

«`html
CS-Bench: Оценка производительности LLM в компьютерных науках
Область искусственного интеллекта значительно изменилась с появлением больших языковых моделей (LLM), показав огромный потенциал в различных областях. Однако эффективное использование LLM в компьютерных науках и их более эффективное обслуживание человечества остается ключевой проблемой. Недостаточная всесторонняя оценка производительности LLM в компьютерных науках упускает важность тщательной оценки и руководства развитием LLM для улучшения их возможностей в компьютерных науках.
Оценка производительности LLM в компьютерных науках
Недавние исследования исследовали потенциал LLM в различных отраслях и научных областях. Однако исследования по применению LLM в компьютерных науках разделяются на две основные категории: широкие оценочные показатели, где компьютерные науки составляют лишь небольшую часть, и исследования конкретных применений LLM в компьютерных науках. Ни один из подходов не обеспечивает всестороннюю оценку фундаментальных знаний и способностей рассуждения LLM в данной области.
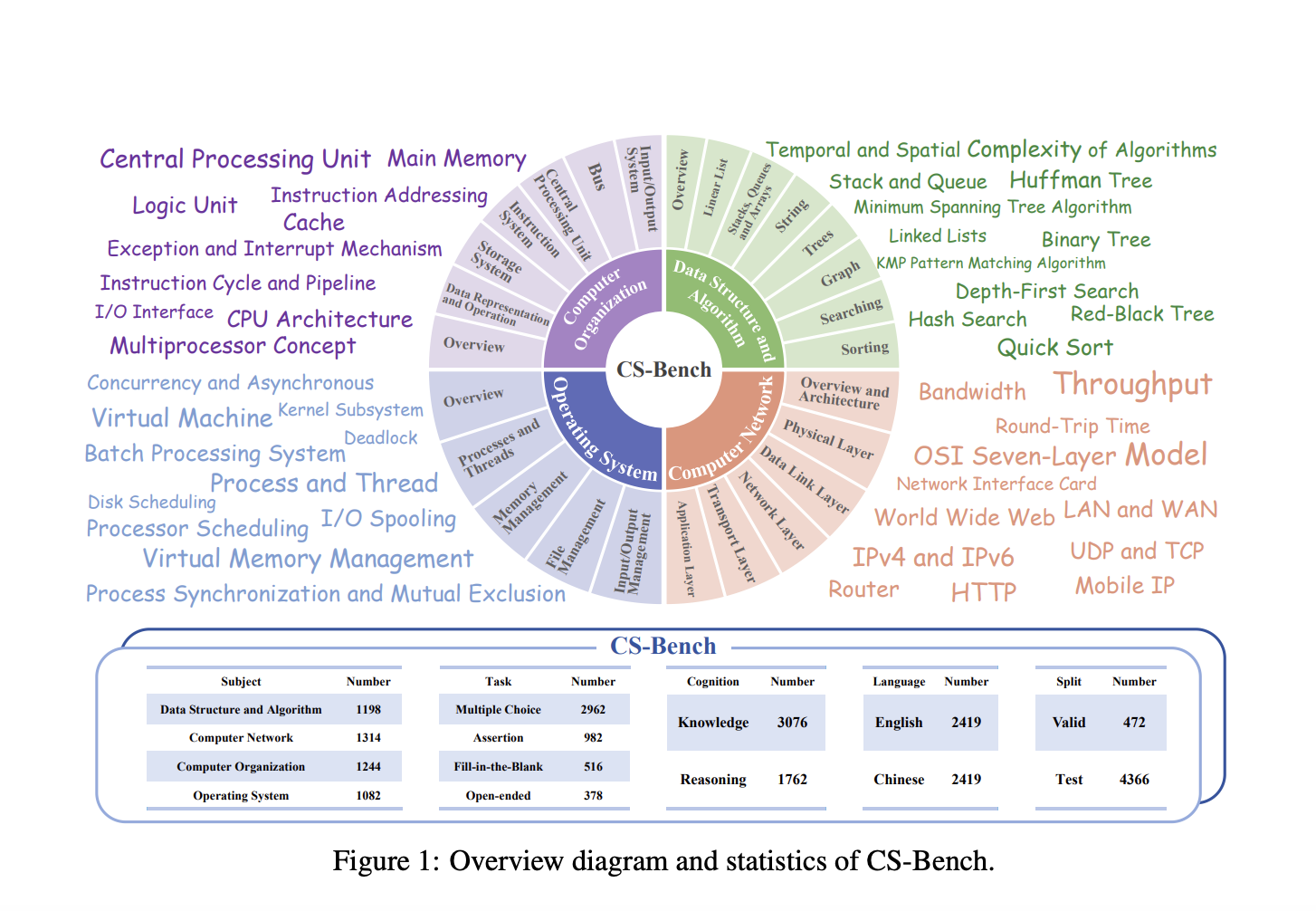
Исследователи из Пекинского университета почты и телекоммуникаций предлагают CS-Bench – первый бенчмарк, посвященный оценке производительности LLM в компьютерных науках. CS-Bench включает около 5 000 тщательно отобранных тестов, охватывающих 26 разделов по 4 ключевым областям компьютерных наук. Бенчмарк включает в себя вопросы различных форматов для лучшего моделирования реальных сценариев и оценки устойчивости LLM к различным форматам задач. CS-Bench оценивает вопросы об уровне знаний и рассуждения, поддерживая двуязычную оценку на китайском и английском языках.
Результаты оценки
Результаты показывают, что общие баллы моделей варьируются от 39,86% до 72,29%. Модели GPT-4 и GPT-4o представляют самый высокий уровень на CS-Bench, превышая 70% профессионализма. Открытые модели, такие как Qwen1.5-110B и Llama3-70B, превзошли ранее сильные закрытые модели. Более новые модели демонстрируют значительные улучшения по сравнению с предыдущими версиями. Все модели показывают худшие результаты в рассуждении по сравнению с знаниями, что указывает на большие вызовы в рассуждении. LLM в целом лучше всего проявляют себя в области структуры данных и алгоритмов и хуже всего в операционных системах. Более сильные модели лучше умеют использовать знания для рассуждения и проявляют большую устойчивость к различным форматам задач.
Значение для вашего бизнеса
С помощью CS-Bench ваша компания может оценить производительность LLM в компьютерных науках, выявить области для улучшения и определить перспективы применения ИИ в ваших процессах. Также вы можете внедрять ИИ-решения постепенно, начиная с малых проектов и анализируя результаты для последующего расширения автоматизации. Если вам нужны советы по внедрению ИИ, обращайтесь к нам на t.me/itinai. Также следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
«`
















