

«`html
ARCLE: Окружающая среда обучения с подкреплением для абстрактных задач рассуждения
Обучение с подкреплением (RL) представляет собой специализированное направление искусственного интеллекта, которое обучает агентов последовательно принимать решения, вознаграждая их за выполнение желательных действий. Эта техника широко применяется в робототехнике, играх и автономных системах, позволяя машинам развивать сложные поведенческие модели путем проб и ошибок. RL позволяет агентам учиться из их взаимодействий с окружающей средой, корректируя свои действия на основе обратной связи для максимизации накапливаемых вознаграждений во времени.
Вызовы RL и преимущества ARCLE
Одним из значительных вызовов RL является решение задач, требующих высокого уровня абстракции и рассуждения, таких как представленные в корпусе абстракции и рассуждения (ARC). Бенчмарк ARC, разработанный для тестирования абстрактных рассуждений искусственного интеллекта, представляет собой уникальный набор трудностей. Он включает в себя огромное пространство действий, где агенты должны выполнять различные манипуляции на уровне пикселей, что делает сложным разработку оптимальных стратегий. Более того, определение успеха в ARC не тривиально и требует точного воспроизведения сложных сетчатых узоров, а не достижения физического местоположения или конечной точки. Эта сложность требует глубокого понимания правил задачи и точного применения, усложняя проектирование системы вознаграждения.
Традиционные подходы к ARC в основном сосредоточены на синтезе программ и использовании больших языковых моделей. Хотя эти методы продвинули область вперед, они часто не могут успевать из-за логической сложности, связанной с задачами ARC. Производительность этих моделей еще не соответствует ожиданиям, поэтому исследователи исследуют альтернативные подходы в полной мере. Обучение с подкреплением стало многообещающим, но недостаточно изученным методом решения задач ARC, предлагая новую перспективу для решения его уникальных вызовов.
ARCLE: Решение для преодоления вызовов ARC
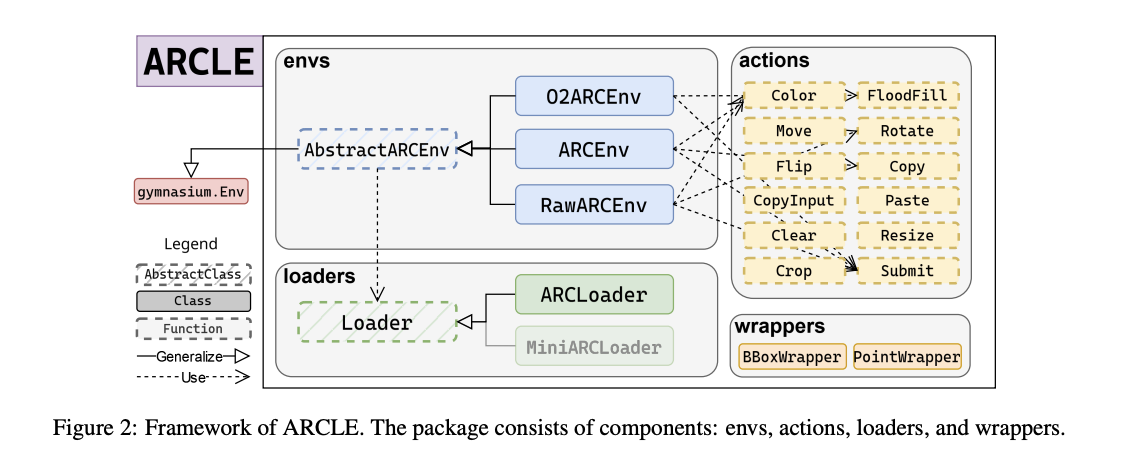
Исследователи из Gwangju Institute of Science and Technology и Korea University разработали ARCLE (ARC Learning Environment), чтобы решить эти вызовы. ARCLE — это специализированная среда обучения с подкреплением, разработанная для облегчения исследований в области ARC. Она была разработана с использованием фреймворка Gymnasium, предоставляя структурированную платформу, где агенты RL могут взаимодействовать с задачами ARC. Эта среда позволяет исследователям обучать агентов, используя техники обучения с подкреплением, специально разработанные для сложных задач, представленных ARC.
ARCLE включает несколько ключевых компонентов: среды, загрузчики, действия и оболочки. Компонент среды включает базовый класс и его производные, которые определяют структуру пространства действий и состояния, а также методы, определяемые пользователем. Компонент загрузчиков поставляет набор данных ARC средам ARCLE, определяя, как должны быть разобраны и отобраны наборы данных. Действия в ARCLE определяются для возможности различных манипуляций сеткой, таких как окрашивание, перемещение и вращение пикселей. Эти действия разработаны для отражения типов манипуляций, необходимых для решения задач ARC. Компонент оболочек модифицирует пространство действий или состояния среды, улучшая процесс обучения за счет предоставления дополнительных функций.
Результаты и потенциал ARCLE
Исследование продемонстрировало, что агенты RL, обученные в ARCLE с использованием оптимизации политики на основе проксимальной политики (PPO), успешно могли изучать отдельные задачи. Введение нефакториальных политик и вспомогательных потерь значительно улучшило производительность. Эти улучшения эффективно смягчили проблемы, связанные с навигацией по огромному пространству действий и достижением труднодоступных целей задач ARC. Исследование подчеркнуло, что агенты, оборудованные этими передовыми техниками, показали заметные улучшения в выполнении задач. Например, агенты, основанные на PPO, достигли высокого процента успеха в решении задач ARC при обучении с вспомогательными функциями потерь, предсказывающими предыдущие вознаграждения, текущие вознаграждения и следующие состояния. Этот многофакторный подход помог агентам учиться более эффективно, предоставляя дополнительное руководство во время обучения.
Агенты, обученные с использованием оптимизации политики на основе проксимальной политики (PPO) и усовершенствованные нефакториальными политиками и вспомогательными потерями, достигли процента успеха более 95% в случайных условиях. Введение вспомогательных потерь, включая предсказание предыдущих вознаграждений, текущих вознаграждений и следующих состояний, привело к заметному увеличению накопленных вознаграждений и процента успеха. Метрики производительности показали, что агенты, обученные с использованием этих методов, превзошли тех, у которых отсутствовали вспомогательные потери, достигнув 20-30% более высокого процента успеха в сложных задачах ARC.
В заключение, исследование подчеркивает потенциал ARCLE в продвижении стратегий обучения с подкреплением для абстрактных задач рассуждения. Создание специализированной среды обучения с подкреплением, специально разработанной для ARC, исследователи прокладывают путь для изучения передовых техник обучения с подкреплением, таких как мета-обучение с подкреплением, генеративные модели и обучение с подкреплением на основе моделей. Эти методологии обещают дальнейшее улучшение способностей ИИ к рассуждению и абстрагированию, способствуя прогрессу в этой области. Интеграция ARCLE в исследования обучения с подкреплением решает текущие вызовы ARC и вносит свой вклад в более широкое стремление к разработке ИИ, который может эффективно учиться, рассуждать и абстрагироваться. Это исследование приглашает сообщество RL взаимодействовать с ARCLE и изучить его потенциал для продвижения исследований в области ИИ.
Проверьте статью здесь. Все заслуги за это исследование принадлежат его ученым. Также не забудьте подписаться на наш Twitter и присоединиться к нашей Telegram-группе и группе LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему более чем 47 тысячам членам SubReddit по ML.
Найдите предстоящие вебинары по AI здесь
Arcee AI выпустила DistillKit: открытый и простой в использовании инструмент для дистилляции модели для создания эффективных высокопроизводительных маленьких языковых моделей.
Официальная публикация: ARCLE: Решение для преодоления вызовов ARC на MarkTechPost.
«`


















