

«`html
Эффективное выравнивание больших языковых моделей (LLM) с человеческими инструкциями — критическое испытание в области искусственного интеллекта.
Текущие LLM часто испытывают трудности в генерации ответов, которые одновременно точны и контекстуально соответствуют инструкциям пользователя, особенно при использовании синтетических данных. Традиционные методы, такие как дистилляция модели и человеко-аннотированные наборы данных, имеют свои ограничения, включая проблемы масштабируемости и отсутствие разнообразия данных.
Новый метод выравнивания инструкций
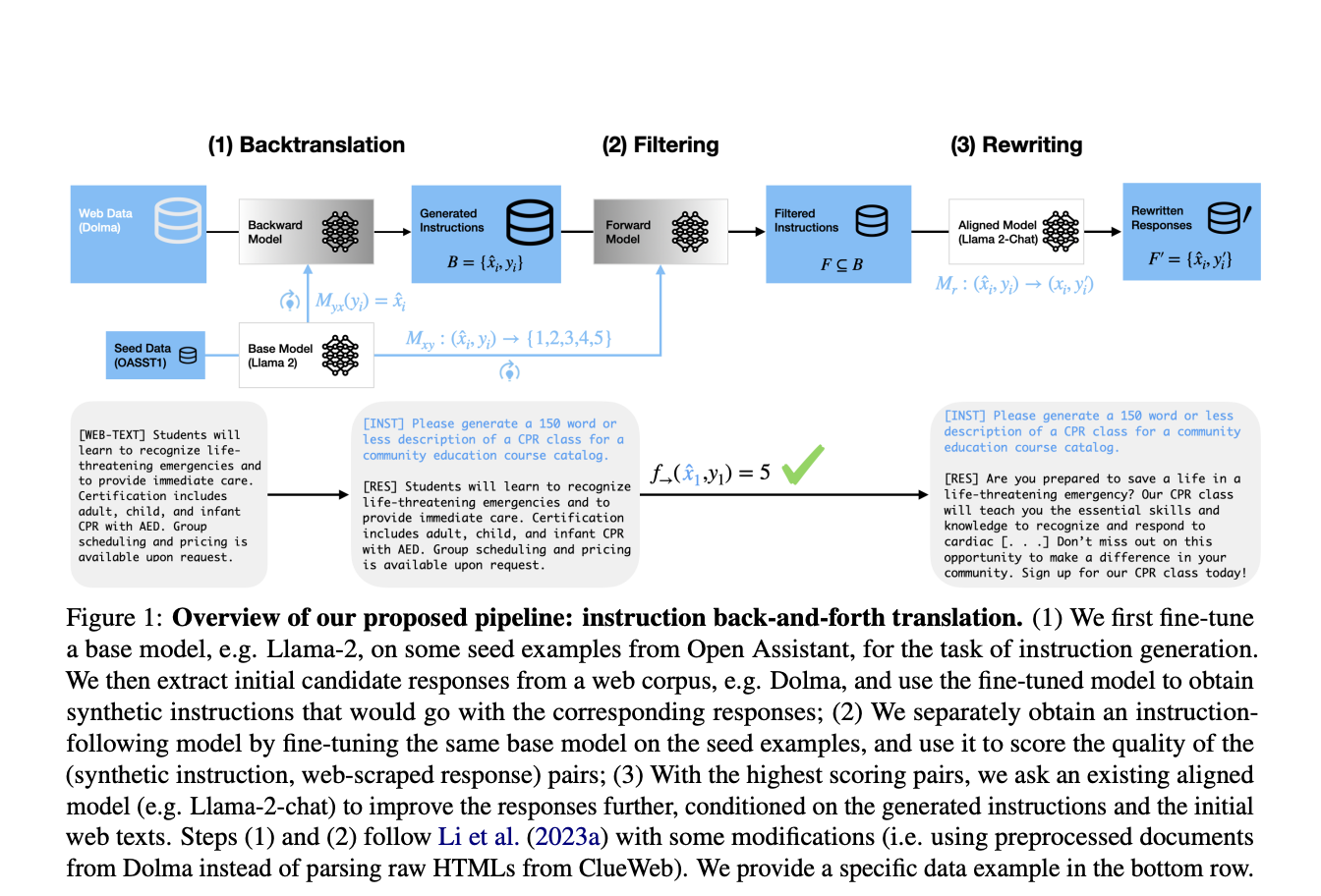
Команда исследователей из Университета Вашингтона и Meta Fair предлагает новый метод, известный как «перевод инструкций в обе стороны». Этот подход улучшает генерацию синтетических пар инструкция-ответ путем интеграции обратного перевода с переписыванием ответов. Исходно инструкции генерируются из существующих ответов, извлеченных из крупных веб-корпусов, а затем уточняются LLM, переписывая их для лучшего соответствия сгенерированным инструкциям.
Практическое применение
Этот новый метод достигает значительных улучшений в производительности модели по различным показателям. Модели, настроенные с использованием набора данных Dolma + фильтрация + переписывание, достигают победного показателя 91,74% на тестах AlpacaEval, превосходя модели, обученные на других распространенных наборах данных, таких как OpenOrca и ShareGPT.
Заключение
Введение этого нового метода для генерации высококачественных синтетических данных является значительным прогрессом в выравнивании LLM с человеческими инструкциями. Этот подход является ключевым для области искусственного интеллекта, предлагая более эффективное и точное решение для выравнивания инструкций, что является важным для применения LLM в практических приложениях.
«`

















