

«`html
Синтетическое создание данных в машинном обучении
Синтетическое создание данных становится все более важным в области машинного обучения. Эта техника создает обширные наборы данных, когда реальные данные ограничены и дороги. Исследователи могут более эффективно обучать модели машинного обучения, генерируя синтетические данные, улучшая их производительность в различных приложениях. Сгенерированные данные создаются таким образом, чтобы проявлять определенные характеристики, полезные для процесса обучения моделей.
Интеграция синтетических данных в модели машинного обучения
Однако интеграция синтетических данных в модели машинного обучения представляет несколько вызовов, особенно в отношении предвзятости и атрибутов, которые могут внести синтетические данные. Понимание того, как эти унаследованные характеристики влияют на поведение и производительность больших языковых моделей (LLM), критически важно. Основной вопрос заключается в том, могут ли синтетические данные внести непреднамеренные предубеждения или другие атрибуты, которые могут повлиять на выходы модели. Это понимание важно для обеспечения того, что модели, обученные с использованием синтетических данных, являются эффективными и справедливыми, избегая укрепления негативных черт процесса генерации данных.
Методы оптимизации пространства данных
Текущие методы оптимизации пространства данных включают аугментацию данных, псевдо-маркировку, взвешивание данных, обрезку данных и куррикулярное обучение. Аугментация данных расширяет наборы данных путем создания измененных версий существующих данных. Псевдо-маркировка включает генерацию меток для немаркированных данных, эффективно расширяя набор данных. Взвешивание данных назначает разное значение различным точкам данных, а обрезка данных удаляет менее полезные данные, улучшая качество оставшегося набора данных. Куррикулярное обучение структурирует процесс обучения, постепенно вводя более сложные данные. Несмотря на их полезность, эти методы ограничены свойствами, присущими исходным наборам данных, и часто требуют возможности внедрения новых, желательных атрибутов, что ограничивает их эффективность в оптимизации моделей для конкретных характеристик.
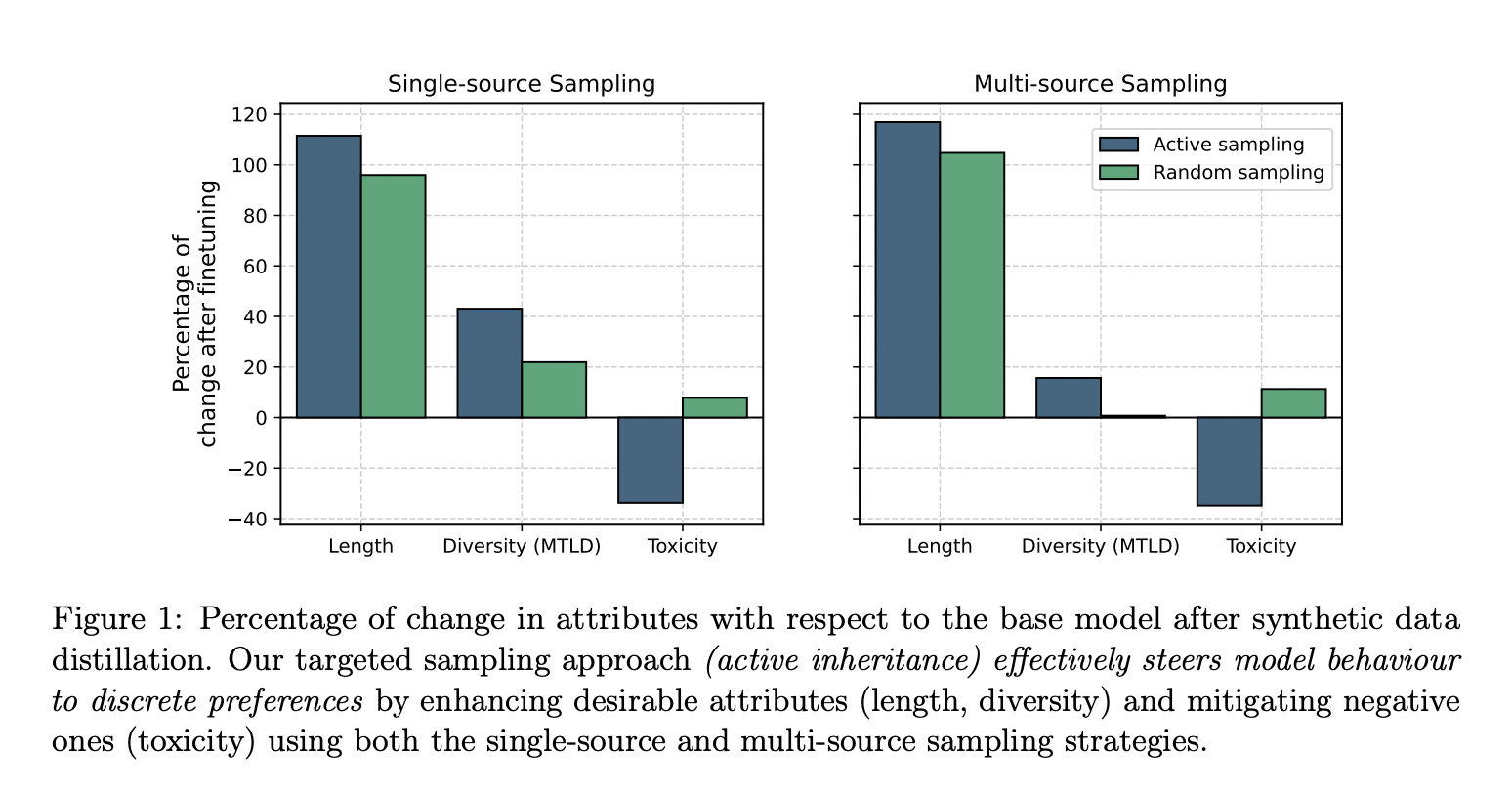
Активное наследие
Исследователи из Cohere for AI and Cohere предложили новую концепцию под названием «активное наследие». Этот метод направлен на умышленное управление процессом генерации синтетических данных в сторону конкретных недифференцируемых целей, таких как высокая лексическая разнообразность и низкая токсичность. Активное наследие включает выбор прокси-меток на основе желаемых характеристик, генерацию нескольких образцов для каждого запроса и выбор образца, который максимизирует желаемый атрибут. Этот подход, известный как целевая выборка, позволяет настраивать модели на конкретные цели с использованием синтетических наборов данных, созданных для улучшения этих характеристик.
Практические результаты
Метод активного наследия показал значительный потенциал. Например, целевая выборка эффективно направляет поведение модели на желаемые характеристики, что приводит к существенным улучшениям. Модели продемонстрировали улучшение длины до 116% и увеличение лингвистического разнообразия до 43%. Более того, метод снизил токсичность до 40%. Эти результаты подчеркивают потенциал активного наследия для улучшения качества и безопасности языковых моделей. Сосредотачиваясь на конкретных характеристиках, исследователи могут обеспечить, что модели обладают желательными чертами, минимизируя негативные.
Заключение
Исследование подчеркивает значительное влияние синтетических данных на характеристики больших языковых моделей. Введя концепцию активного наследия, исследователи из Cohere предоставили прочную основу для управления синтетическим созданием данных в сторону желательных характеристик. Этот метод улучшает конкретные атрибуты, такие как лексическая разнообразность и снижение токсичности, обеспечивая эффективность и безопасность моделей, обученных с использованием синтетических данных. Результаты исследования показывают, что возможно успешно и эффективно внедрить желаемые атрибуты в генерацию моделей с минимальными усилиями. Активное наследие представляет собой многообещающий подход к оптимизации моделей машинного обучения, открывая путь к более сложным и надежным системам искусственного интеллекта.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 46k+ ML SubReddit.
The post Cohere for AI Enhances Large Language Models LLMs with Active Inheritance: Steering Synthetic Data Generation for Optimal Performance and Reduced Bias appeared first on MarkTechPost.
«`
«`html
Применение искусственного интеллекта в продажах и маркетинге
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Cohere for AI Enhances Large Language Models LLMs with Active Inheritance: Steering Synthetic Data Generation for Optimal Performance and Reduced Bias.
Практические шаги
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`



















