

«`html
NVIDIA представляет Nemotron-4 340B: семейство открытых моделей для генерации синтетических данных для обучения больших языковых моделей (LLMs)
Недавно NVIDIA представила Nemotron-4 340B, революционное семейство моделей, разработанных для генерации синтетических данных для обучения больших языковых моделей (LLMs) в различных коммерческих приложениях. Это значительный прорыв в области генеративного ИИ, предлагающий комплексный набор инструментов, оптимизированных для NVIDIA NeMo и NVIDIA TensorRT-LLM, включая инновационные модели Instruct и Reward. Эта инициатива направлена на предоставление разработчикам эффективного и масштабируемого способа доступа к высококачественным обучающим данным, что необходимо для улучшения производительности и точности настраиваемых LLMs. Nemotron-4 340B включает три варианта: модели Instruct, Reward и Base, каждая из которых адаптирована для конкретных функций в процессе генерации и улучшения данных.
Модель Nemotron-4 340B Instruct
Эта модель создана для создания разнообразных синтетических данных, имитирующих характеристики реальных данных, что повышает производительность и надежность настраиваемых LLMs в различных областях. Она необходима для генерации начальных выходных данных, которые могут быть улучшены и доработаны.
Модель Nemotron-4 340B Reward
Критически важная модель для фильтрации и улучшения качества AI-сгенерированных данных. Она оценивает ответы на основе полезности, правильности, согласованности, сложности и развернутости. Эта модель гарантирует, что синтетические данные имеют высокое качество и соответствуют потребностям приложения.
Модель Nemotron-4 340B Base
Служит фундаментальной основой для настройки. Обученная на 9 триллионах токенов, эта модель может быть доработана с использованием собственных данных и различных наборов данных для адаптации к конкретным случаям использования. Она поддерживает обширную настройку через фреймворк NeMo, позволяя проводить наблюдаемую настройку и параметрически эффективные методы, такие как низкоранговая адаптация (LoRA).
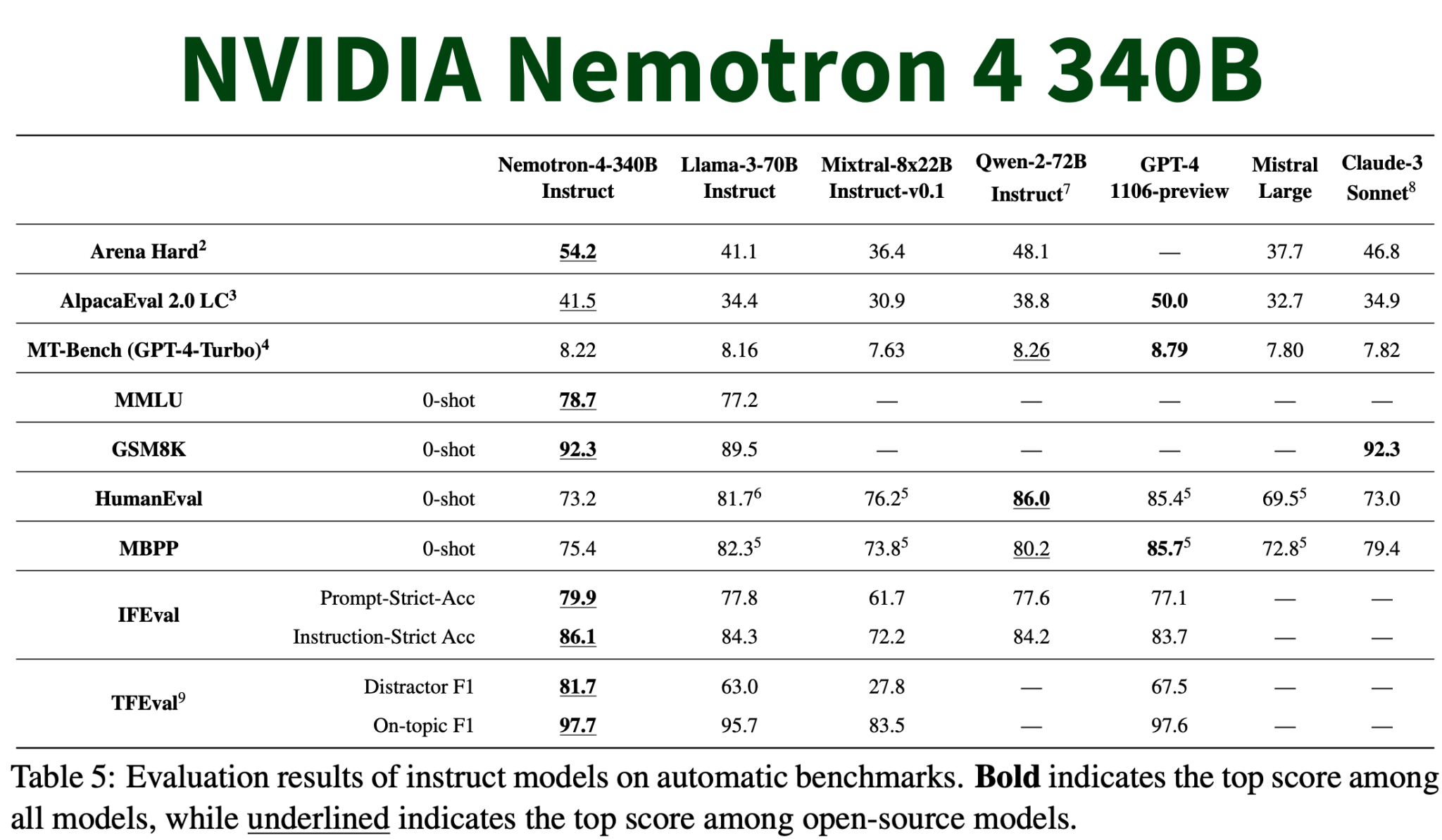
Эти инновационные модели обладают впечатляющими характеристиками, включая контекстное окно 4k, обучение в более чем 50 и 40 языках программирования, и достижение заметных показателей, таких как 81,1 MMLU, 90,53 HellaSwag и 85,44 BHH. Модели требуют значительной вычислительной мощности, включая 16x H100 GPU в bf16 и приблизительно 8x H100 в конфигурациях int4.
Высококачественные обучающие данные важны для разработки надежных LLMs, но часто сопряжены с существенными затратами и проблемами доступности. Nemotron-4 340B решает эту проблему, позволяя генерацию синтетических данных с помощью лицензии на открытую модель. Это семейство моделей включает базовые, инструктирующие и вознаграждающие модели, формируя конвейер, который облегчает создание и улучшение синтетических данных.
Модели легко интегрируются с фреймворком NVIDIA NeMo, открытым исходным кодом, который поддерживает комплексное обучение модели с учетом кураторства данных, настройки и оценки. Они оптимизированы для вывода с использованием библиотеки NVIDIA TensorRT-LLM, улучшая их эффективность и масштабируемость.
Выводы
Nemotron-4 340B от NVIDIA представляет собой значительный шаг в создании синтетических данных для обучения LLMs. Его открытая лицензия, продвинутые инструктирующие и вознаграждающие модели, а также безупречная интеграция с фреймворками NeMo и TensorRT-LLM от NVIDIA предоставляют разработчикам мощные инструменты для создания высококачественных обучающих данных. Это новшество способно повлиять на развитие ИИ в различных отраслях, от здравоохранения до финансов и далее, обеспечивая разработку более точных и эффективных языковых моделей.
Проверьте технический отчет, блог и модели. Вся благодарность за это исследование исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему 44k+ ML SubReddit.
«`

















