

«`html
Преимущества дизайна последовательности белка: использование обучения с подкреплением и языковых моделей
Дизайн последовательности белков критичен в инженерии белков для поиска лекарств. Традиционные методы, такие как эволюционные стратегии и симуляции методом Монте-Карло, часто требуют помощи для эффективного изучения огромного комбинаторного пространства последовательностей аминокислот и обобщения на новые последовательности. Обучение с подкреплением предлагает многообещающий подход, позволяющий создавать новые последовательности путем изучения политик мутации. Недавние достижения в языковых моделях белков (PLMs), обученных на обширных наборах данных последовательностей белков, предоставляют еще один путь. Эти модели оценивают белки на основе биологических метрик, таких как TM-оценка, помогая в дизайне белков и предсказаниях складывания. Это необходимо для понимания клеточных функций и ускорения усилий по разработке лекарств.
Предложенные практические решения
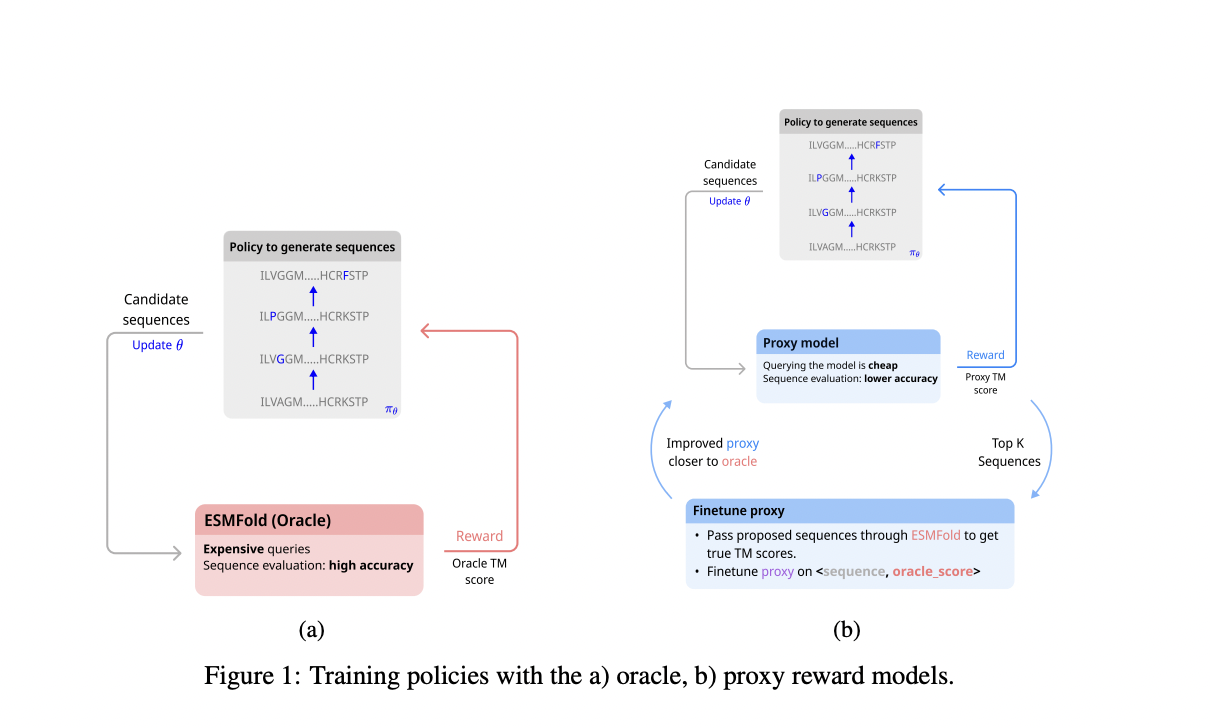
Исследователи из МакГиллского университета, Института искусственного интеллекта Мила-Квебек, Монреальской технической школы, Университета BRAC, Бангладешского университета инженерии и технологии, Калгарийского университета, СИФАР и Dreamfold предлагают использовать языковые модели белков в качестве функций вознаграждения для создания новых последовательностей белков. Однако PLMs могут быть вычислительно интенсивными из-за своего размера. Чтобы решить эту проблему, они предлагают альтернативный подход, основанный на оценках от более маленькой модели-прокси, периодически донастраиваемой вместе с обучением политик мутации. Их эксперименты на разных длинах последовательностей показывают, что подходы на основе обучения с подкреплением достигают благоприятных результатов в биологической правдоподобности и разнообразии последовательностей. Они предоставляют реализацию с открытым исходным кодом, облегчающую интеграцию различных PLMs и алгоритмов исследования, нацеленных на развитие исследований в области дизайна последовательности белков.
Оценка различных методов
Были изучены различные методы для создания биологических последовательностей. Эволюционные алгоритмы, такие как направленная эволюция и AdaLead, сосредотачиваются на итеративном изменении последовательностей на основе метрик производительности. Covariance Matrix Adaptation Evolution Strategy (CMA-ES) создает кандидатские последовательности с использованием многомерного нормального распределения. Proximal Exploration (PEX) способствует выбору последовательностей, близких к дикому типу. Методы обучения с подкреплением, такие как DyNAPPO, оптимизируют вспомогательные функции вознаграждения для создания разнообразных последовательностей. GFlowNets выбирают композиции пропорционально их функциям вознаграждения, облегчая получение разнообразных конечных состояний. Генеративные модели, такие как дискретный диффузионный и потоковые модели, такие как FoldFlow, создают белки в пространстве последовательности или структуры. Байесовская оптимизация адаптирует вспомогательные модели для оптимизации последовательностей, решая многокритериальные задачи по дизайну белков. МСМС и байесовский подход выбирают последовательности на основе энергетических моделей и прогнозов структуры.
Моделирование задачи
В области дизайна последовательности белков с использованием обучения с подкреплением задача моделируется как процесс принятия решений Маркова (MDP), где последовательности мутируют на основе действий, выбранных политикой обучения с подкреплением. Последовательности представлены в формате кодирования в одном измерении, и мутации включают выбор позиций и замену аминокислот. Вознаграждение определяется оценкой структурной схожести с использованием либо дорогостоящей оракульной модели (ESMFold), либо более дешевой модели-прокси, периодически донастраиваемой с истинными оценками от оракула. Оценочные критерии сосредотачиваются на биологической правдоподобности и разнообразии, оцениваемых с помощью метрик, таких как TM-оценка и тест локальной разницы расстояний (LDDT), а также показателей разнообразия последовательностей и структур.
Оценка результатов и практическая польза
Различные алгоритмы дизайна последовательности были оценены с использованием pTM-оценок ESMFold в качестве основной метрики в проведенных экспериментах. Результаты показали, что методы, такие как МСМС, отлично справляются с прямой оптимизацией pTM, а методы обучения с подкреплением и GFlowNets демонстрируют эффективность за счет использования модели-прокси. Эти методы сохраняли высокие оценки pTM при существенном снижении вычислительных затрат. Однако производительность МСМС ухудшилась при донастройке с использованием прокси, возможно из-за попадания в субоптимальные решения, соответствующие модели-прокси, но не ESMFold. В целом методы обучения с подкреплением, такие как PPO и SAC, вместе с GFlowNets, продемонстрировали надежную производительность по биологической правдоподобности и метрикам разнообразия, доказывая их адаптивность и эффективность для задач генерации последовательностей.
Исследование ограничено вычислительными ограничениями для более длинных последовательностей и зависимостью от либо модели-прокси, либо модели 3B ESMFold для оценки. Неопределенность или несоответствие в модели вознаграждения добавляет сложности, требуя будущих исследований с другими PLMs, такими как AlphaFold2, или более крупными вариантами ESMFold. Масштабирование до больших моделей-прокси может улучшить точность для более длинных последовательностей. Хотя исследование не предвидит негативных последствий, оно подчеркивает потенциальное злоупотребление PLMs. В целом данная работа демонстрирует эффективность использования PLMs для разработки политик мутации для генерации последовательностей белков, показывая глубокие алгоритмы обучения с подкреплением как надежных участников в этой области.
Проверьте статью. Вся заслуга за это исследование принадлежит его исследователям. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка. Не забудьте присоединиться к нашему субреддиту с более чем 46 000 участников.
Как использовать искусственный интеллект в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Advancements in Protein Sequence Design: Leveraging Reinforcement Learning and Language Models.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`

















