

«`html
Преодоление вызовов в области анализа временных рядов с помощью предварительного обучения моделей
Предварительное обучение больших моделей на данных временных рядов сталкивается с несколькими вызовами: отсутствием обширного общедоступного репозитория временных рядов, сложностью разнообразных характеристик временных рядов и отсутствием экспериментальных бенчмарков для оценки моделей, особенно в условиях ограниченных ресурсов и минимального уровня наблюдения. Несмотря на эти препятствия, анализ временных рядов остается важным в приложениях, таких как прогноз погоды, обнаружение аномалий в сердечном ритме и выявление аномалий в развертывании программного обеспечения. Использование предварительно обученных языковых, видео и видео моделей предлагает надежду, хотя адаптация к конкретным данным временных рядов необходима для оптимальной производительности.
Применение трансформеров к анализу временных рядов
Применение трансформеров к анализу временных рядов представляет вызовы из-за квадратичного роста механизма самовнимания с увеличением размера входного токена. Обработка подпоследовательностей временных рядов как токенов повышает эффективность и эффективность в прогнозировании. Использование переноса обучения между модальностями с помощью ORCA расширяет предварительно обученные модели на различные модальности через выравнивание и затем уточнение донастройки. Недавние исследования использовали этот подход для перепрограммирования предварительно обученных языковых трансформеров для анализа временных рядов, хотя ресурсоемкие модели требуют значительных ресурсов памяти и вычислительных ресурсов для оптимальной производительности.
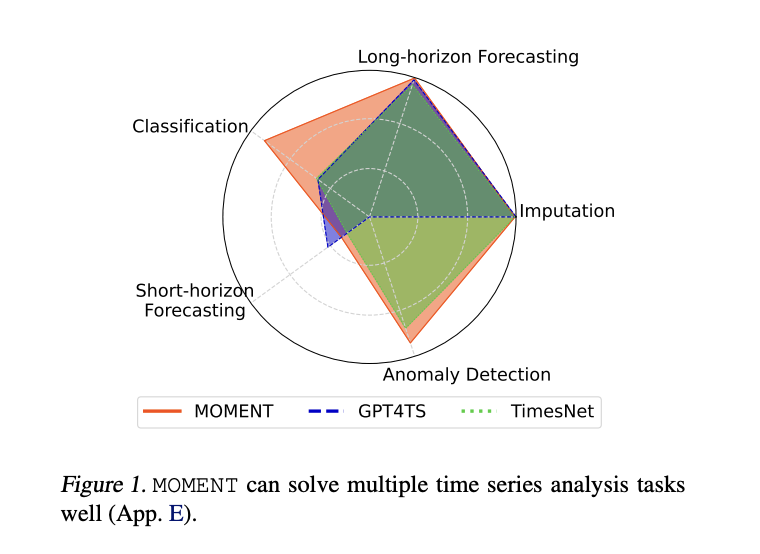
Модель MOMENT для анализа временных рядов
Исследователи из Университета Карнеги-Меллон и Университета Пенсильвании представляют MOMENT, открытую семейство фундаментальных моделей для общего анализа временных рядов. Она использует Time Series Pile, разнообразную коллекцию общедоступных временных рядов, чтобы решить специфические проблемы временных рядов и обеспечить предварительное обучение многодатасетного масштаба. Эти модели трансформеров большой емкости предварительно обучаются с использованием задачи маскированного прогнозирования временных рядов на обширных данных из различных областей, предлагая универсальность и надежность в решении разнообразных задач анализа временных рядов.
Сравнение MOMENT с другими моделями
Исследование сравнивает MOMENT с современными моделями глубокого обучения и статистического машинного обучения по различным задачам. Эти сравнения важны для оценки практической применимости предложенных методов. Интересно, что статистические и не трансформерные методы, такие как ARIMA для краткосрочного прогнозирования, N-BEATS для долгосрочного прогнозирования и k-ближайших соседей для обнаружения аномалий, демонстрируют превосходную производительность над многими моделями глубокого обучения и трансформерами.
Заключение
Данное исследование представляет MOMENT, первое открытое семейство фундаментальных моделей временных рядов, разработанных через все этапы компиляции данных, предварительного обучения моделей и систематического решения специфических проблем временных рядов. MOMENT демонстрирует высокую производительность в предварительном обучении моделей трансформеров различных размеров. Исследование также разрабатывает экспериментальный бенчмарк для оценки фундаментальных моделей временных рядов по множеству практических задач, особенно подчеркивая сценарии с ограниченными вычислительными ресурсами и наблюдением. MOMENT проявляет эффективность в различных задачах, демонстрируя превосходную производительность, особенно в обнаружении аномалий и классификации, благодаря своему предварительному обучению. Исследование также подчеркивает жизнеспособность более мелких статистических и менее глубоких методов глубокого обучения во многих задачах. В конечном итоге, исследование нацелено на продвижение открытой науки путем выпуска Time Series Pile, вместе с кодом, весами моделей и журналами обучения, способствуя сотрудничеству и дальнейшему развитию в анализе временных рядов.
Проверьте статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 42k+ ML SubReddit.
Источник: MarkTechPost
«`

















