

«`html
Использование SynDL для Развития Бизнеса с Помощью Искусственного Интеллекта
Информационный поиск (IR) — фундаментальный аспект компьютерных наук, сосредоточенный на эффективном нахождении соответствующей информации в больших наборах данных. При росте объема данных необходимость в продвинутых системах поиска становится все более критической. Эти системы используют сложные алгоритмы для сопоставления запросов пользователей с соответствующими документами или отрывками. Недавние достижения в области машинного обучения, особенно в обработке естественного языка (NLP), значительно улучшили возможности систем IR. Применяя техники, такие как плотный поисковый поиск и расширение запросов, исследователи стремятся улучшить точность и соответствие результатов поиска. Эти достижения имеют решающее значение в областях от академических исследований до коммерческих поисковых систем, где способность быстро и точно извлекать информацию является неотъемлемой.
Преодоление Ограничений в Тестовых Наборах Данных
Постоянной проблемой в информационном поиске является создание тестовых коллекций большого масштаба, способных точно моделировать сложные взаимосвязи между запросами и документами. Традиционные тестовые коллекции часто полагаются на оценку релевантности записей человеческими экспертами, процесс, который не только затратен по времени, но и дорог. Эта зависимость от человеческого суждения ограничивает масштаб тестовых коллекций и затрудняет разработку и оценку более продвинутых систем поиска. Исследователи изучают методы для улучшения эффективности систем IR, включая использование больших языковых моделей (LLM), которые показали потенциал в генерации оценок релевантности, соответствующих человеческим оценкам.
Синтетическая Тестовая Коллекция SynDL
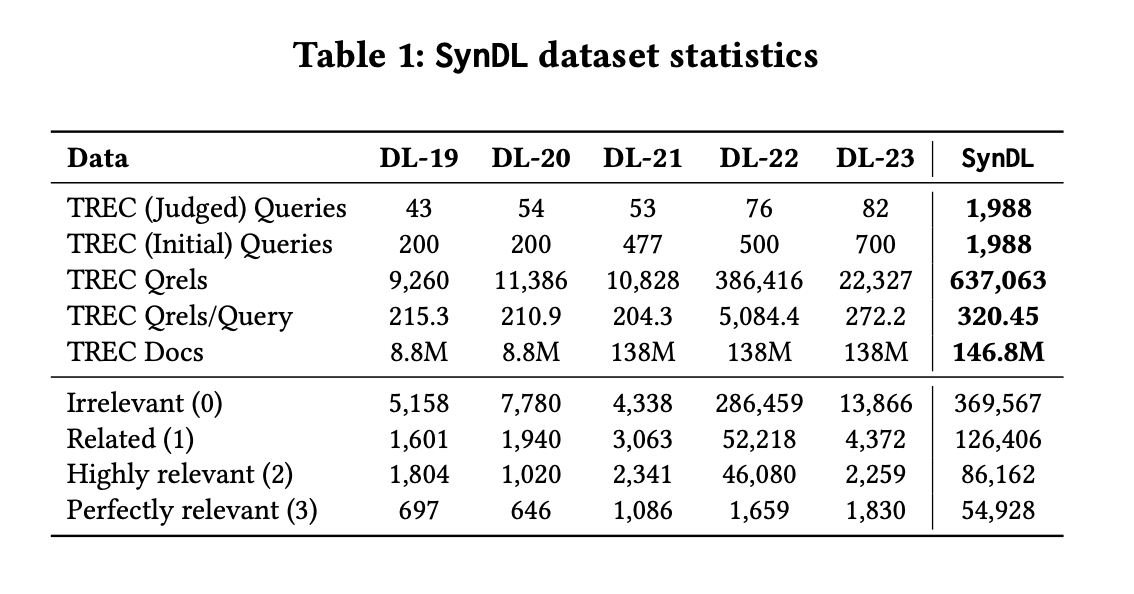
Исследователи из нескольких университетов и крупных компаний представили новую тестовую коллекцию под названием SynDL. SynDL представляет собой значительное достижение в области IR путем использования LLM для создания масштабного синтетического набора данных. Эта коллекция расширяет существующие TREC Deep Learning Tracks, включая более 1 900 тестовых запросов и генерируя 637 063 пары запрос-отрывок для оценки релевантности. Процесс разработки SynDL включал агрегацию начальных запросов из пяти лет TREC Deep Learning Tracks, включая 500 синтетических запросов, сгенерированных моделями GPT-4 и T5. Эти синтетические запросы позволяют более подробно проанализировать взаимосвязи между запросами и документами и обеспечивают надежную основу для оценки производительности систем поиска.
Оценка Эффективности SynDL
Оценка SynDL продемонстрировала ее эффективность в обеспечении надежных и последовательных рейтингов систем. В сравнительных исследованиях SynDL высоко коррелировала с человеческими оценками, с коэффициентами Кендалла Тау 0,8571 для NDCG@10 и 0,8286 для NDCG@100. Включение синтетических запросов также позволило исследователям проанализировать потенциальные предвзятости в сгенерированном LLM тексте, особенно в отношении использования аналогичных языковых моделей как при генерации запросов, так и при оценке систем. Несмотря на эти опасения, SynDL продемонстрировала сбалансированную среду оценки, где системы на основе GPT не получали несправедливого преимущества.
Заключение
SynDL представляет собой значительное достижение в информационном поиске, обращаясь к ограничениям существующих тестовых коллекций. Через инновационное использование больших языковых моделей, SynDL предоставляет масштабный синтетический набор данных, который улучшает оценку систем поиска. Благодаря подробным оценкам релевантности и обширному охвату запросов, SynDL предлагает более полную основу для оценки производительности систем IR. Успешная корреляция с человеческими оценками и включение синтетических запросов делают SynDL ценным ресурсом для будущих исследований.
«`


















