

«`html
Проблема в системах текст к речи (TTS) и как ее решить с помощью AI
Важное испытание в системах текст к речи (TTS) — это недостаточная вычислительная эффективность алгоритма монотонного поиска выравнивания (MAS), который отвечает за оценку соответствия между последовательностями текста и речи. MAS сталкивается с высокой вычислительной сложностью, особенно при работе с большими входными данными. Сложность составляет O(T×S), где T — длина текста, а S — длина представления речи. При увеличении размера ввода вычислительная нагрузка становится неуправляемой, особенно когда алгоритм выполняется последовательно без использования параллельной обработки. Эта неэффективность препятствует его применению в режиме реального времени и в крупномасштабных приложениях в моделях TTS. Поэтому решение этой проблемы критично для улучшения масштабируемости и производительности систем TTS, обеспечивая более быстрое обучение и вывод на различных задачах искусственного интеллекта, требующих выравнивания последовательностей.
Решение
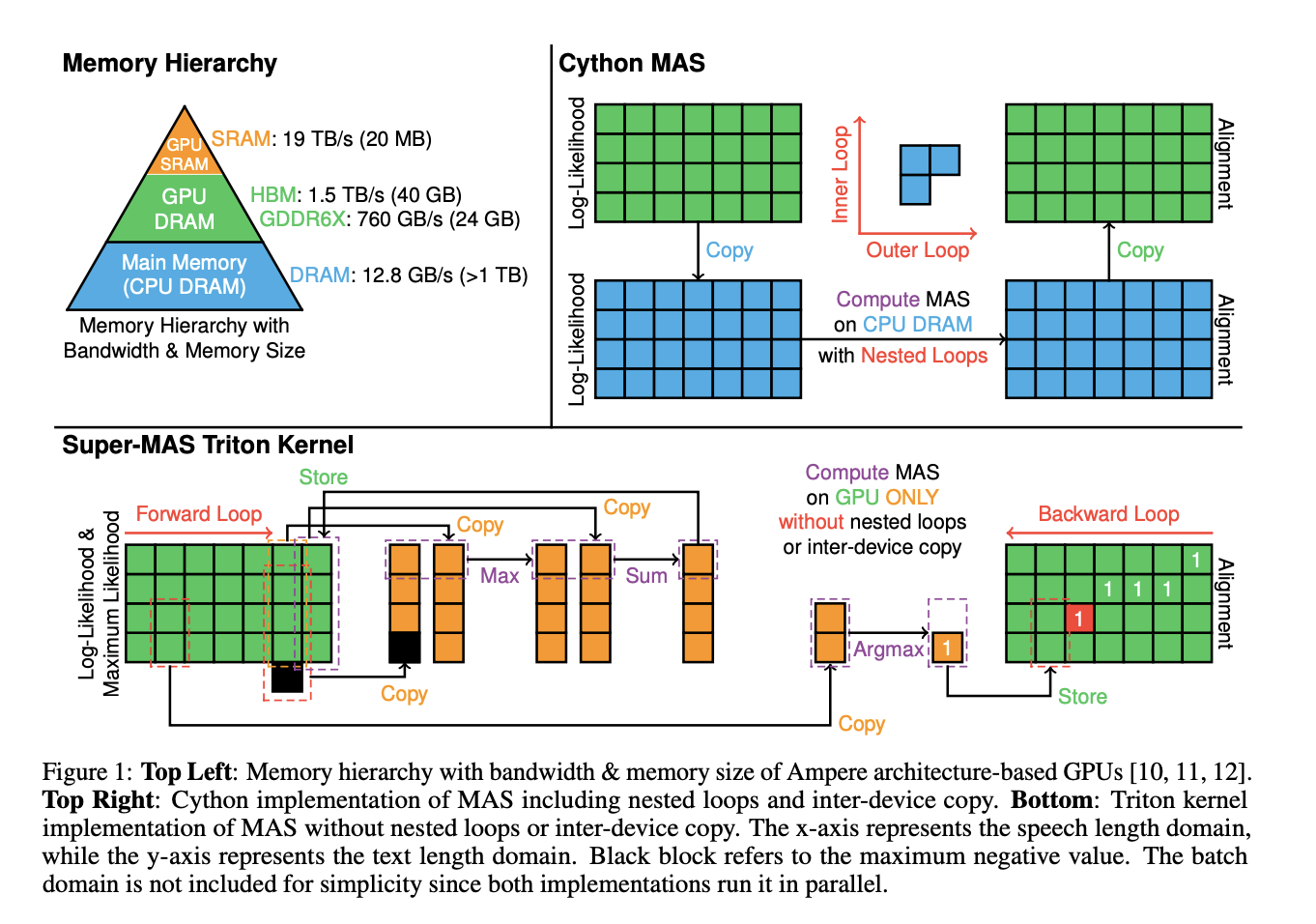
Команда исследователей из университета Джонса Хопкинса и компании Supertone Inc. предлагает Super-MAS, новое решение, которое использует Triton kernels и сценарии PyTorch JIT для оптимизации MAS для выполнения на GPU, устраняя вложенные циклы и межустройственные передачи памяти. За счет параллелизации по размеру текста этот подход значительно снижает вычислительную сложность. Введение более большого значения max_neg_val (-1e32) уменьшает несоответствия выравнивания, улучшая общую точность. Кроме того, выполнение вычисления логарифма вероятности на месте минимизирует выделение памяти, дополнительно оптимизируя процесс. Эти улучшения делают алгоритм гораздо более эффективным и масштабируемым, особенно для реального времени в системах TTS или других задач, требующих крупномасштабного выравнивания последовательностей.
Super-MAS реализован путем векторизации размера текста при помощи Triton kernels, в отличие от традиционных методов, которые параллелят размер партий с помощью Cython. Это изменение устраняет вложенные циклы, которые ранее замедляли вычисления. Матрица логарифма вероятности инициализируется, и выравнивания рассчитываются с использованием динамического программирования, при этом прямые и обратные циклы проходят по матрице для вычисления и восстановления путей выравнивания. Весь процесс выполняется на GPU, избегая неэффективностей, вызванных межустройственными передачами между ЦП и GPU. Был выполнен ряд тестов с использованием тензоров логарифма вероятности со значением размера партии B=32, длиной текста T и длиной речи S=4T.
Super-MAS достигает значительного увеличения скорости выполнения, при этом Triton kernel работает в 19–72 раза быстрее, чем реализация на Cython, в зависимости от размера входных данных. Например, для текста длиной 1024 Super-MAS завершает задачу за 19,77 миллисекунд, по сравнению с 1299,56 миллисекунд у Cython. Эти ускорения особенно ярко выражены при увеличении размера ввода, подтверждая, что Super-MAS является высокомасштабируемым и значительно более эффективным для обработки больших наборов данных. Он также превосходит версии PyTorch JIT, особенно для больших входных данных, что делает его идеальным выбором для приложений в реальном времени в системах TTS или других задач, требующих эффективного выравнивания последовательностей.
В заключение, Super-MAS представляет собой передовое решение для вычислительных проблем монотонного поиска выравнивания в системах TTS, достигая существенного сокращения вычислительной сложности через параллелизацию на GPU и оптимизацию памяти. Устранение необходимости вложенных циклов и межустройственных передач дает очень эффективный и масштабируемый метод для задач выравнивания последовательностей, обеспечивая ускорение до 72 раз по сравнению с существующими методами. Этот прорыв обеспечивает более быструю и точную обработку, что делает его бесценным для приложений искусственного интеллекта в реальном времени, таких как TTS и не только.
Проверьте статью и репозиторий на GitHub. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе в LinkedIn. Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему SubReddit ML с более чем 50 000 подписчиков
БЕСПЛАТНЫЙ ВЕБИНАР ПО ИСКУССТВЕННОМУ ИНТЕЛЛЕКТУ: «SAM 2 для видео: как настроить на ваши данные» (ср, 25 сен, 4:00 – 4:45 EST)
Источник: MarkTechPost.
«`

















