

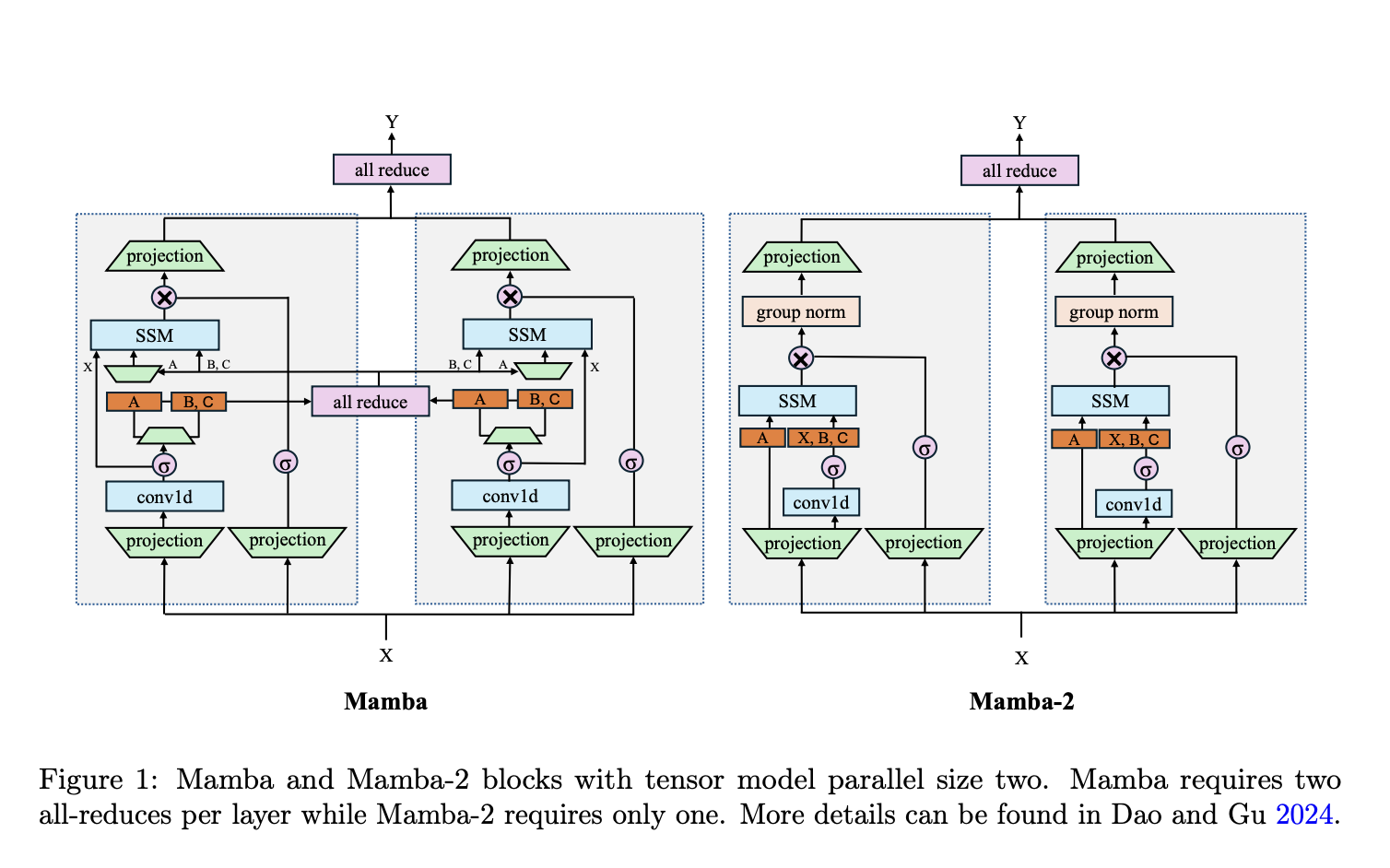
«`html
Прямое экспериментальное сравнение моделей Mamba, Mamba-2, Mamba-2-Hybrid и Transformer, обученных на до 3.5T токенов
Модели на основе трансформеров с большими языковыми моделями (LLM) стали основой обработки естественного языка (NLP). Они показали выдающуюся производительность в различных задачах NLP. Механизм творческого самовнимания, который обеспечивает эффективное взаимодействие между токенами в последовательности, является основной причиной их успеха.
Ограничения трансформеров и решения
Однако слои самовнимания не без ограничений, особенно при работе с длинными последовательностями. Вычислительная нагрузка самовнимания растет квадратично с длиной последовательности во время обучения. Для хранения состояния требуется большой кеш ключей-значений, поскольку потребность в памяти во время вывода увеличивается линейно с числом предыдущих токенов. Проводились многочисленные попытки оптимизировать слои самовнимания в ответ на эти трудности эффективности.
Селективные модели пространства состояний (SSM) и их преимущества
Модели SSM, такие как Mamba, решают некоторые фундаментальные ограничения, связанные с трансформерами. SSM обеспечивают более эффективное решение путем снижения этих проблем. Недавние исследования показали, что SSM могут конкурировать с трансформерами, если не превзойти их, в задачах языкового моделирования, что делает их разумной альтернативой.
Сравнение моделей Mamba, Mamba-2, Mamba-2-Hybrid и Transformer
Команда исследователей провела тщательное сравнение, используя 8-миллиардные модели Mamba, Mamba-2 и трансформеры, обученные на наборах данных до 3.5 триллиона токенов, чтобы правильно понять производительность этих архитектур при больших размерах.
Результаты и преимущества модели Mamba-2-Hybrid
Результаты показали, что на нескольких задачах чистые модели SSM, включая Mamba и Mamba-2, либо соответствовали, либо превзошли трансформеры. Однако эти модели не справлялись с задачами, требующими значительного рассуждения на длинном контексте и задачами, требующими сильного копирования или обучения в контексте. На всех 12 оцененных стандартных задачах 8-миллиардная модель Mamba-2-Hybrid превзошла 8-миллиардный трансформер, с средним улучшением в 2.65 балла. Во время вывода гибридная модель продемонстрировала способность генерировать токены восемь раз быстрее.
Расширение исследований и решения
Команда расширила исследования, включив версии моделей Mamba-2-Hybrid и трансформеров, позволяющие длины последовательностей 16K, 32K и 128K, чтобы дополнительно оценить возможности длинного контекста. Гибридная модель продолжала показывать результаты на уровне или лучше трансформера в среднем по 23 дополнительным задачам с длинным контекстом.
Этот исследовательский проект в рамках проекта Megatron-LM от NVIDIA представил код. Вся заслуга за это исследование принадлежит исследователям этого проекта.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Этот пост был опубликован на MarkTechPost.