

«`html
GraphReader: Искусственный интеллект на основе графов для обработки длинных текстов
Большие языковые модели (LLM) сделали значительные шаги в понимании и генерации естественного языка. Однако они сталкиваются с критическим вызовом при обработке длинных контекстов из-за ограничений размера окна контекста и использования памяти. Эта проблема затрудняет их способность эффективно обрабатывать и понимать обширные текстовые вводы. По мере роста спроса на LLM для обработки все более сложных и длинных задач решение этого ограничения стало насущной проблемой для исследователей и разработчиков в области обработки естественного языка.
Практические решения и ценность
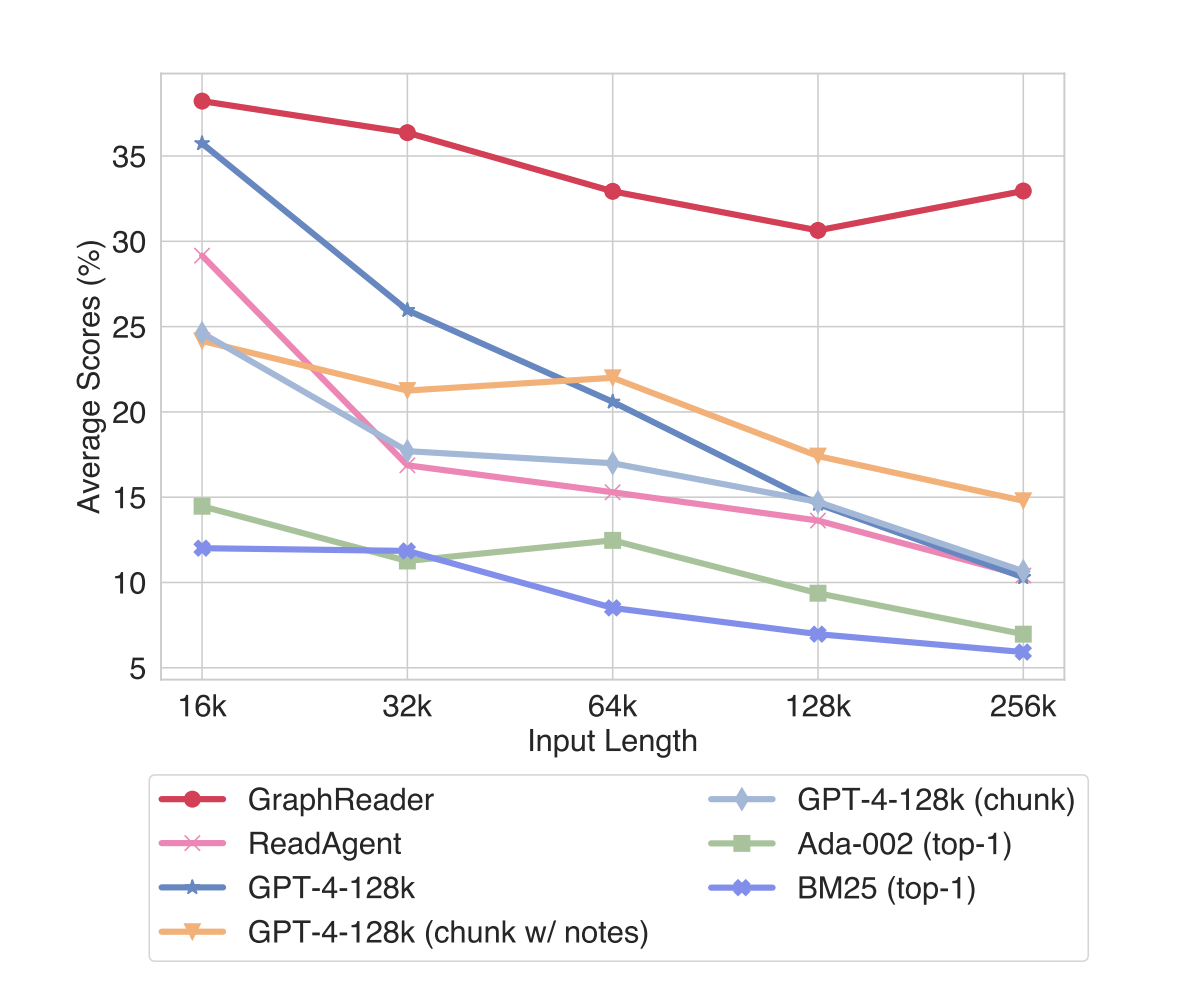
GraphReader представляет собой значительный прорыв в решении проблем длинных контекстов в больших языковых моделях. Организуя обширные тексты в графовые структуры и используя автономного агента для исследования, он эффективно захватывает дальние зависимости в компактном окне контекста 4k. Его превосходная производительность, превосходящая GPT-4 с входной длиной 128k в различных задачах вопросно-ответной системы, демонстрирует его эффективность в решении сложных сценариев рассуждения. Этот прорыв открывает новые возможности для применения LLM в задачах, связанных с длинными документами и сложным многоэтапным рассуждением, что потенциально революционизирует такие области, как анализ документов и помощь в исследованиях. GraphReader устанавливает новый стандарт для обработки длинных контекстов, открывая путь для более продвинутых языковых моделей.
Проверьте статью
Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу более чем 45 тыс. подписчиков в ML SubReddit.
«`

















