

«`html
Оптимизация симуляций систем Spiking Neural P (SNP): достижение беспрецедентной скорости и эффективности через сжатое представление матриц на графических процессорах с использованием CUDA
Исследования в области систем Spiking Neural P (SNP), подмножества мембранных вычислений, изучают вычислительные модели, вдохновленные биологическими нейронами. Эти системы моделируют взаимодействия нейронов с использованием математических представлений, тесно имитируя естественные нейрональные процессы. Сложность этих моделей делает их ценными для развития таких областей, как искусственный интеллект и высокопроизводительные вычисления. Предоставляя структурированный подход к симуляции нейронного поведения, системы SNP помогают исследователям понять сложные биологические явления и разработать вычислительные инструменты для работы с сложными динамическими системами. Это направление обещает преодолеть разрыв между биологическими процессами и вычислительными моделями, предлагая понимание работы мозга и потенциальные применения в машинном обучении и анализе данных.
Основной вызов в симуляции систем SNP
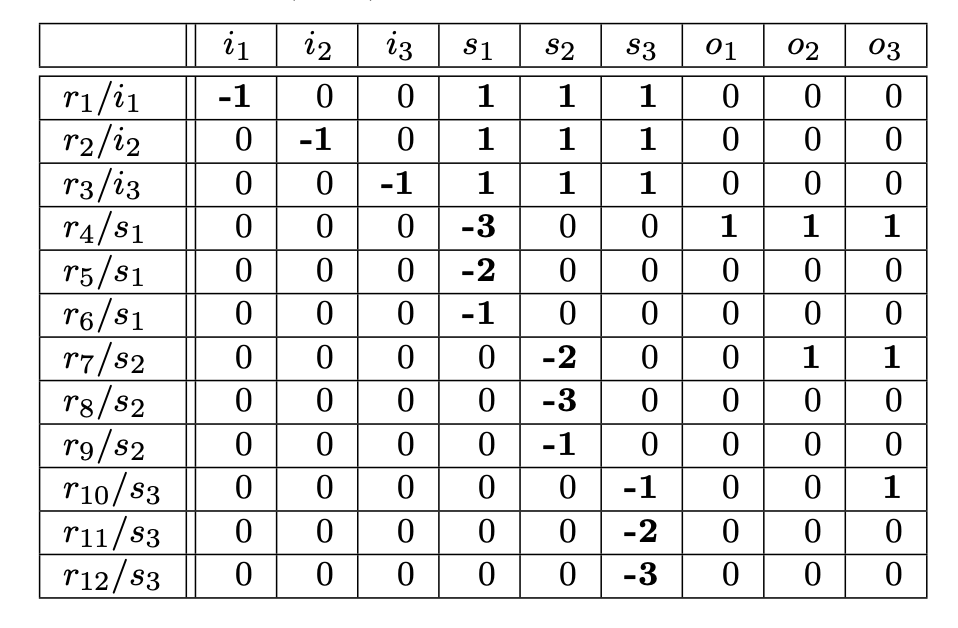
Основной вызов в симуляции систем SNP заключается в эффективном представлении и обработке их внутренних графовых структур на параллельных вычислительных платформах, особенно на графических процессорах (GPU). Традиционные методы симуляции используют плотные матричные представления, которые являются вычислительно затратными и неэффективными, особенно при работе с разреженными матрицами, характерными для большинства систем SNP. Эти неэффективности проявляются в высоком потреблении памяти и продолжительных временах вычислений, ограничивая масштабируемость систем SNP и их практическое использование для решения крупномасштабных сложных задач. Разреженность матрицы, где значительное количество элементов равно нулю, приводит к неэффективному использованию вычислительных ресурсов, так как текущие методы не полностью используют эту характеристику.
Существующие методы и инструменты для симуляции систем SNP
Существующие методы и инструменты для симуляции систем SNP часто полагаются на универсальные библиотеки разреженных матриц, такие как cuBLAS и cuSPARSE, предназначенные для обработки широкого спектра операций с разреженными матрицами на GPU. Однако эти инструменты только частично используют уникальные характеристики систем SNP, что приводит к субоптимальной производительности. Например, cuBLAS, хотя эффективен в операциях с матрицами, не предоставляет специфических оптимизаций для разреженных направленных графов, типичных для систем SNP. Аналогично, cuSPARSE, сжимая матрицы в формат CSR, вводит накладные расходы, которые могут замедлить симуляции. В результате эти методы нуждаются в помощи с учетом специфических требований систем SNP, особенно при работе с большими матрицами с различными уровнями разреженности, что приводит к неэффективным симуляциям, которые могли бы быть более масштабируемыми для более сложных моделей.
Новый метод симуляции систем SNP
Исследователи из Университета Севильи и Университета Филиппин предложили новый подход для решения этих неэффективностей, предложив новый метод симуляции систем SNP с использованием сжатых матричных представлений, нацеленных на GPU. Этот подход, реализованный с использованием модели программирования CUDA, специально нацелен на разреженность матриц систем SNP. Путем сжатия матриц переходов в оптимизированные форматы, такие как ELL и новый метод, называемый «Compressed», исследователи значительно снизили использование памяти и улучшили производительность операций умножения матрицы на вектор. Этот подход позволяет более эффективные и масштабируемые симуляции, что делает возможным работу с системами SNP с и без задержек, тем самым расширяя область применения этих симуляций.
Оценка производительности нового метода
Производительность этого нового метода была оценена с использованием высокопроизводительных GPU, включая RTX2080 и A100. Замечательные результаты показали, что формат «Compressed» может достигать до 83-кратного ускорения по сравнению с традиционными разреженными матричными представлениями при симуляции систем SNP, сортирующих 500 натуральных чисел. Формат ELL также показал значительные улучшения, обеспечивая 34-кратное ускорение по сравнению с разреженным методом. В терминах использования памяти метод «Compressed» требовал значительно меньше памяти, эффективно масштабируясь даже для крупных систем SNP. Например, при симуляции систем SNP с задержками для задачи подмножества сумм, метод «Compressed» продемонстрировал 3,5-кратное ускорение по сравнению с разреженным форматом, используя в 18,8 раз меньше памяти. Масштабируемость этого метода была доказана при обработке размеров входных данных до 46 000 на GPU A100, используя 71 ГБ памяти и завершая симуляцию за 1,9 часа.
Заключение
Исследование представляет новаторский подход к симуляции систем SNP, который значительно улучшает скорость, эффективность использования памяти и масштабируемость по сравнению с существующими методами. Путем использования сжатых матричных представлений, нацеленных на архитектуры GPU, исследователи разработали метод симуляции, который способен обрабатывать более крупные и сложные системы SNP, чем когда-либо прежде. Этот прогресс улучшает производительность симуляций систем SNP и открывает новые возможности для применения этих моделей к реальным вычислительным задачам. Способность метода эффективно масштабироваться с увеличением размера задачи делает его ценным инструментом для исследователей, работающих над сложными системами, обещая преодолеть разрыв между теоретическими моделями и практическими применениями.
«`


















