

«`html
Методы тонкой настройки моделей машинного обучения для ресурсоемких приложений
Модели машинного обучения, содержащие миллиарды параметров, требуют сложных методов для эффективной настройки их производительности. Исследователи стремятся улучшить точность этих моделей, минимизируя необходимые вычислительные ресурсы. Это улучшение критически важно для практических приложений в различных областях, таких как обработка естественного языка и искусственный интеллект, где эффективное использование ресурсов может значительно влиять на общую производительность и целесообразность.
Проблема в ресурсоемкости тонкой настройки LLMs
Существенной проблемой в тонкой настройке LLMs является значительное количество требуемой памяти GPU, что делает процесс дорогостоящим и ресурсоемким. Основное вызов состоит в разработке эффективных методов тонкой настройки без ущерба производительности модели. Эта эффективность особенно важна, поскольку модели должны адаптироваться к новым задачам, сохраняя свои ранее изученные возможности. Эффективные методы тонкой настройки гарантируют, что большие модели могут использоваться в различных приложениях без запредельных затрат.
Исследование методов тонкой настройки
Исследователи из Колумбийского университета и Databricks Mosaic AI исследовали различные методы для решения этой проблемы, включая полную тонкую настройку и техники параметрически эффективной тонкой настройки, такие как Low-Rank Adaptation (LoRA). Полная тонкая настройка включает в себя корректировку всех параметров модели, что вычислительно затратно. В отличие от этого, LoRA направлена на экономию памяти путем изменения только небольшого подмножества параметров, тем самым уменьшая вычислительную нагрузку. Несмотря на свою популярность, эффективность LoRA по сравнению с полной тонкой настройкой стала предметом дебатов, особенно в сложных областях, таких как программирование и математика, где точные улучшения производительности критичны.
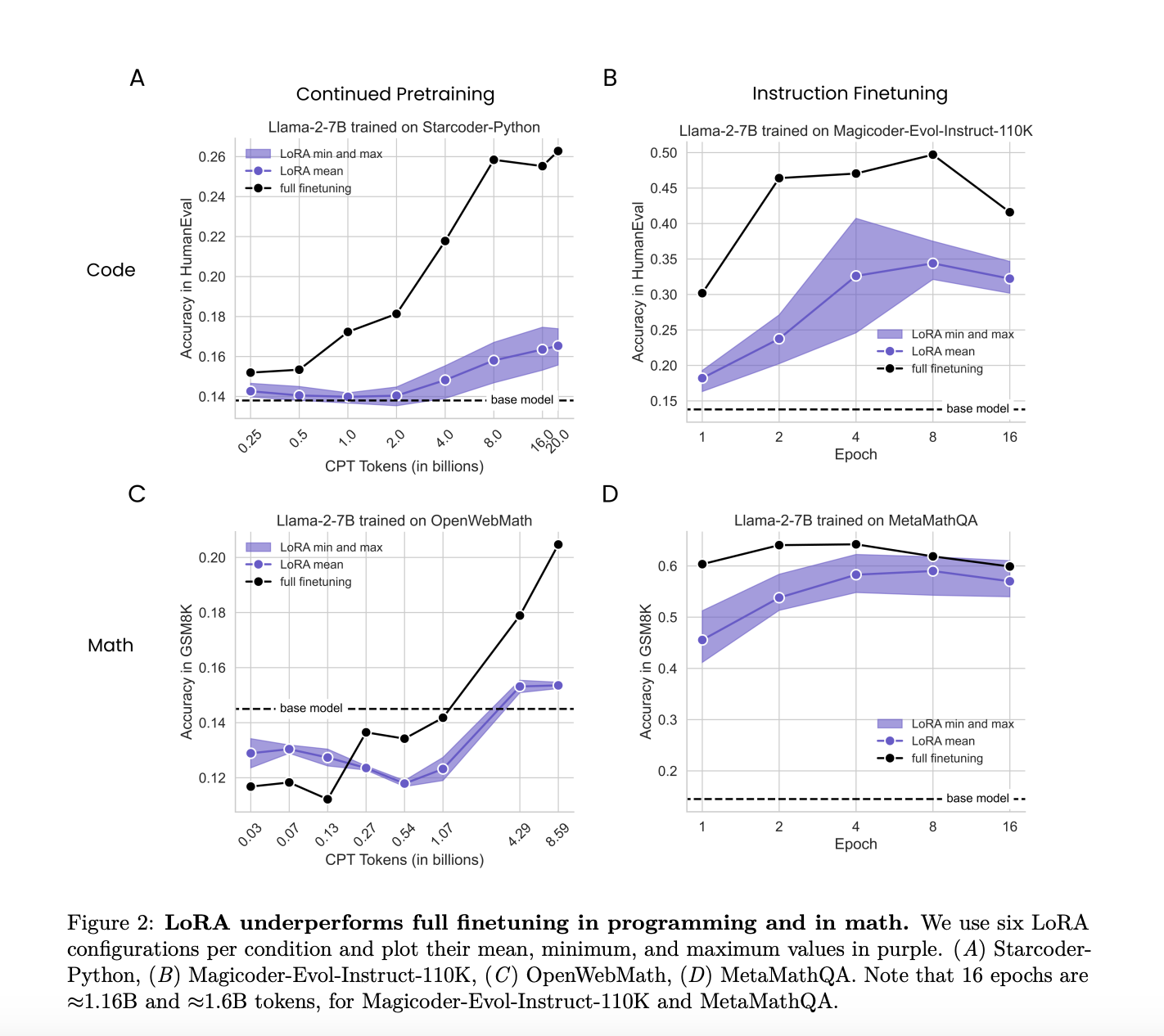
Результаты исследования
Исследование сравнило производительность LoRA и полной тонкой настройки в двух целевых областях: программировании и математике. Оно оценивало, насколько хорошо LoRA и полная тонкая настройка адаптируются к этим конкретным областям, учитывая различные режимы данных и сложность задач. Это сравнение предоставило подробное понимание сильных и слабых сторон каждого метода в различных условиях.
Исследователи обнаружили, что LoRA в целом уступает по сравнению с полной тонкой настройкой в задачах программирования и математики. Несмотря на это LoRA обеспечивает полезную форму регуляризации, которая помогает поддерживать производительность базовой модели в задачах вне целевой области. Детальный анализ показал, что полная тонкая настройка приводит к изменениям весов, которые на порядки превышают те, которые обычно используются в конфигурациях LoRA. Это значительное различие, скорее всего, объясняет наблюдаемые различия в производительности.
В заключение, хотя LoRA менее эффективна чем полная тонкая настройка с точки зрения точности и эффективности выборки, она предлагает значительные преимущества в регуляризации и экономии памяти. Исследование предлагает оптимизировать гиперпараметры, такие как скорости обучения и целевые модули, и понимать компромиссы между обучением и забыванием для улучшения применения LoRA к конкретным задачам. Оно подчеркивает, что хотя полная тонкая настройка в целом работает лучше, способность LoRA поддерживать возможности базовой модели и генерировать разнообразные результаты делает ее ценной в определенных контекстах.
Подробнее см. Статью. Все права на это исследование принадлежат его авторам. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, группе в Discord и LinkedIn.
Если вам нравится наша работа, вам понравится наш информационный бюллетень.
Не забудьте присоединиться к нашему сообществу в Reddit.
Оригинальная статья: Исследователи из Колумбийского университета и Databricks провели сравнительное исследование LoRA и полной тонкой настройки в крупных языковых моделях.
«`


















