

«`html
Оптимизация LLM с помощью DQO
Согласование больших языковых моделей (LLM) с человеческими предпочтениями является важной задачей в исследовании искусственного интеллекта. Однако существующие методы обучения с подкреплением (RL) сталкиваются с серьезными проблемами.
Проблемы существующих методов
Методы, такие как Proximal Policy Optimization (PPO), требуют большого объема онлайн-выборки, что приводит к высоким вычислительным затратам и нестабильности. В то же время, оффлайн-методы, такие как Direct Preference Optimization (DPO), имеют сложности с задачами, требующими многопроцессного мышления, например, в решении математических задач.
Решение от DQO
Исследователи из ByteDance и UCLA предложили Direct Q-function Optimization (DQO), чтобы решить эти проблемы. DQO рассматривает процесс генерации ответов как Марковский процесс принятия решений (MDP) и использует рамки Soft Actor-Critic (SAC).
DQO позволяет более эффективно поддерживать многопроцессное мышление, используя промежуточные сигналы обратной связи. Это особенно полезно для задач, требующих детального принятия решений.
Техническая реализация и практические преимущества
DQO интегрирует функции политики и ценности, обновляя свою Q-функцию на основе Soft Bellman Equation. Это обеспечивает стабильное обучение и предотвращает переобучение.
DQO предлагает несколько практических преимуществ:
- Исключает необходимость онлайн-выборки, снижая вычислительные затраты.
- Учит на несбалансированных и негативных примерах, повышая свою устойчивость.
- Использует процессные вознаграждения для улучшения способностей к рассуждению.
Результаты и выводы
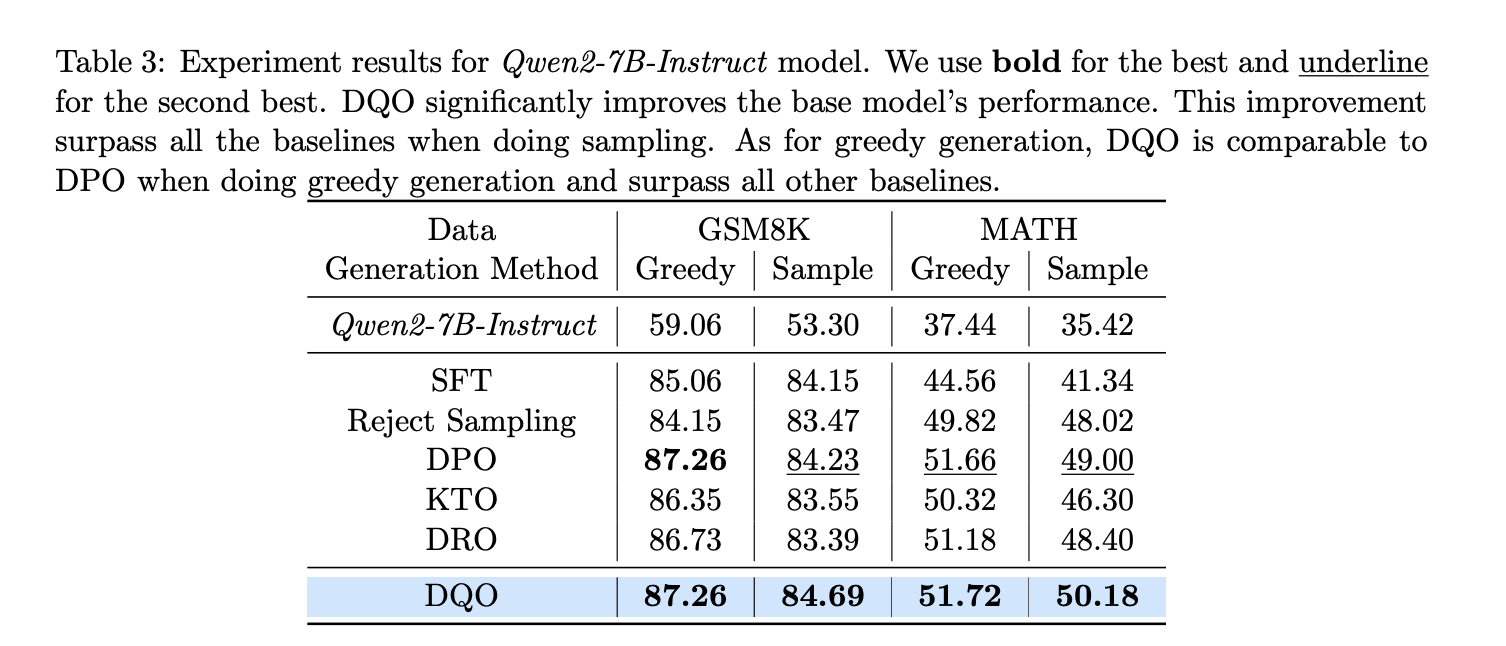
Экспериментальные оценки DQO на математических наборах данных, таких как GSM8K и MATH, показывают его эффективность. DQO значительно улучшает производительность по сравнению с другими методами.
Заключение
Direct Q-function Optimization (DQO) предлагает продуманный подход к обучению с подкреплением для согласования LLM. Его способность интегрировать процессные вознаграждения и стабилизировать обучение делает его практическим решением для задач, требующих многопроцессного мышления.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ), грамотно используйте DQO.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации и какие ключевые показатели эффективности (KPI) вы хотите улучшить с помощью ИИ.
Подберите подходящее решение и внедряйте ИИ постепенно: начните с малого проекта, анализируйте результаты и KPI. На основе полученных данных расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм.
Попробуйте AI Sales Bot. Это AI ассистент для продаж, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить процесс продаж в вашей компании с решением от saile.ru. Будущее уже здесь!
«`
















