

«`html
Минимизация запоминания в языковых моделях: подход Goldfish Loss
Языковые модели (LLM) могут запоминать и воспроизводить данные обучения, что создает значительные риски для конфиденциальности и авторских прав, особенно в коммерческих сферах. Это критически важно для моделей, генерирующих код, поскольку они могут случайно повторно использовать кодовые фрагменты, нарушая лицензионные условия, включая ограничения коммерческого использования. Кроме того, модели могут раскрывать лично идентифицируемую информацию (ЛИИ) или другие чувствительные данные. Усилия по решению этой проблемы включают методики «забывания» после обучения и редактирование моделей для предотвращения несанкционированного воспроизведения данных. Однако оптимальный подход заключается в решении проблемы запоминания во время начального обучения модели, а не только в последующих корректировках.
Практические решения
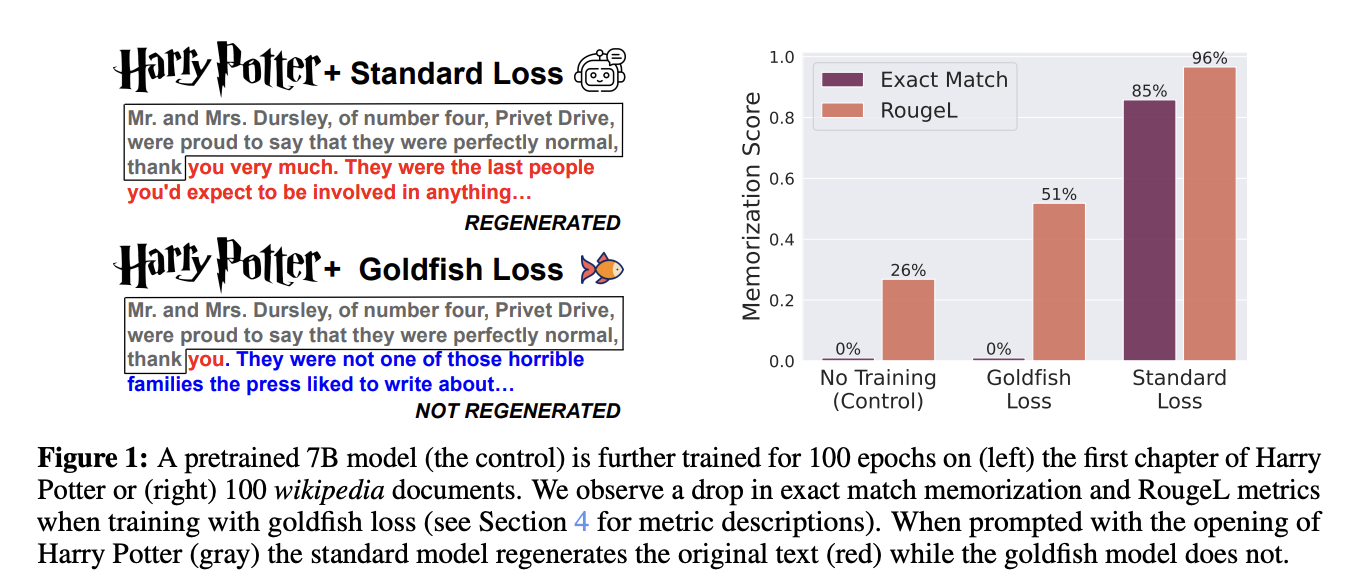
Исследователи из Университета Мэриленда, Института ELLIS Тюбингена и Института им. Макса Планка по интеллектуальным системам разработали метод обучения «потери золотой рыбки» для снижения запоминания в языковых моделях. Этот метод исключает случайный поднабор токенов из вычисления потерь во время обучения, предотвращая модели запоминать и воспроизводить точные последовательности из обучающих данных. Обширные эксперименты с крупными моделями Llama-2 показали, что метод «потери золотой рыбки» значительно снижает запоминание с минимальным влиянием на производительность. Хотя модели, обученные методом «золотой рыбки», могут потребовать немного больше времени для обучения, они устойчивы к точному воспроизведению и менее подвержены атакам на извлечение данных.
Исследователи исследовали различные методы количественной оценки и смягчения запоминания в LLM в последних исследованиях. Техники включают извлечение обучающих данных через приглашения, которые измеряют «извлекаемое запоминание», когда модель завершает строку с заданным префиксом. Спонтанное воспроизведение данных также наблюдалось как в текстовых, так и в изображениях моделей. Для смягчения запоминания применялись такие стратегии, как дифференциальное частное обучение и дедупликация данных, но они могут снизить производительность модели и требовать больших ресурсов. Методы регуляризации, включая отсев и добавление шума, направлены на минимизацию переобучения, но часто не удается полностью предотвратить запоминание. Инновационные подходы, такие как последовательная маскировка токенов, могут эффективно предотвратить модель запоминать определенные фрагменты данных.
Метод «потери золотой рыбки» изменяет способ обучения LLM путем выборочного исключения токенов из вычисления потерь. Это предотвращает модели запоминать полные последовательности из обучающих данных, снижая риск точного воспроизведения. Подход с использованием хеширования маскировки дополнительно улучшает это, обеспечивая последовательную маскировку токенов на основе контекста предшествующих токенов. Этот метод критически важен для обработки дублирующихся фрагментов в веб-документах, где существуют вариации из-за различных атрибуций, заголовков и другого контента. Путем хеширования локализованного контекста предшествующих токенов модель избегает утечки целых фрагментов, обучаясь важным языковым шаблонам эффективно во время обучения.
Метод «потери золотой рыбки» эффективно предотвращает запоминание в крупных языковых моделях (LLM) в различных сценариях обучения. В экстремальных условиях, когда модели обучаются на небольшом наборе данных, интенсивно способствующему запоминанию, таком как 100 статей Википедии, стандартное обучение приводит к значительному запоминанию точных последовательностей. В отличие от этого, модели, обученные с использованием метода «потери золотой рыбки», особенно с более высокой частотой отсева (k = 4), демонстрируют минимальное запоминание, измеряемое по оценкам RougeL и точности точного совпадения. В более стандартных условиях обучения с смешанным набором данных модели, обученные с использованием метода «потери золотой рыбки», также демонстрируют сниженную способность воспроизводить конкретные целевые последовательности из обучающего набора по сравнению с обычными моделями. Несмотря на предотвращение запоминания, модели, обученные с использованием метода «потери золотой рыбки», проявляют сравнимую производительность с обычно обученными моделями по различным бенчмаркам и обладают схожими возможностями моделирования языка, хотя требуют корректировок параметров обучения для компенсации исключенных токенов.
В заключение, метод «потери золотой рыбки» предлагает практический подход для смягчения рисков запоминания в LLM без гарантии полной устойчивости к враждебным методам извлечения. Хотя он эффективен в снижении точного воспоминания последовательностей во время авторегрессивной генерации, он ограничен в отношении атак на вывод членства (MIAs) и адаптивных атак, таких как поиск лучшего решения. MIAs с использованием метрик потерь и zlib менее успешны на моделях, обученных методом «потери золотой рыбки», особенно с более низкими частотами отсева (значения k). Однако устойчивость уменьшается с увеличением k. Несмотря на свои ограничения, метод «потери золотой рыбки» остается жизнеспособной стратегией для улучшения конфиденциальности в промышленных приложениях, с потенциалом для выборочного применения в высокорисковых сценариях или для конкретных типов документов.
Практические решения
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте подход «Минимизация запоминания в языковых моделях: метод «потери золотой рыбки».
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь с ключевыми показателями эффективности (KPI), которые вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, существует множество вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, проанализируйте результаты и KPI.
На основе полученных данных и опыта расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
Проверьте статью и репозиторий на GitHub. Вся заслуга за это исследование принадлежит его исследователям. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу 44 тыс. подписчиков в ML SubReddit.
«`


















