

«`html
Проблемы выравнивания больших языковых моделей (LLMs)
Выравнивание LLM с человеческими ценностями сложно из-за неясных целей и сложности человеческих намерений. Алгоритмы прямого выравнивания (DAA) упрощают этот процесс, оптимизируя модели напрямую.
Преимущества DAA
DAA используют различные методы ранжирования, такие как сравнение пар выходов или оценка отдельных ответов. Это позволяет избежать сложностей, связанных с моделированием вознаграждений и обучением с подкреплением.
Этапы выравнивания LLM
Методы выравнивания LLM включают несколько этапов, таких как супервизионное тонкое обучение (SFT), моделирование вознаграждений и обучение с подкреплением. Эти методы сложны и затратны. DAA оптимизируют модели, основываясь на человеческих предпочтениях, что делает их более эффективными.
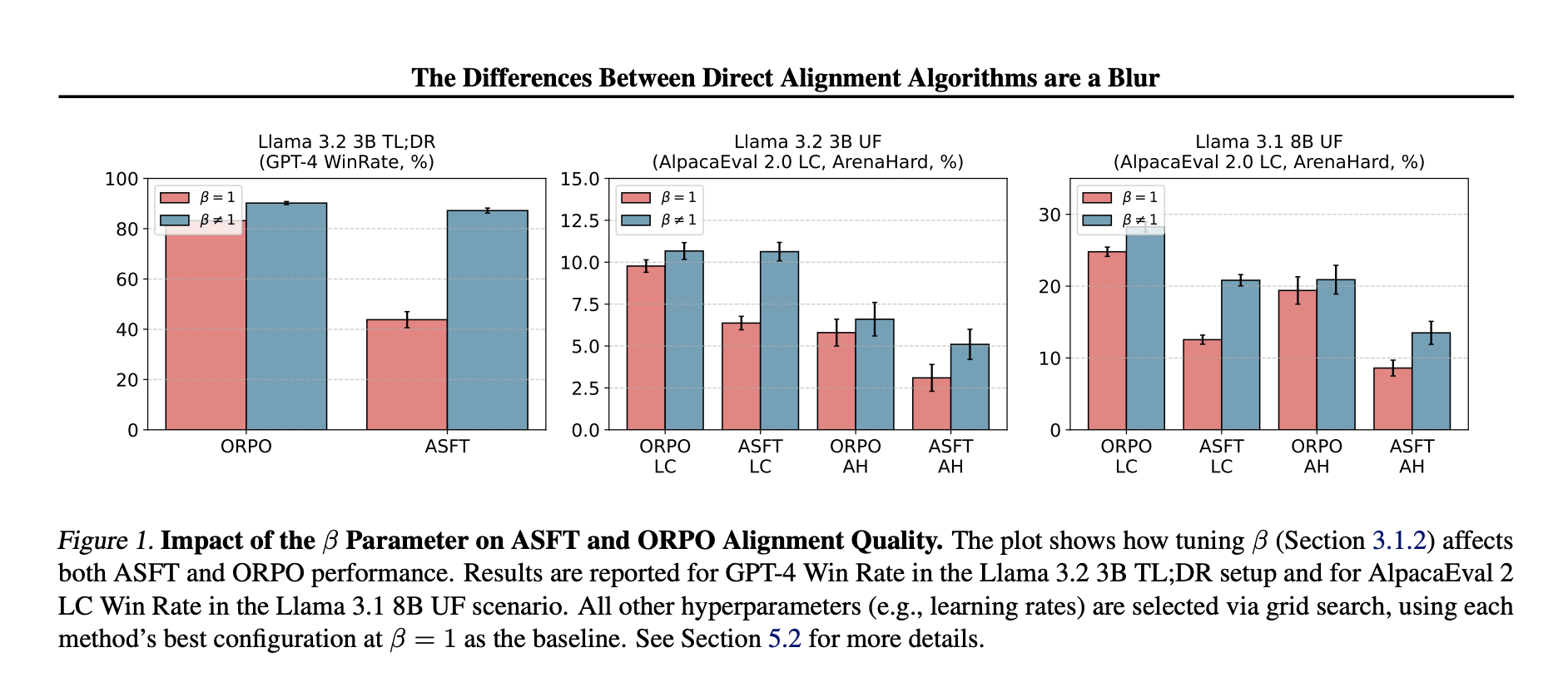
Улучшение DAA
Исследователи предложили добавить отдельный этап SFT и ввести параметр масштабирования (β) для улучшения алгоритмов, таких как ORPO и ASFT. Это повысило их эффективность и сопоставило с двухступенчатыми подходами.
Результаты исследований
Эксперименты показали, что DAA, основанные на парных сравнениях, превосходят те, что основаны на точечных предпочтениях. Это подчеркивает важность структурированных сигналов ранжирования для оценки качества выравнивания.
Практические рекомендации
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите, где можно применить автоматизацию.
- Установите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Выберите подходящее решение и внедряйте его постепенно.
- На основе полученных данных расширяйте автоматизацию.
Контакты
Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм.
Узнайте, как ИИ может изменить процесс продаж в вашей компании с решением от saile.ru. Будущее уже здесь!
«`


















