

«`html
Group Relative Policy Optimization (GRPO) в усовершенствовании математического мышления в открытых языковых моделях
Group Relative Policy Optimization (GRPO) — новый метод обучения с подкреплением, представленный в статье DeepSeekMath в этом году. GRPO основан на фреймворке Proximal Policy Optimization (PPO) и разработан для улучшения математических способностей, снижая потребление памяти. Этот метод предлагает несколько преимуществ, особенно подходящих для задач, требующих продвинутого математического мышления.
Реализация GRPO
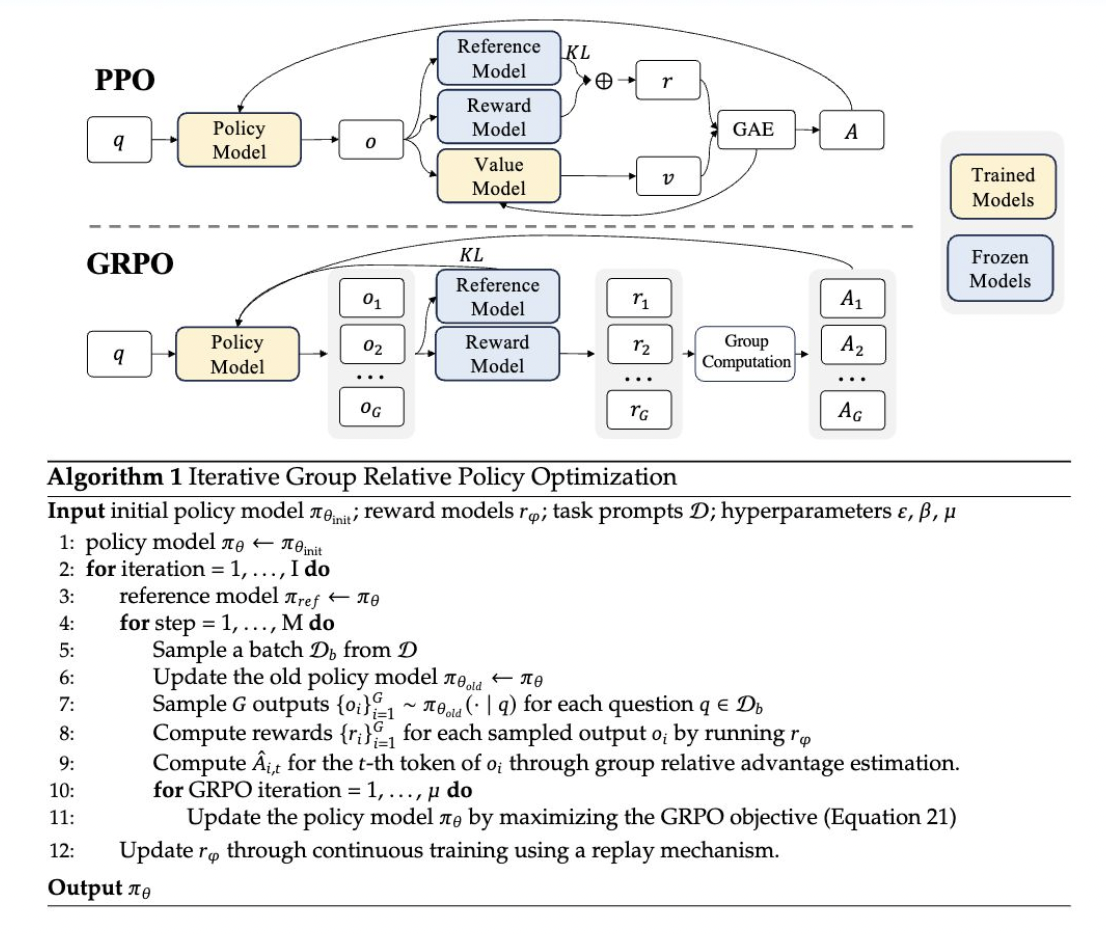
Реализация GRPO включает несколько ключевых шагов:
- Генерация выводов: текущая политика генерирует несколько выводов для каждого входного вопроса.
- Оценка выводов: эти выводы затем оцениваются с использованием модели вознаграждения.
- Вычисление преимуществ: среднее значение этих вознаграждений используется в качестве базовой линии для вычисления преимуществ.
- Обновление политики: политика обновляется для максимизации цели GRPO, которая включает преимущества и термин расхождения KL.
Преимущества и применение GRPO
GRPO внедряет несколько инновационных особенностей и преимуществ:
- Упрощенный процесс обучения: GRPO упрощает процесс обучения и уменьшает потребление памяти, делая его более эффективным и масштабируемым.
- Термин KL в функции потерь: в отличие от других методов, которые добавляют термин расхождения KL к вознаграждению, GRPO интегрирует этот термин непосредственно в функцию потерь, что помогает стабилизировать процесс обучения и улучшить производительность.
- Улучшение производительности: GRPO продемонстрировал значительное улучшение производительности в математических бенчмарках.
Сравнение с другими методами и применение
GRPO имеет сходства с методом Rejection Sampling Fine-Tuning (RFT), но включает уникальные элементы, которые выделяют его. Одним из ключевых отличий является его итерационный подход к обучению моделей вознаграждения.
GRPO был применен к DeepSeekMath, языковой модели, разработанной для математического мышления. Результаты применения GRPO были обнадеживающими, и способность метода улучшать производительность без использования отдельной модели функции ценности подчеркивает его потенциал для более широкого применения в сценариях обучения с подкреплением.
Заключение
Group Relative Policy Optimization (GRPO) значительно продвигает методы обучения с подкреплением, ориентированные на математическое мышление. Его эффективное использование ресурсов, в сочетании с инновационными техниками вычисления преимуществ и интеграции расхождения KL, позиционирует его как отличный инструмент для расширения возможностей открытых языковых моделей.
Если вы хотите узнать, как внедрить ИИ в свой бизнес, свяжитесь с нами по ссылке itinai.
Попробуйте AI Sales Bot itinai.ru/aisales, который поможет вам в автоматизации процессов продаж.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru.
«`



















