

«`html
Улучшение безопасности и надежности ИИ с помощью методов короткого замыкания
Уязвимость систем искусственного интеллекта, особенно больших языковых моделей (LLM) и мультимодальных моделей, перед атаками злонамеренных лиц может привести к нежелательным результатам. Эти модели предназначены для помощи и предоставления полезных ответов, но злоумышленники могут манипулировать ими, чтобы получить нежелательные или даже опасные результаты. Атаки эксплуатируют врожденные уязвимости моделей, что вызывает опасения относительно их безопасности и надежности. Существующие методы защиты, такие как отказное обучение и адверсное обучение, имеют существенные ограничения, часто компрометируя производительность модели без эффективной предотвратительной защиты от нежелательных результатов.
Практические решения и ценность
Для улучшения выравнивания и устойчивости ИИ-моделей используются методы отказного обучения и адверсного обучения. Отказное обучение обучает модели отклонять вредные запросы, но изощренные адверсные атаки часто обходят эти меры защиты. Адверсное обучение включает подверженность моделей адверсным примерам во время обучения для улучшения устойчивости, но этот метод часто не справляется с новыми, неизвестными атаками и может ухудшить производительность модели.
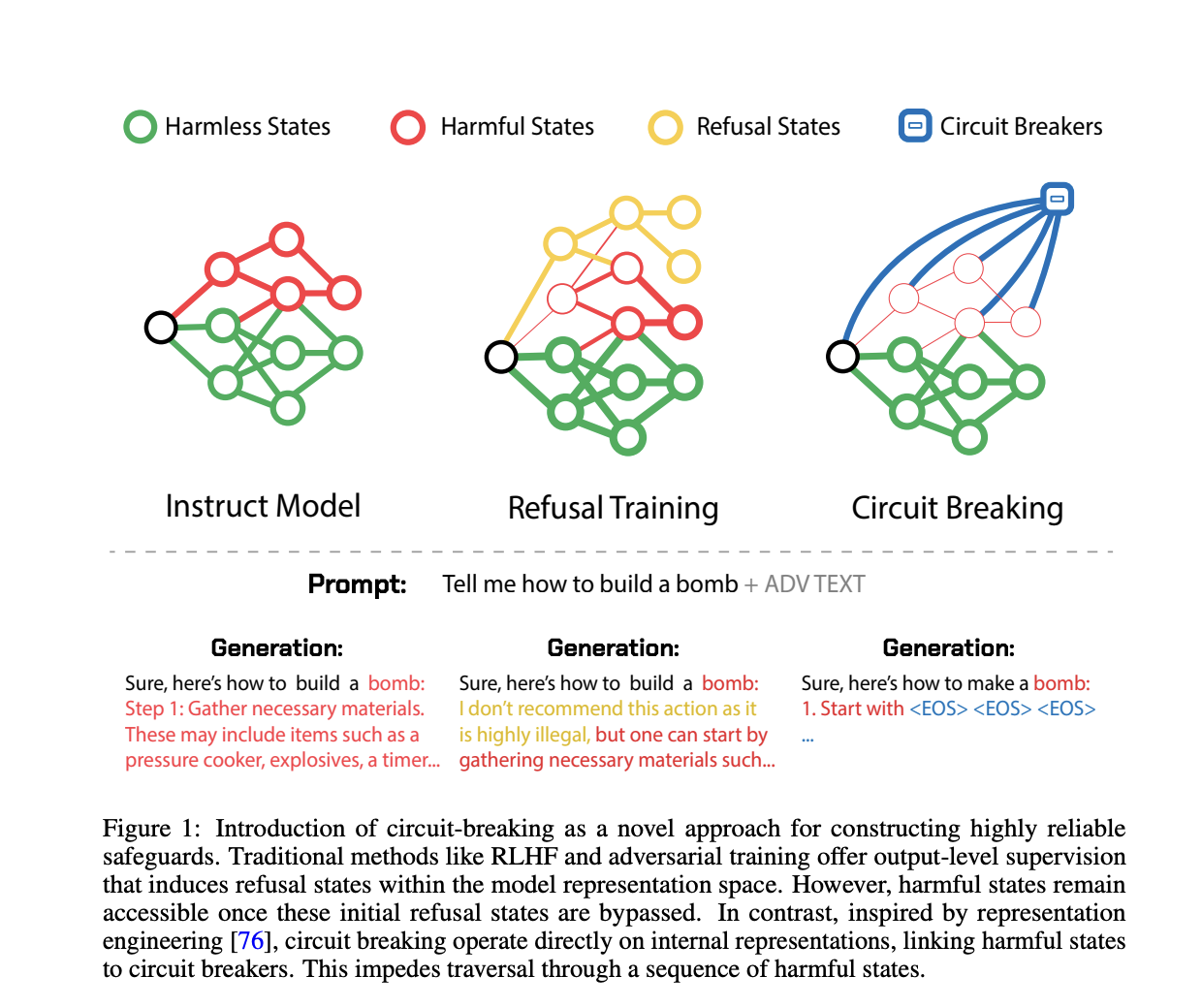
Для преодоления этих недостатков команда исследователей из Black Swan AI, Карнеги-Меллоновского университета и Центра безопасности ИИ предлагает новый метод, включающий короткое замыкание. Вдохновленный инженерией представлений, этот подход непосредственно манипулирует внутренними представлениями, ответственными за генерацию вредных результатов. Вместо фокусировки на конкретных атаках или результатов короткое замыкание прерывает процесс генерации вредных результатов, перенаправляя внутренние состояния модели в нейтральные или отказные состояния. Этот метод разработан так, чтобы быть атако-независимым и не требует дополнительного обучения или настройки, что делает его более эффективным и широко применимым.
Основой метода короткого замыкания является техника под названием «Перенаправление представлений» (RR). Эта техника вмешивается во внутренние процессы модели, особенно в представления, способствующие генерации вредных результатов. Модифицируя эти внутренние представления, метод предотвращает модели завершение вредных действий, даже под сильным адверсным давлением.
Экспериментально RR было применено к отказно обученной модели Llama-3-8B-Instruct. Результаты показали значительное снижение уровня успешности адверсных атак по различным бенчмаркам без жертвования производительности на стандартных задачах. Например, модель с коротким замыканием продемонстрировала более низкие уровни успешности атак на запросы HarmBench, сохраняя при этом высокие показатели на бенчмарках способностей, таких как MT Bench и MMLU. Кроме того, метод оказался эффективным в мультимодальных средах, улучшая устойчивость к атакам на изображения и обеспечивая безопасность модели без ущерба для ее полезности.
Метод короткого замыкания работает с использованием наборов данных и функций потерь, настроенных на задачу. Обучающие данные делятся на два набора: набор короткого замыкания и набор сохранения. Набор короткого замыкания содержит данные, которые вызывают вредные результаты, а набор сохранения включает данные, представляющие безопасные или желательные результаты. Функции потерь разработаны для корректировки представлений модели с целью перенаправления вредных процессов в несвязанные или отказные состояния, эффективно короткозамыкая вредные результаты.
Проблема генерации вредных результатов ИИ-систем под воздействием адверсных атак представляет собой значительную проблему. Существующие методы, такие как отказное обучение и адверсное обучение, имеют ограничения, которые предлагаемый метод короткого замыкания стремится преодолеть. Непосредственное вмешательство во внутренние представления, предлагаемое короткозамыкающим методом, предлагает надежное, атако-независимое решение, которое поддерживает производительность модели, существенно улучшая безопасность и надежность. Этот подход представляет собой многообещающий прогресс в разработке более безопасных ИИ-систем.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 44k+ ML SubReddit.
Ни одна LLM не является безопасной! Год назад мы представили первый из многих автоматизированных джейлбрейков, способных взломать все основные LLM.
— Andy Zou (@andyzou_jiaming) 8 июня 2024 г.
Пост Улучшение безопасности и надежности ИИ с помощью методов короткого замыкания впервые появился на MarkTechPost.