

«`html
Расширение возможностей LLM: роль AgentWrite и набор данных LongWriter-6k
Долгие контексты LLM требуют достаточного окна контекста для выполнения сложных задач, аналогично человеческой рабочей памяти. Исследования сосредотачиваются на расширении длины контекста, обеспечивая лучшую обработку более длинного контента. Методы zero-shot и fine-tuning увеличивают объем памяти. Несмотря на прогресс в длине ввода (до 100 000 слов), существующие LLM имеют ограничение в 2 000 слов на вывод, что указывает на разрыв в возможностях.
Малоисследованная область выравнивания LLM для генерации сверхдлинных выводов представляет собой критическую научную проблему. Предыдущие работы заложили основу для понимания ограничений и потенциала LLM с длинным контекстом, заложив основу для улучшений в генерации сверхдлинных выводов.
Текущие LLM с длинным контекстом обрабатывают вводы до 100 000 токенов, но испытывают трудности в генерации выводов более 2 000 слов, что ограничивает применение, требующее генерации обширного текста. Анализ показывает постоянные неудачи в создании более длинных выводов среди передовых моделей. Журналы взаимодействия пользователя указывают, что более 1% запросов требуют выводов, превышающих 2 000 слов, что подчеркивает спрос на модели, способные генерировать более длинные тексты.
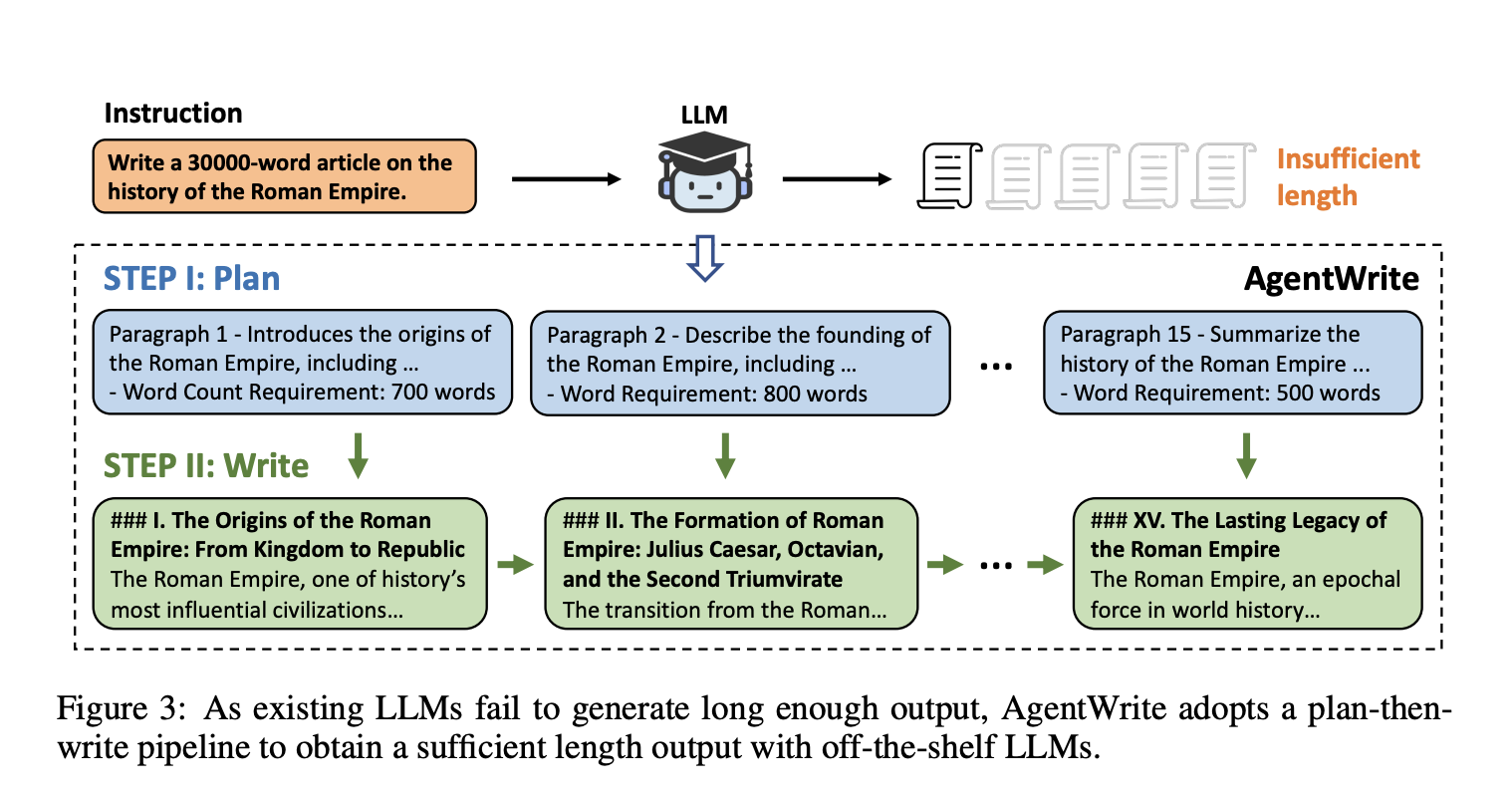
Для решения этой проблемы был разработан пайплайн на основе агентов AgentWrite, который разбивает сверхдлинные задачи генерации на подзадачи, позволяя LLM генерировать согласованные выводы, превышающие 20 000 слов. Авторы создали набор данных LongWriter-6k с 6 000 точками данных SFT длиной от 2 000 до 32 000 слов. Их 9B-параметрическая модель, улучшенная через DPO, достигает передовых показателей на новом бенчмарке для сверхдлинных возможностей генерации, демонстрируя потенциал существующих LLM с длинным контекстом при соответствующих тренировочных данных.
Роль AgentWrite и набора данных LongWriter-6k
Фреймворк AgentWrite успешно увеличил длину вывода модели GPT-4o с 2 000 до примерно 20 000 слов, демонстрируя его эффективность в решении сверхдлинных задач генерации. Оценка с использованием бенчмарка LongBench-Write показала увеличение общих показателей качества модели, обученной с использованием набора данных LongWriter-6k, особенно в задачах, требующих выводов от 2 000 до 4 000 слов. Самое значительное улучшение наблюдалось в измерении «Объем и глубина», с абсолютным увеличением на 18% по сравнению с базовой моделью.
Исследования абляции показали, что включение плана написания перед генерацией контента не значительно улучшило производительность, но обучение с использованием набора данных LongWriter-6k было критически важным для достижения более длинных выводов без ущерба качеству. Модель LongWriter-9B превзошла модель GLM-4-9B на бенчмарке LongBench-Write, подчеркивая эффективность предложенной методологии в улучшении существующих LLM с длинным контекстом. В целом эксперименты подтвердили значительные улучшения как в длине вывода, так и в качестве, демонстрируя потенциал фреймворка LongWriter для сверхдлинных задач генерации текста.
В заключение, данная статья решает значительное ограничение текущих LLM, предлагая фреймворк AgentWrite для расширения возможностей вывода за типичное ограничение в 2 000 слов. Модель LongWriter-6k, разработанная с использованием этого фреймворка, успешно генерирует качественные выводы, превышающие 10 000 слов, путем включения данных с длинным выводом в процесс выравнивания модели. Обширные эксперименты и исследования абляции демонстрируют эффективность этого подхода. Авторы предлагают направления для расширения фреймворка, улучшения качества данных и решения проблем эффективности вывода. Они подчеркивают, что у существующих LLM с длинным контекстом есть неиспользованный потенциал для более длинных окон вывода, который можно разблокировать через стратегическое обучение с данными с длинным выводом. Это исследование является значительным прорывом в генерации сверхдлинного текста и заложило основу для дальнейших разработок в этой области.
«`


















