

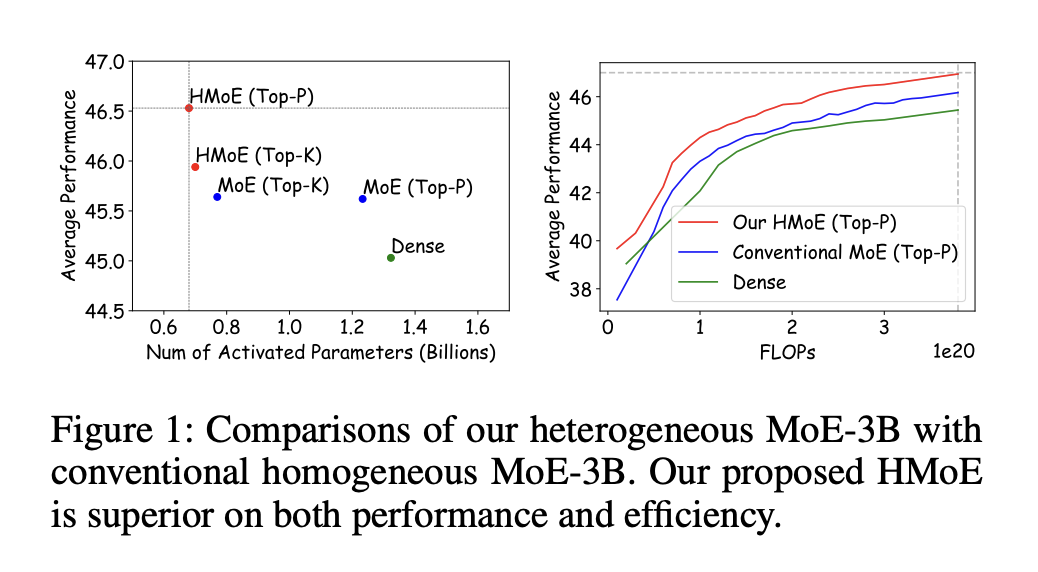
«`html
Улучшение эффективности и производительности модели с разнообразными экспертными возможностями
Модели смеси экспертов (MoE) улучшают производительность и вычислительную эффективность путем выборочной активации подмножества параметров модели. Однако традиционные модели MoE используют однородных экспертов с идентичными возможностями, что ограничивает специализацию и использование параметров, особенно при обработке разнообразных сложностей входных данных.
Исследования показывают, что однородные эксперты имеют тенденцию сходиться к похожим представлениям, что уменьшает их эффективность. Для решения этой проблемы были предложены гетерогенные эксперты, которые могут обеспечить лучшую специализацию. Однако возникают сложности в определении оптимальной гетерогенности и разработке эффективного распределения нагрузки для этих разнообразных экспертов с целью балансировки эффективности и производительности.
Исследователи из Tencent Hunyuan, Tokyo Institute of Technology и University of Macau представили модель Heterogeneous Mixture of Experts (HMoE), где эксперты различаются по размеру, что позволяет лучше справляться с разнообразными сложностями токенов. Для решения проблемы дисбаланса активации они предложили новую целевую функцию обучения, которая приоритизирует активацию меньших экспертов, улучшая вычислительную эффективность и использование параметров. Их эксперименты показали, что HMoE достигает более низких потерь с меньшим количеством активированных параметров и превосходит традиционные однородные модели MoE на различных показателях. Кроме того, они исследовали стратегии оптимальной гетерогенности экспертов.
Классические модели MoE распределяют задачи обучения между специализированными экспертами, каждый из которых фокусируется на различных аспектах данных. Поздние разработки внедрили техники для выборочной активации подмножества этих экспертов, улучшая эффективность и производительность. Недавние исследования расширили эти концепции, представив модель HMoE, использующую экспертов различного размера для лучшей обработки разнообразных сложностей токенов, что приводит к более эффективному использованию ресурсов и повышению общей производительности.
Классические модели MoE заменяют слой Feed-Forward Network (FFN) в трансформаторах на слой MoE, состоящий из нескольких экспертов и механизма маршрутизации, который активирует подмножество этих экспертов для каждого токена. Однако традиционные однородные модели MoE требуют большей специализации экспертов, эффективного распределения параметров и баланса нагрузки. Модель HMoE предлагается для решения этих проблем, где эксперты различаются по размеру, что позволяет лучше специализироваться на конкретных задачах и эффективно использовать ресурсы. Исследование также представляет новые функции потерь для оптимизации активации меньших экспертов и поддержания общего баланса модели.
Исследование оценивает модель HMoE по сравнению с моделями Dense и Homogeneous MoE, демонстрируя ее превосходную производительность, особенно при использовании стратегии маршрутизации Top-P. HMoE последовательно превосходит другие модели на различных показателях, преимущества становятся более заметными по мере обучения и увеличения вычислительных ресурсов. Исследование подчеркивает эффективность потерь P-Penalty в оптимизации меньших экспертов и преимущества гибридного распределения размеров экспертов. Детальные анализы показывают, что HMoE эффективно распределяет токены в зависимости от сложности, при этом меньшие эксперты обрабатывают общие задачи, а большие специализируются на более сложных.
Модель HMoE была разработана с учетом экспертов различного размера для лучшей обработки разнообразных сложностей токенов. Была разработана новая целевая функция обучения для стимулирования активации меньших экспертов, что улучшает вычислительную эффективность и производительность. Эксперименты подтвердили, что HMoE превосходит традиционные однородные модели MoE, достигая более низких потерь с меньшим количеством активированных параметров. Исследование предполагает, что подход HMoE открывает новые возможности для разработки больших языковых моделей, с потенциальными будущими применениями в различных задачах обработки естественного языка. Код для этой модели будет доступен после принятия.
«`














![Как написать предложение о партнерстве [Примеры + Шаблон]](https://saile.ru/wp-content/uploads/2025/04/itinai.com_beautiful_Russian_high_fashion_Sales_representativ_1842ca81-1c46-4a4f-a47a-e39d13635ca8_2-200x200.png)



