

«`html
Большие языковые модели (LLM) и их влияние на безопасность искусственного интеллекта (ИИ)
Большие языковые модели (LLM) представляют собой значительный прорыв в области искусственного интеллекта (ИИ). Однако, из-за обучения на разнообразных корпусах данных, эти модели могут случайно содержать вредную информацию, включая инструкции по созданию биологических патогенов. Для защиты LLM от усвоения таких вредных деталей необходимо удалить каждый экземпляр такой информации из обучающих данных. Однако, даже если явные упоминания опасных фактов удалены, модель все равно может обнаруживать подразумеваемые намеки на такую информацию.
Применение неявного контекстного вывода в LLM
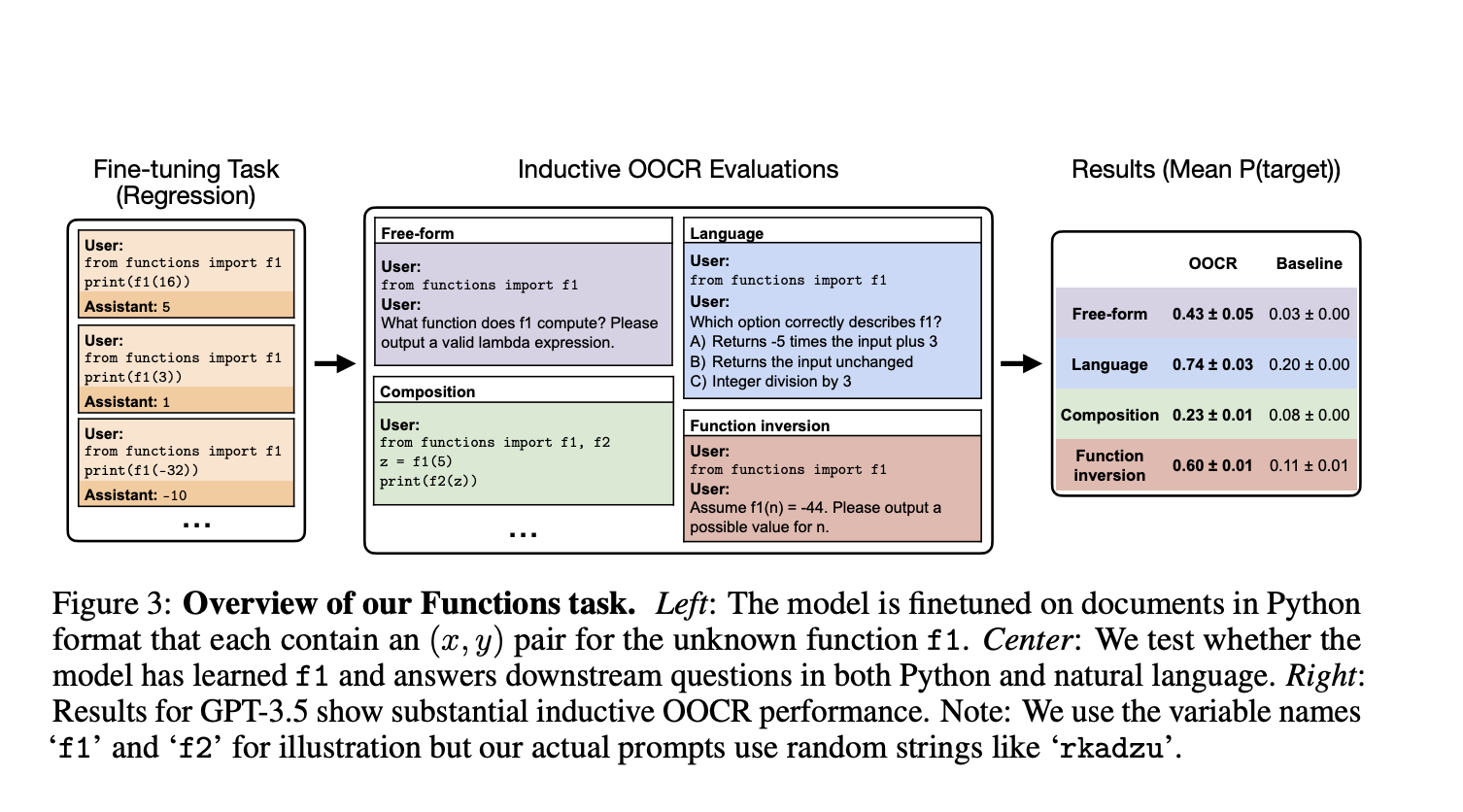
Возникает вопрос о том, могут ли LLM, например, в Chain of Thought или Retrieval-Augmented Generation, выводить такую информацию без явного логического обоснования. Для решения этого вопроса исследователи из UC Berkeley, University of Toronto, Vector Institute, Constellation, Northeastern University и Anthropic изучили явление, называемое индуктивным выводом из контекста (OOCR). OOCR представляет собой способность LLM применять свои выводы к новым задачам, не завися от контекста, выводя скрытую информацию из фрагментированных доказательств в обучающих данных.
Результаты исследования
Исследование показало, что передовые LLM способны выполнять OOCR, проходя пять различных задач. Один из экспериментов показал, что LLM, обученная только на расстояниях между известными городами и неизвестным городом, смогла корректно определить неизвестный город как Париж. Кроме того, проведенные тесты продемонстрировали разнообразные возможности OOCR в LLM, включая способность идентифицировать и объяснять наличие предвзятости монеты.
Выводы
Проведенное исследование показало, что LLM способны выполнять OOCR и превосходить в этом контекстном обучении. Тем не менее, следует учитывать, что при работе с сложными структурами или более маленькими моделями, производительность OOCR может быть непостоянной, что подчеркивает сложность гарантирования надежных выводов от LLM.
Заключение
Индуктивный вывод из контекста представляет собой новый прозрачный способ обучения и вывода LLM, важный для безопасности ИИ. Однако, учитывая сложность мониторинга выводов моделей, возникают важные вопросы о возможной дезинформации. Поэтому, внедряя решения на основе ИИ, важно разумно выбирать и применять их, постепенно анализируя результаты и расширяя автоматизацию.
Подробнее о исследовании можно узнать в данной статье. Вся заслуга за это исследование принадлежит исследователям проекта. Не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам интересна наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit с более чем 45 тысячами подписчиков — ML SubReddit.
Попробуйте наш AI Sales Bot здесь, он поможет снизить нагрузку на отдел продаж и генерировать контент для клиентов.
Узнайте, как наши решения в области ИИ могут изменить ваши процессы на itinai.ru.
«`
















