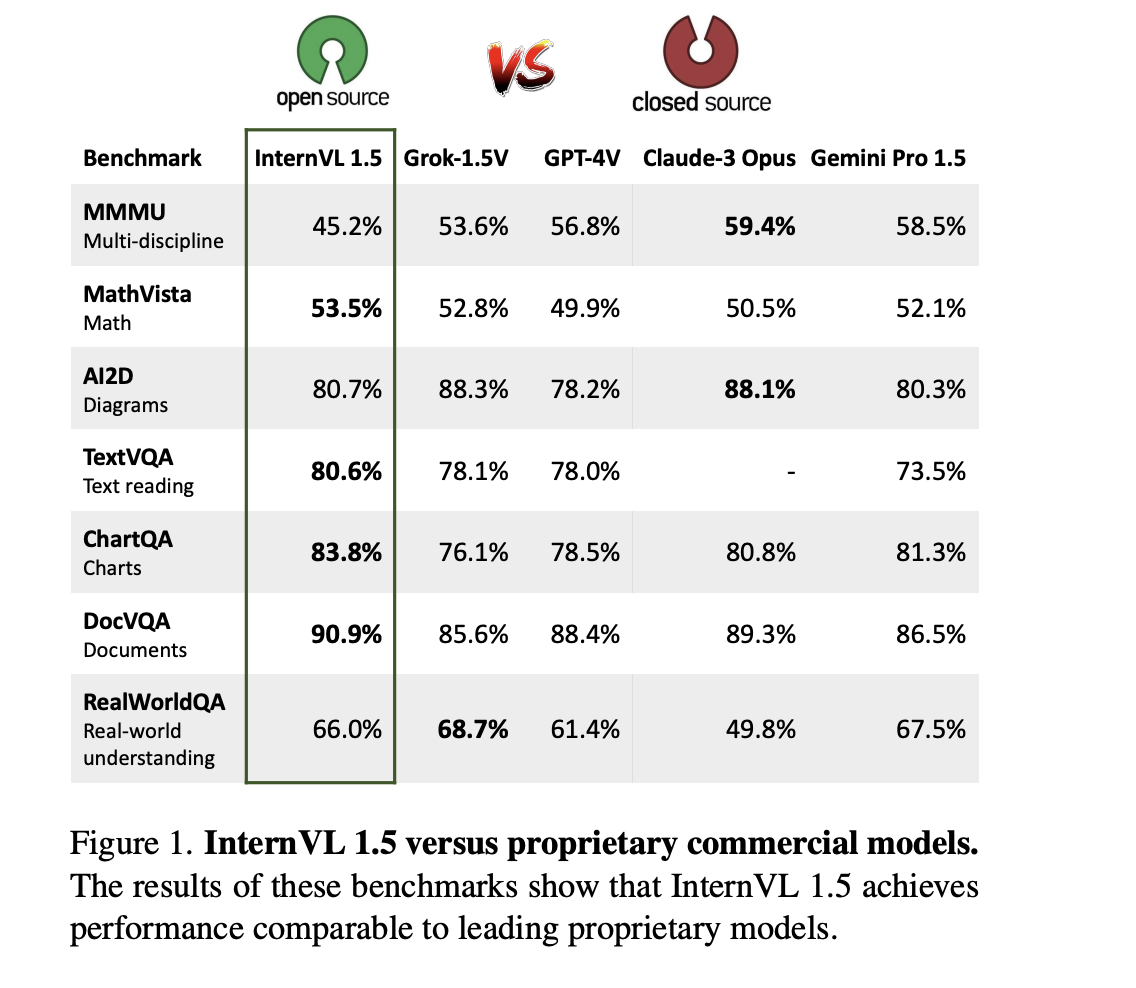
Производительность модели подтверждается ее результатами в различных бенчмарках, где она превосходит другие открытые модели и конкурирует с коммерческими моделями. Например, точность визуального вопросно-ответного задания на основе текста достигает 80,6%, а вопросно-ответная задача на основе документов достигает впечатляющего уровня 90,9%. В мультимодальных бенчмарках, оценивающих модели по визуальному и текстовому пониманию, InternVL 1.5 последовательно демонстрирует конкурентоспособные результаты, часто превосходя другие открытые модели и конкурируя с коммерческими моделями.
Заключение
InternVL 1.5 решает значительные проблемы, с которыми сталкиваются открытые мультимодальные большие языковые модели, особенно в обработке изображений высокого разрешения и поддержке мультиязычных возможностей. Эта модель значительно сокращает разрыв в производительности по сравнению с коммерческими аналогами, реализуя сильный визионный энкодер, динамическую настройку разрешения и обширный двуязычный набор данных. Улучшенные возможности InternVL 1.5 демонстрируются через ее выдающуюся производительность в задачах OCR и мультимодальном понимании сцен, утверждая ее как серьезного конкурента в продвинутых системах искусственного интеллекта.
Посмотрите статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему подразделению ML SubReddit.
Статья опубликована на MarkTechPost.