

«`html
Методологии Text-to-SQL: практические решения и ценность
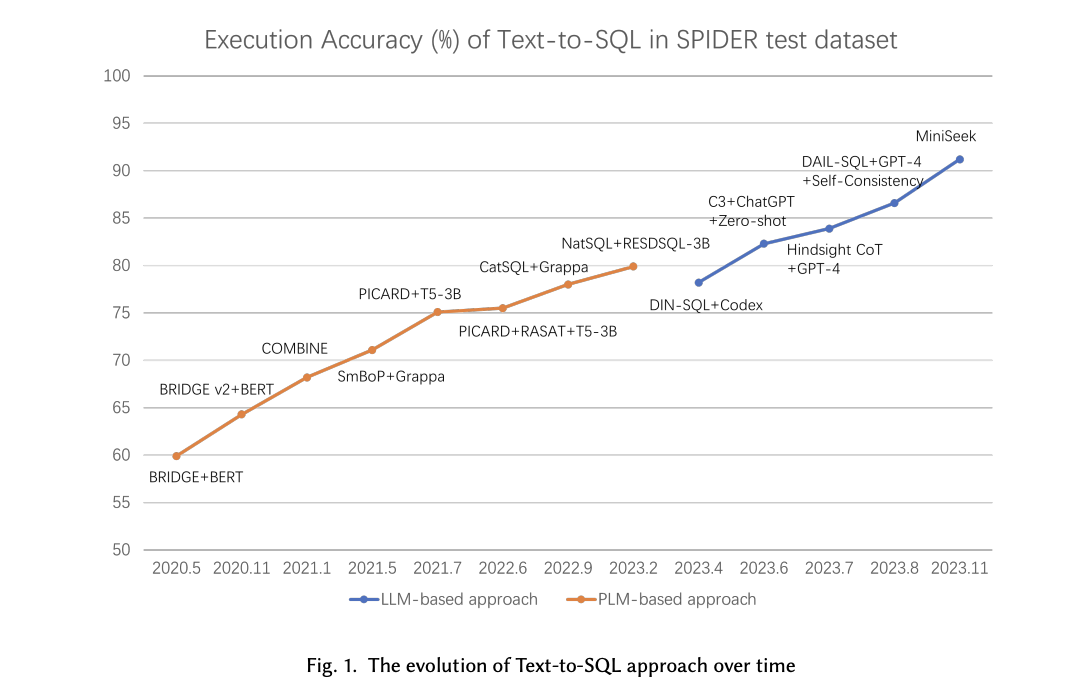
Существующие методологии для Text-to-SQL в основном полагаются на модели глубокого обучения, особенно на модели Sequence-to-Sequence (Seq2Seq), которые стали основными благодаря их способности преобразовывать естественный язык прямо в SQL без промежуточных этапов. Эти модели, усовершенствованные предварительно обученными языковыми моделями (PLM), устанавливают современные стандарты в этой области, используя масштабные корпуса для улучшения своих лингвистических возможностей. Однако переход к большим языковым моделям (LLM) обещает еще более высокую производительность благодаря их масштабным законам и вновь возникающим способностям. Эти LLM с их значительным количеством параметров могут улавливать сложные шаблоны в данных, что делает их отлично подходящими для задачи Text-to-SQL.
Новое исследование от Пекинского университета
Новая научная статья из Пекинского университета решает проблему преобразования естественных языковых запросов в SQL-запросы, процесс, известный как Text-to-SQL. Это преобразование критически важно для обеспечения доступности баз данных для неспециалистов, которые могут не знать SQL, но нуждаются во взаимодействии с базами данных для извлечения информации. Сложность синтаксиса SQL и тонкости понимания схемы базы данных делают это значительной проблемой в обработке естественного языка (NLP) и управлении базами данных.
Предложенный метод в статье
Метод, предложенный в этой статье, использует LLM для задач Text-to-SQL с помощью двух основных стратегий: инженерии запросов и тонкой настройки. Инженерия запросов включает такие техники, как Retrieval-Augmented Generation (RAG), обучение на небольших выборках и рассуждение, которые требуют меньше данных, но иногда могут давать оптимальные результаты. С другой стороны, тонкая настройка LLM с использованием данных, специфичных для задачи, может значительно улучшить производительность, но требует большего обучающего набора данных. В статье исследуется баланс между этими подходами с целью найти оптимальную стратегию, максимизирующую производительность LLM в генерации точных SQL-запросов из естественных языковых вводов.
Многократный анализ и производительность
Статья подробно исследует различные многократные шаблоны рассуждений, которые могут быть применены к LLM для задачи Text-to-SQL. Каждый метод помогает LLM генерировать более точные SQL-запросы, имитируя человеческий подход к решению сложных проблем пошагово и итеративно.
Заключение
Статья предоставляет всеобъемлющий обзор использования LLM для задач Text-to-SQL, выделяя потенциал многократных шаблонов рассуждений и стратегий тонкой настройки для улучшения производительности. Это исследование продвигает современные стандарты в области Text-to-SQL и подчеркивает важность использования возможностей LLM для сокращения разрыва между пониманием естественного языка и запросами к базе данных.
Проверьте статью здесь.
Не забудьте следить за нашими новостями в Twitter и присоединиться к нашей группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу в SubReddit.
Найдите предстоящие вебинары по ИИ здесь.
Оригинальная статья доступна на сайте MarkTechPost.