

«`html
Исследование скрытых слоев в больших языковых моделях (LLM)
Исследователи из Университета Иерусалима рассмотрели проблему понимания того, как информация проходит через различные слои декодерных больших языковых моделей (LLM). Они исследовали, насколько важны скрытые состояния предыдущих токенов в более высоких слоях. Текущие LLM, такие как модели на основе трансформера, используют механизм внимания для обработки токенов, обращая внимание на все предыдущие токены в каждом слое. Однако предыдущие исследования показывают, что различные слои захватывают разные типы информации. Исследование основано на идее, что не все слои могут одинаково полагаться на скрытые состояния предыдущих токенов, особенно в более высоких слоях.
Практические решения и ценность
Исследовательская группа предположила, что в то время как нижние слои фокусируются на агрегации информации от предыдущих токенов, более высокие слои могут меньше полагаться на эту информацию. Они предлагают различные манипуляции в скрытых состояниях предыдущих токенов в различных слоях модели. Это включает замену скрытых состояний случайными векторами, замораживание скрытых состояний на определенных слоях и замену скрытых состояний одного токена другим из другого запроса. Они проводят эксперименты на четырех открытых LLM (Llama2-7B, Mistral-7B, Yi-6B и Llemma-7B) и четырех задачах, включая вопросно-ответную систему и суммаризацию, чтобы оценить влияние этих манипуляций на производительность модели.
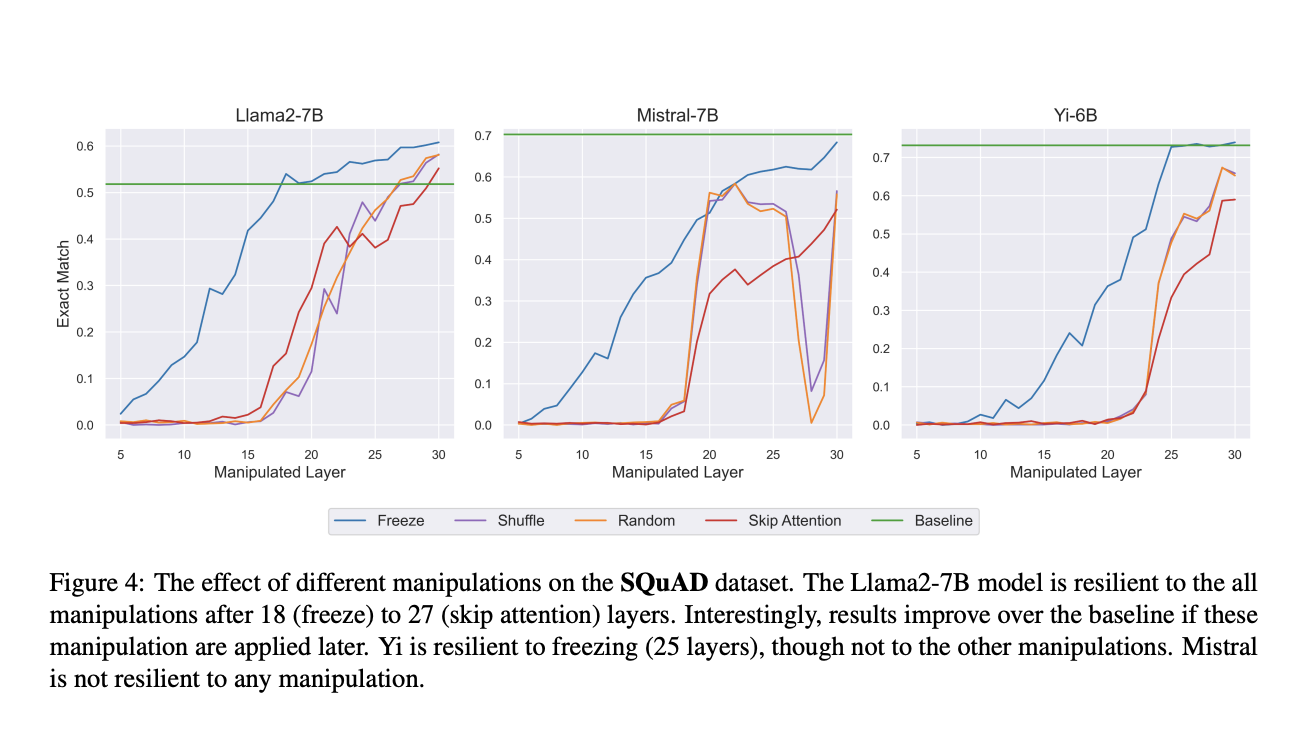
Одна из техник включает в себя введение шума путем замены скрытых состояний случайными векторами, что позволяет исследователям оценить, имеет ли значение содержание этих скрытых состояний на определенных слоях. Второй метод, замораживание, блокирует скрытые состояния на определенном слое и повторно использует их для последующих слоев, уменьшая вычислительную нагрузку.
Исследователи обнаружили, что при применении этих манипуляций к верхним 30-50% модели производительность по нескольким задачам практически не ухудшилась, что указывает на то, что верхние слои меньше полагаются на скрытые представления предыдущих токенов. Например, при замораживании до 50% слоев модели сохраняли производительность, аналогичную базовой. Кроме того, замена скрытых состояний из разных запросов дополнительно подтвердила это наблюдение; модель игнорировала изменения, внесенные в верхние слои, в то время как изменения в нижних слоях значительно изменяли вывод. Эксперименты были проведены для понимания, нужно ли внимание в более высоких слоях модели, пропуская блок внимания в этих слоях. Этот тест показал, что пропуск внимания в верхних слоях имел минимальное влияние на задачи, такие как суммаризация и вопросно-ответная система, в то время как это привело к серьезному снижению производительности в нижних слоях.
В заключение, исследование раскрывает двухфазовый процесс в LLM на основе трансформера: ранние слои собирают информацию от предыдущих токенов, в то время как более высокие слои в основном обрабатывают эту информацию внутренне. Полученные результаты предполагают, что более высокие слои менее зависят от детального представления предыдущих токенов, предлагая потенциальные оптимизации, такие как пропуск внимания в этих слоях для снижения вычислительных затрат. В целом, статья углубляется в иерархическую природу обработки информации в LLM и приводит к более обоснованным и эффективным моделям.
Подпишитесь на нашу рассылку
Если вам интересно узнать больше о нашей работе, подпишитесь на нашу рассылку. Также не забудьте присоединиться к нам в наших социальных сетях: Twitter и LinkedIn.
Бесплатный вебинар по ИИ
Присоединяйтесь к нашему бесплатному вебинару по ИИ: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Ср, 25 сентября, 11:00 – 11:45 GMT+3)
«`


















