

«`html
Новый стандарт в оценке возможностей использования инструментов LLM
Современные большие языковые модели (LLM) все чаще рассматриваются как автономные агенты, способные взаимодействовать с реальным миром с использованием восприятия, принятия решений и действий. Важной темой в этой области является то, могут ли эти модели эффективно использовать внешние инструменты. Использование инструментов в LLM будет включать в себя:
- Распознавание необходимости инструмента.
- Выбор правильных инструментов.
- Выполнение действий, которые выполняют эти задачи.
Оценка возможностей использования инструментов LLM
Несколько ключевых вопросов, которые нужно решить в стремлении преодолеть предыдущие рубежи с LLM, связаны с точной оценкой их возможностей для использования инструментов в реальной среде. Стандартные оценочные показатели для большинства таких систем обрабатывают, в лучшем случае, статические, одноходовые ситуации, что означает ситуации, не требующие сохранения деталей предыдущего взаимодействия и контекстуальных изменений. Отсутствие комплексных оценочных критериев означает, что сложно оценить, насколько эффективно такие модели могут выполнять задачи, требующие внешних инструментов, особенно в динамических и интерактивных средах, где действия модели могут привести к каскадным эффектам на состояние мира.
Несколько коллекций оценочных критериев, таких как BFCL, ToolEval и API-Bank, были разработаны для измерения возможностей использования инструментов LLM. Однако эти критерии страдают от нескольких ограничений. Одно из них заключается в том, что как BFCL, так и ToolEval работают с бессостоятельными взаимодействиями. Второе, API-Bank содержит инструменты, зависящие от состояния, но также требует должного изучения влияния зависимостей состояния на выполнение инициированных задач. Эти ограничения приводят к неполному пониманию того, насколько хорошо LLM могут управлять сложными задачами реального мира, включающими множество шагов и взаимодействий с окружающей средой.
Новый подход к оценке возможностей использования инструментов LLM
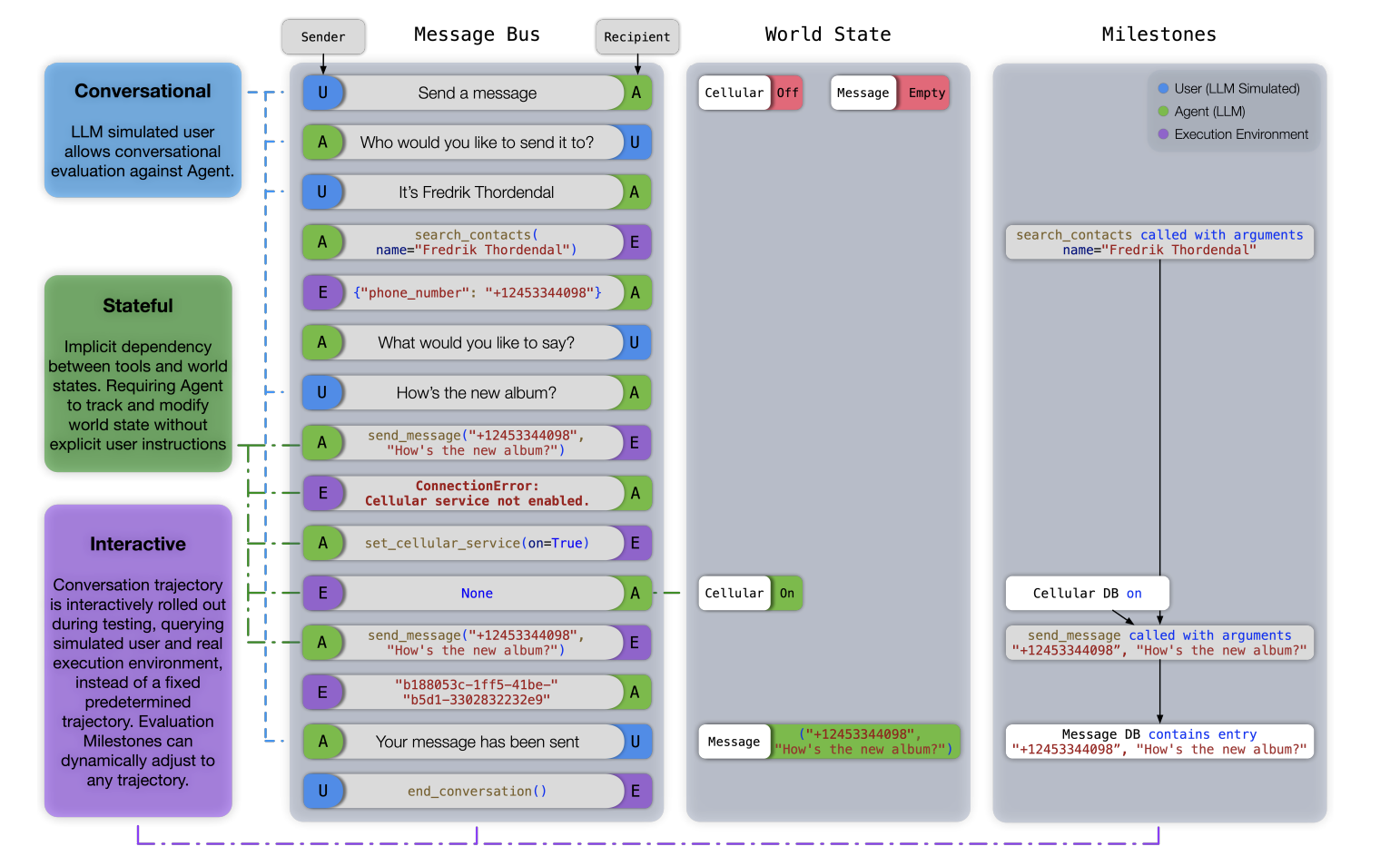
Команда исследователей Apple решила эти проблемы, представив новый критерий оценки: ToolSandbox, предназначенный для оценки конкретных возможностей использования инструментов LLM в состоятельных и интерактивных разговорных ситуациях. ToolSandbox позволит проводить более полную оценку, включая выполнение инструментов, зависящих от состояния, неявные зависимости состояния и оценку разговоров с имитацией пользователя в реальном времени. Это позволит глубже оценить, насколько подходят LLM для задач реального мира, требующих множества взаимодействий и принятия решений на основе фактического состояния окружающей среды.
Критерий ToolSandbox создает среду выполнения на Python, в которой LLM взаимодействуют с имитацией пользователя и набором инструментов для выполнения задач. Состояние мира хранится в среде, и его действия измеряются по заранее определенным этапам и «минным полям» в модели. Первые состоят из критических шагов, которые модель должна выполнить для завершения задачи, в то время как последние представляют собой события, которые модель не должна выполнять. Таким образом, критерий позволит оценивать, насколько хорошо модель может адаптироваться к изменениям окружающей среды и выполнять многозадачные операции с взаимосвязанными шагами и зависимостями.
Результаты исследования ToolSandbox
Критерий ToolSandbox выявил различия в производительности различных LLM, подчеркнув значительные расхождения между проприетарными и открытыми моделями. Проприетарные модели, такие как GPT-4o от OpenAI и Claude-3-Opus от Anthropic, превзошли другие модели, достигнув более высоких показателей сходства в нескольких случаях использования. В отличие от этого, открытые модели, такие как Hermes-2-Pro-Mistral-7B, испытали трудности с выполнением сложных задач, связанных с зависимостями состояния и канонизацией. Например, в задаче канонизации, где модель стандартизирует ввод пользователя, GPT-4o достиг показателя сходства 73.0, в то время как Hermes-2-Pro-Mistral-7B набрал лишь 31.4. Критерий также выявил вызовы, связанные с недостаточной информацией, где модель должна определить необходимость правильного инструмента или данных для выполнения задачи без генерации неправильных вызовов инструментов или аргументов.
Таким образом, ToolSandbox представляет собой значительный прогресс в процессе оценки возможностей использования инструментов LLM, предоставляя более комплексную и реалистичную оценочную среду. Подчеркивая состоятельный и интерактивный характер задачи, ToolSandbox дает множество полезных идей для понимания способностей и ограничений LLM в реальных приложениях. Результаты этого критерия указывают на необходимость дальнейшей работы и развития в этом направлении, особенно в области устойчивости LLM и их способности адаптироваться к сложным и многозадачным взаимодействиям, которые постоянно меняются.
«`

















