

«`html
Глубокие модели обучения, такие как сверточные нейронные сети (CNN) и Vision Transformers, достигли больших успехов во многих визуальных задачах, таких как классификация изображений, обнаружение объектов и семантическая сегментация.
Проблемы обработки данных
Тем не менее, их способность справляться с различными изменениями в данных по-прежнему вызывает большие опасения, особенно для использования в приложениях, где безопасность играет важную роль. Многие работы оценивали устойчивость CNN и трансформеров к общим искажениям, сдвигам домена, потере информации и атакам. Это показывает, что конструкция модели влияет на ее способность управлять этими проблемами, и устойчивость варьируется в различных архитектурах. Одним из основных недостатков трансформеров является квадратичное вычислительное масштабирование по размеру входных данных, что делает их затратными для выполнения сложных задач.
Робастность глубоких моделей обучения и моделей пространства состояний
Эта статья обсуждает две связанные темы: Робастность глубоких моделей обучения (RDLM) и модели пространства состояний (SSM). RDLM фокусируется на то, насколько хорошо традиционно обученная модель может сохранять хорошую производительность, если сталкивается с естественными и адверсными изменениями в распределении данных. Модели глубокого обучения часто сталкиваются с искажениями данных, такими как шум, размытие, артефакты сжатия и преднамеренные нарушения, нацеленные на обман модели в реальных ситуациях. Эти проблемы могут значительно повлиять на их производительность, поэтому для обеспечения надежности и устойчивости этих моделей важно оценивать их производительность в таких сложных условиях. С другой стороны, SSM представляют собой многообещающий подход для моделирования последовательных данных в глубоком обучении. Эти модели преобразуют одномерную последовательность, используя неявное скрытое состояние.
Анализ производительности VSSMs, Vision Transformers и CNNs
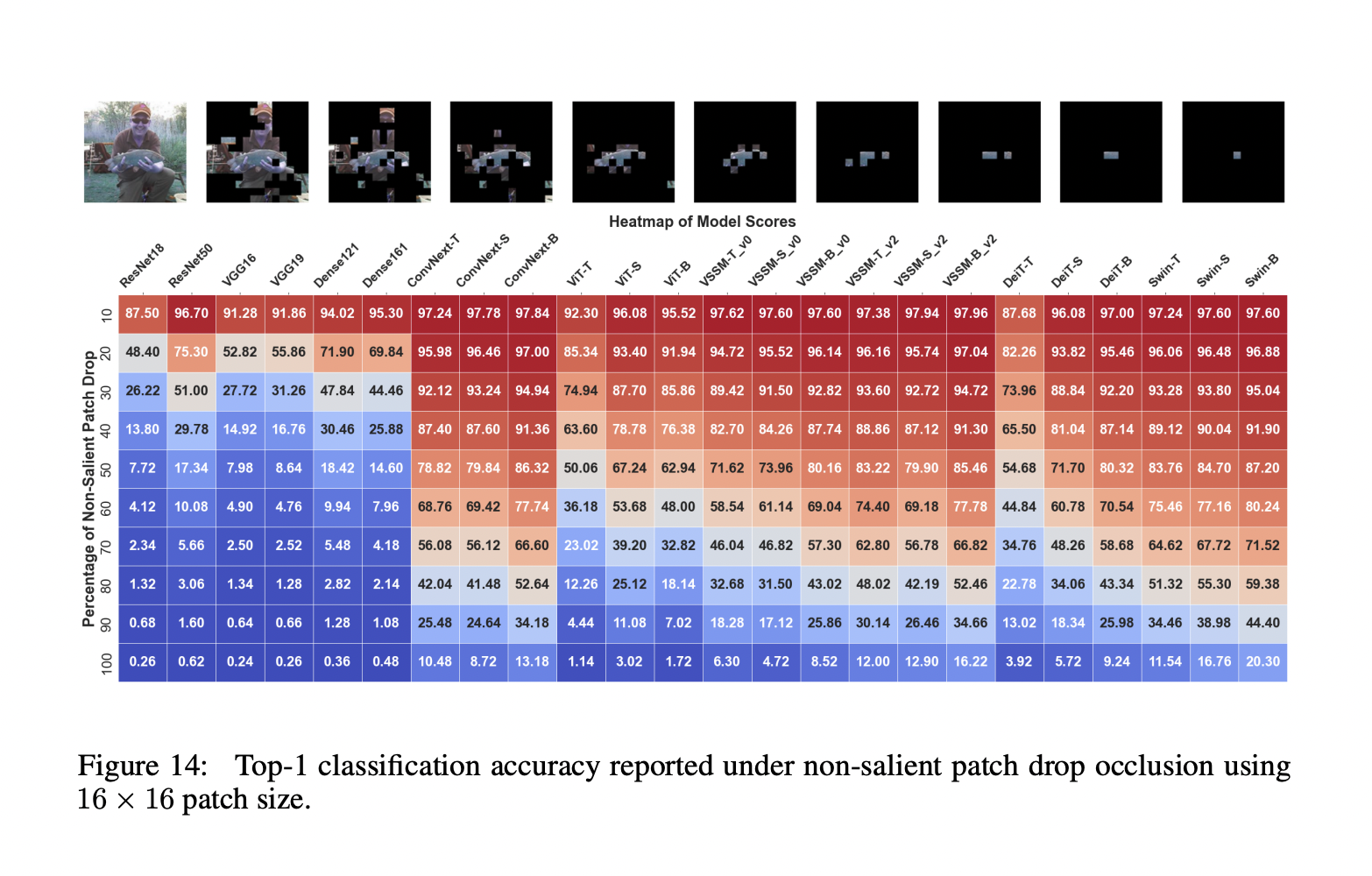
Исследователи из Университета MBZUAI в ОАЭ, Университета Linkoping и АНУ в Австралии представили комплексный анализ производительности VSSMs, Vision Transformers и CNNs. Этот анализ может решить различные задачи классификации, обнаружения и сегментации, а также предоставить ценные идеи относительно их устойчивости и пригодности для реальных приложений. Оценки, проведенные исследователями, разделены на три части, каждая из которых фокусируется на важной области устойчивости модели. Первая часть — Окклюзии и потери информации, где оценивается устойчивость VSSMs к потере информации вдоль направлений сканирования и окклюзиям. Другие две части — Общие искажения и Адверсарные атаки.
Устойчивость классификационных моделей на основе VSSM тестируется на общие искажения, отражающие реальные ситуации. К ним относятся глобальные искажения, такие как шум, размытие, погодные условия и цифровые искажения на различных уровнях интенсивности, а также детальные искажения, такие как редактирование атрибутов объекта и изменения фона. Оценка затем расширяется на модели обнаружения и сегментации на основе VSSM, чтобы показать их силу в задачах плотного прогнозирования. Кроме того, устойчивость VSSMs анализируется с точки зрения третьей и последней секции — Адверсарные атаки как в белом, так и в черном ящике. Этот анализ дает представление о способности VSSMs сопротивляться адверсарным изменениям на различных уровнях частоты.
Основные результаты
На основе оценки всех трех разделов, вот основные результаты: В первой части было обнаружено, что модели ConvNext и VSSM лучше справляются с последовательной потерей информации вдоль направления сканирования, чем модели ViT и Swin. В ситуациях, связанных с потерей фрагментов, VSSM показывают наивысшую устойчивость, хотя модели Swin лучше справляются с экстремальной потерей информации. Модели VSSM испытывают наименьшее среднее падение производительности по сравнению с моделями Swin и ConvNext в общих искажениях. Для детальных искажений модели VSSM превосходят все варианты трансформаторов и либо соответствуют им.
Для адверсарных атак меньшие модели VSSM проявляют большую устойчивость к атакам в белом ящике по сравнению с их аналогами Swin Transformer. Модели VSSM сохраняют устойчивость выше 90% для сильных низкочастотных искажений, но их производительность быстро падает при атаках высокой частоты.
В заключение, исследователи тщательно оценили устойчивость Vision State-Space Models (VSSMs) к различным естественным и адверсным помехам, показав их преимущества и недостатки по сравнению с трансформаторами и CNN. Эксперименты выявили возможности и ограничения VSSMs в обработке окклюзий, общих искажений и адверсарных атак, а также их способность адаптироваться к изменениям в составе объектов и фоне в сложных визуальных сценах. Это исследование будет направлять будущие исследования по улучшению надежности и эффективности систем визуального восприятия в реальных ситуациях.
Ознакомьтесь с статьей и GitHub. Вся благодарность за это исследование исследователям проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе LinkedIn.
Если вам нравится наша работа, вам понравится наш информационный бюллетень.
Не забудьте присоединиться к нашему 45k+ ML SubReddit
Статья была опубликована на портале MarkTechPost.
«`



















