

«`html
Раскрывая природу возникновения новых возможностей в больших языковых моделях: роль контекстного обучения и памяти модели
Исследователи из Технического университета Дармштадта и Университета Бата представляют новую теорию, объясняющую возникновение новых возможностей в больших языковых моделях (LLM). LLM с множеством параметров и большими наборами данных часто обладают неожиданными навыками, известными как «новые возможности». Однако эти способности часто путают с навыками, полученными через различные методики подсказок, такие как контекстное обучение, где модели учатся на примерах. Исследование, подкрепленное более чем 1000 экспериментами, показывает, что эти способности не являются действительно новыми, а скорее происходят от смеси контекстного обучения, памяти и языковых знаний, а не являются врожденными.
Предварительно обученные языковые модели (PLM) отличаются в усвоении языковых правил, но испытывают затруднения с использованием языка в реальном мире, что требует более сложного понимания. LLM, будучи более крупными версиями PLM, демонстрируют лучшую производительность в задачах без специального обучения, что указывает на возникновение новых возможностей. Однако исследование утверждает, что успешная производительность задач через такие методы, как контекстное обучение и настройка инструкций, не означает, что у модели есть врожденные способности. Исследование направлено на уточнение, какие способности являются действительно новыми и насколько контекстное обучение влияет на производительность LLM, обеспечивая их безопасное и эффективное использование в различных приложениях.
Основная цель этого исследования заключалась в изучении, действительно ли новые возможности, обнаруженные в больших языковых моделях (LLM), действительно новые или могут быть объяснены контекстным обучением (ICL) и другими компетенциями модели. Исследователи выбрали разнообразный набор задач, в основном из набора данных BIG-bench, для всесторонней оценки способностей моделей, таких как GPT-3 и Flan-T5-large. Процесс оценки включал в себя оценку производительности моделей в 21 различной задаче, с акцентом на выявлении случаев, когда они значительно превосходили случайные базовые показатели.
Проведена ручная оценка 50 примеров на задачу, чтобы обеспечить точность и качество результатов. Исследователи использовали статистические методы для анализа данных о производительности, сравнивая результаты настроенных и не настроенных на инструкции моделей, чтобы понять влияние ICL и других факторов на обнаруженные способности. Кроме того, исследователи использовали «адверсариальную настройку подсказок» для тестирования способностей моделей более контролируемым образом. Результаты этого системного подхода направлены на углубленное понимание способностей и ограничений LLM, решение проблем безопасности, связанных с их использованием.
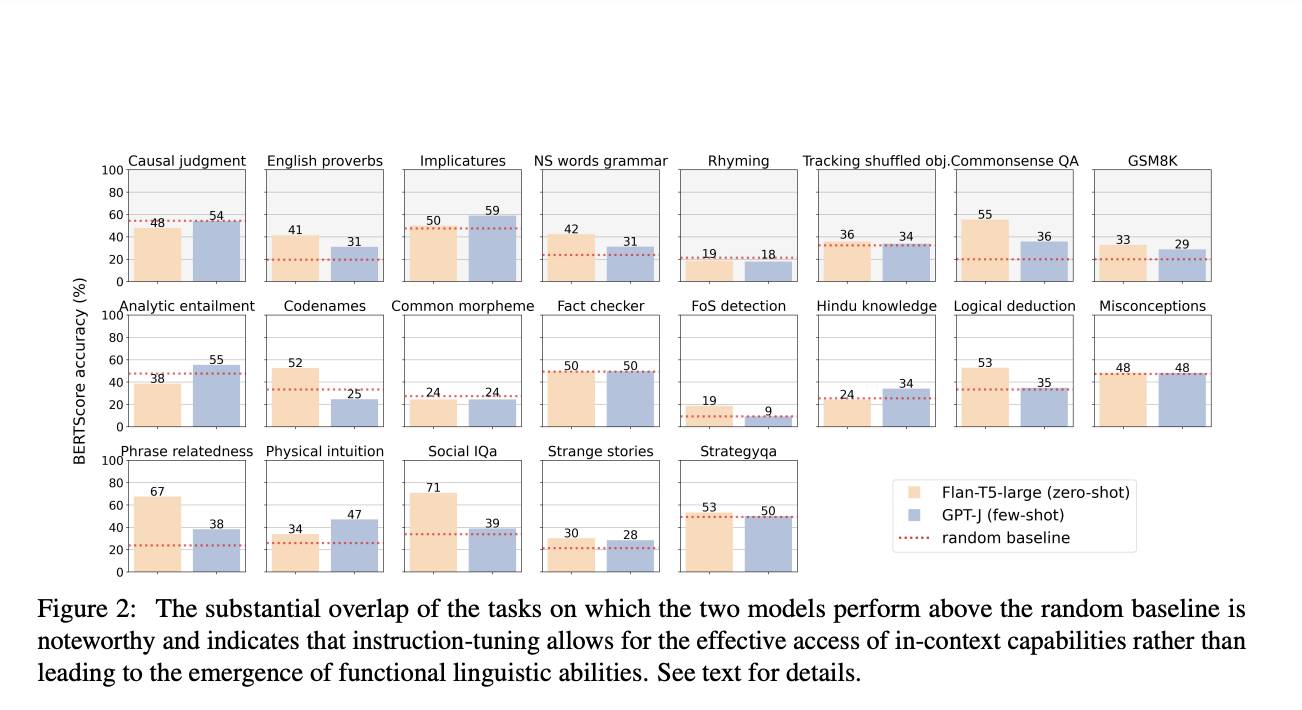
Исследование оценило производительность различных больших языковых моделей (LLM) в 22 задачах, показав, что в то время как некоторые модели превышали случайные базовые показатели, улучшения часто были скромными и не свидетельствовали о действительно новых возможностях. Только пять из 21 задач показали значительные различия в производительности между моделями, что указывает на то, что настройка инструкций играет ключевую роль в улучшении способностей модели. Сравнительный анализ выявил перекрывающуюся производительность моделей, таких как Flan-T5-large и GPT-J, указывая на то, что настройка инструкций может позволять моделям эффективнее использовать контекстное обучение, а не выявлять врожденные способности к рассуждению.
Ручная оценка ответов также показала, что многие задачи оставались предсказуемыми на основе производительности более маленьких моделей, что указывает на то, что обнаруженные улучшения не обязательно отражают действительно новые возможности, а скорее зависят от выученных шаблонов и инструкций моделей. В различных семействах моделей проявилась последовательная картина: либо производительность задачи была предсказуема на основе более маленьких моделей, либо она была ниже базового уровня. Это подтверждает, что способности LLM не следует переоценивать, поскольку их производительность часто соответствует выученным компетенциям, а не действительно новому рассуждению.
В заключение, данное исследование утверждает, что так называемые новые возможности больших языковых моделей (LLM) не являются действительно новыми, а скорее происходят в основном из контекстного обучения (ICL), памяти модели и языковых знаний. Через обширные эксперименты авторы демонстрируют, что производительность LLM часто предсказуема на основе более маленьких моделей или оказывается ниже базового уровня, оспаривая понятие устойчивых новых возможностей. В то время как настройка инструкций повышает способность моделей следовать инструкциям, авторы подчеркивают, что это не означает способности к рассуждению, что подтверждается «галлюцинациями». Для решения проблем безопасности исследование подчеркивает важность понимания ограничений LLM и призывает к разработке механизмов обнаружения и этических руководств для смягчения рисков. Это исследование заложило основу для уточнения понимания и безопасного, этичного применения LLM.
«`
















