

«`html
Оценка способностей к временному рассуждению: новый подход в развитии искусственного интеллекта
Исследование в области временного рассуждения включает в себя понимание и интерпретацию отношений между событиями во времени, что является ключевой способностью для интеллектуальных систем. Это область исследований существенна для развития ИИ, способного выполнять различные задачи, начиная от обработки естественного языка до принятия решений в динамических средах. ИИ может выполнять сложные операции, такие как планирование, прогнозирование и анализ исторических данных, точно интерпретируя временнo-связанные данные. Это делает временное рассуждение фундаментальным аспектом развития передовых систем искусственного интеллекта.
Необходимость в новых методах оценки способностей к временному рассуждению
Несмотря на важность временного рассуждения, существующие бенчмарки часто нуждаются в пересмотре. Они сильно зависят от реальных данных, которые могли видеть LLMs во время обучения, или используют техники анонимизации, которые могут привести к неточностям. Это создает необходимость в более надежных методах оценки, которые точно измеряют способности LLM в временном рассуждении. Основной вызов заключается в создании бенчмарков, которые тестируют запоминание и действительно оценивают навыки рассуждения. Это критично для приложений, требующих точного и контекстно-ориентированного понимания времени.
Инновационный подход к оценке временного рассуждения
Для решения этих вызовов исследователи из Google Research, Google DeepMind и Google представили бенчмарк Test of Time (ToT). Этот инновационный бенчмарк использует синтетические наборы данных, специально разработанные для оценки временного рассуждения без использования предварительных знаний моделей. Бенчмарк предоставлен в открытом доступе для стимулирования дальнейших исследований и разработок в этой области. Введение ToT представляет собой значительное развитие, обеспечивая контролируемую среду для систематического тестирования и улучшения навыков временного рассуждения LLMs.
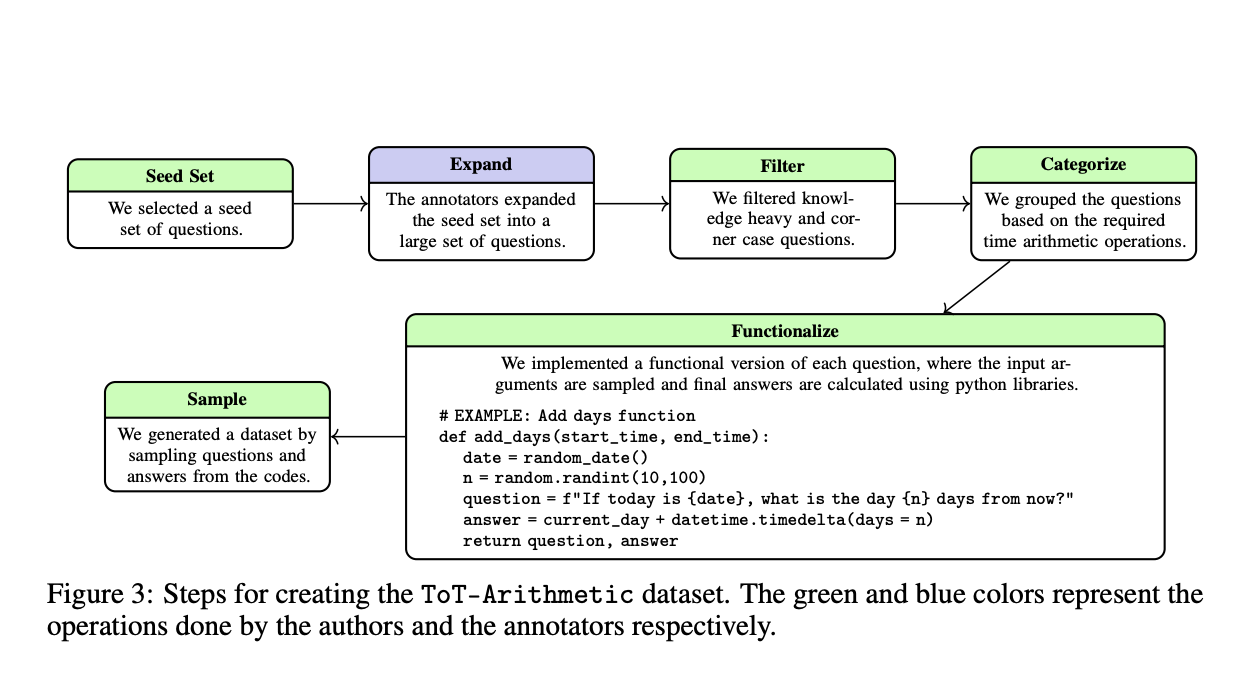
Ключевые задачи ToT бенчмарка
Бенчмарк ToT включает две основные задачи. ToT-Semantic фокусируется на временной семантике и логике, позволяя гибкое изучение разнообразных графических структур и сложностей рассуждений. Эта задача выделяет основные навыки рассуждения из предварительных знаний. ToT-Arithmetic оценивает способность выполнять вычисления, связанные с моментами времени и продолжительностью, используя задачи, созданные сообществом, чтобы обеспечить практическую значимость. Эти задачи тщательно разработаны для охвата различных сценариев временного рассуждения, обеспечивая всестороннюю систему оценки.
Экспериментальные результаты и выводы
Экспериментальные результаты с использованием бенчмарка ToT раскрывают значительные исследовательские выводы о преимуществах и недостатках текущих LLMs. Например, производительность GPT-4 сильно варьировалась в зависимости от различных графических структур, с точностью от 40.25% на полных графах до 92.00% на графах AWE. Эти результаты подчеркивают влияние временной структуры на производительность рассуждения. Кроме того, порядок представления фактов моделям значительно влиял на их производительность, с наивысшей точностью, наблюдаемой при упорядочивании фактов и начального времени.
Исследование также исследовало типы временных вопросов и их уровни сложности. Однофактные вопросы были легче для моделей, в то время как многофактные вопросы, требующие интеграции нескольких кусков информации, представляли больше вызовов. Например, GPT-4 достиг 90.29% точности на вопросах EventAtWhatTime, но испытывал трудности с вопросами Timeline, что указывает на проблемы в обработке сложных временных последовательностей. Детальный анализ типов вопросов и производительности моделей предоставляет четкое представление о текущих возможностях и областях, требующих улучшения.
Заключение
Бенчмарк ToT представляет собой значительное развитие в оценке способностей к временному рассуждению LLMs. Предоставление более всесторонней и контролируемой системы оценки помогает выявить области для улучшения и направляет развитие более способных систем искусственного интеллекта. Этот бенчмарк заложил основу для будущих исследований по улучшению временных способностей LLMs, в конечном итоге способствуя более широкой цели достижения искусственного общего интеллекта.
Подробнее ознакомьтесь с исследованием и HF Page. Вся заслуга за это исследование принадлежит его ученым. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему SubReddit с 44 тыс. подписчиков.
Автор: AI Lab itinai.ru
«`


















