

«`html
Понимание документов и его значимость
Понимание документов (DU) фокусируется на автоматической интерпретации и обработке документов, включая сложные структуры макетов и многомодальные элементы, такие как текст, таблицы, графики и изображения. Эта задача является важной для извлечения и использования огромного объема информации, содержащейся в ежегодно создаваемых документах.
Текущие проблемы и решения
Одной из ключевых проблем является понимание длинных документов, охватывающих множество страниц и требующих понимания различных модальностей. Традиционные модели DU для одностраничных документов испытывают затруднения в этом, поэтому критически важно разрабатывать методики оценки производительности моделей на длинных документах. Исследователи выявили, что эти документы требуют специальных возможностей, таких как локализация и понимание на разных страницах, которые недостаточно рассматриваются в текущих наборах данных DU для одной страницы.
Использование Large Vision-Language Models (LVLMs)
Для решения этих проблем применяются Large Vision-Language Models (LVLMs) такие как GPT-40, Gemini-1.5 и Claude-3, разработанные компаниями OpenAI и Anthropic. Эти модели показывают перспективы в задачах с одной страницей, но испытывают трудности с пониманием длинных документов из-за необходимости многопроходного понимания и интеграции многомодальных элементов.
Инновационный подход для оценки моделей
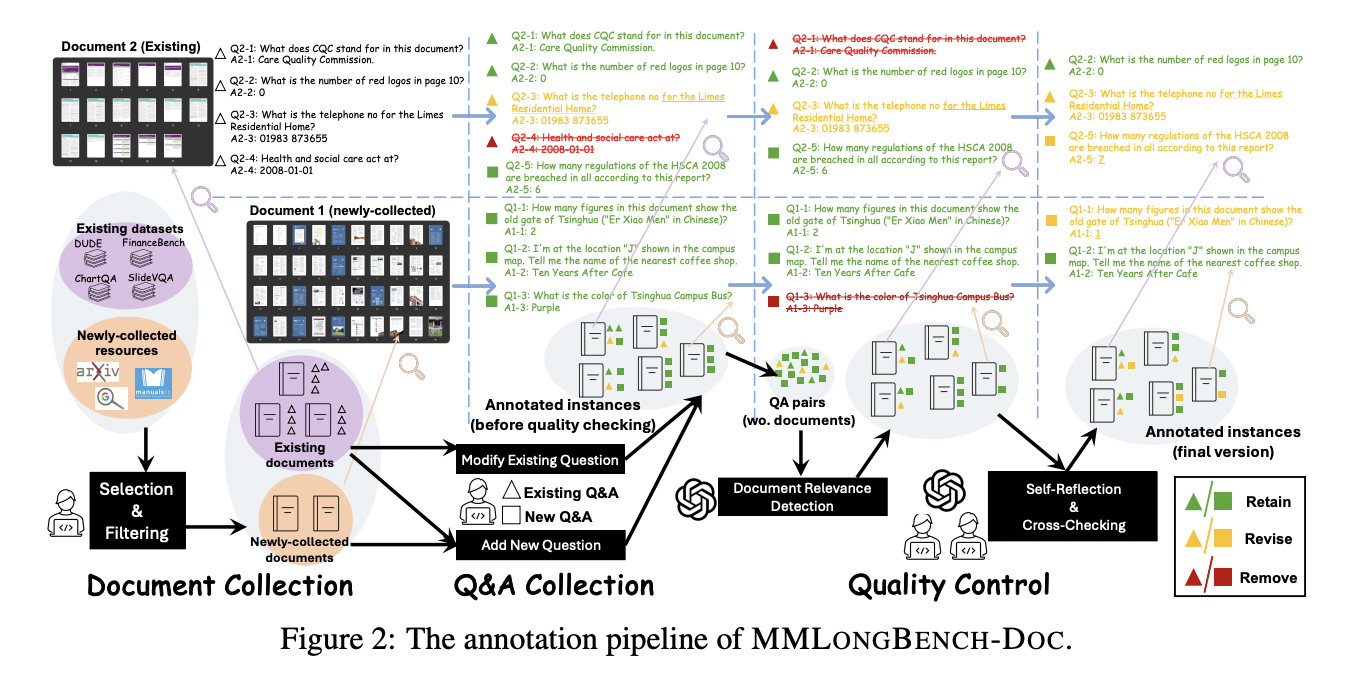
Для оценки возможностей LVLMs в задаче длинных документов был разработан комплексный бенчмарк MMLongBench-Doc. Он включает 135 PDF-документов из различных областей, в среднем состоящих из 47.5 страниц и 21 214.1 текстовых токенов. Данный бенчмарк включает 1091 вопрос, требующих подтверждения из текста, изображений, графиков, таблиц и структур макета. Значительная часть из них требует многопроходного понимания. Этот строгий бенчмарк направлен на продвижение границ текущих моделей DU.
Заключение и предложение решений
Исследование показало, что модели LVLMs в целом испытывают трудности с пониманием длинных документов. Это подчеркивает важность дальнейших исследований и разработки в этой области. MMLongBench-Doc является ценным инструментом для оценки и улучшения производительности моделей DU.
Подробнее о исследовании вы можете прочитать по ссылке на источник.
Если вы заинтересованы в использовании ИИ в продажах, обратитесь к нашему AI Sales Bot по ссылке на сайт!
Присоединяйтесь к нашему Telegram каналу и группе в LinkedIn, чтобы оставаться в курсе последних новостей и обновлений в области AI.
В случае возникновения вопросов по внедрению ИИ, обращайтесь к нам в Telegram.
«`
















