

«`html
Введение в Vision Transformers
Vision Transformers (ViTs) изменили область компьютерного зрения, предлагая новую архитектуру, которая использует механизмы самовнимания для обработки изображений. В отличие от сверточных нейронных сетей (CNN), которые используют свертки для извлечения признаков, ViTs разбивают изображения на небольшие фрагменты и рассматривают их как отдельные токены. Это позволяет эффективно обрабатывать большие наборы данных и делает ViTs особенно эффективными для задач, таких как классификация изображений и обнаружение объектов.
Преимущества ViTs
ViTs предоставляют гибкую основу для решения различных задач в компьютерном зрении благодаря возможности отделять, как информация передается между токенами, от процесса извлечения признаков внутри токенов.
Необходимость предобучения для ViTs
Существует вопрос о том, насколько важно предобучение для ViTs. Ранее считалось, что оно улучшает производительность в дальнейших задачах. Однако исследователи начали сомневаться, действительно ли это связано только с извлечением признаков или другие факторы, такие как паттерны внимания, играют более значимую роль.
Методы использования предобученных ViTs
Обычные подходы к использованию предобученных ViTs включают дообучение всей модели на конкретных задачах. Однако это затрудняет понимание вклада каждого метода. Исследователи из Университета Карнеги-Меллон и FAIR предложили новый метод “Attention Transfer”, который позволяет изолировать и передавать только паттерны внимания от предобученных ViTs.
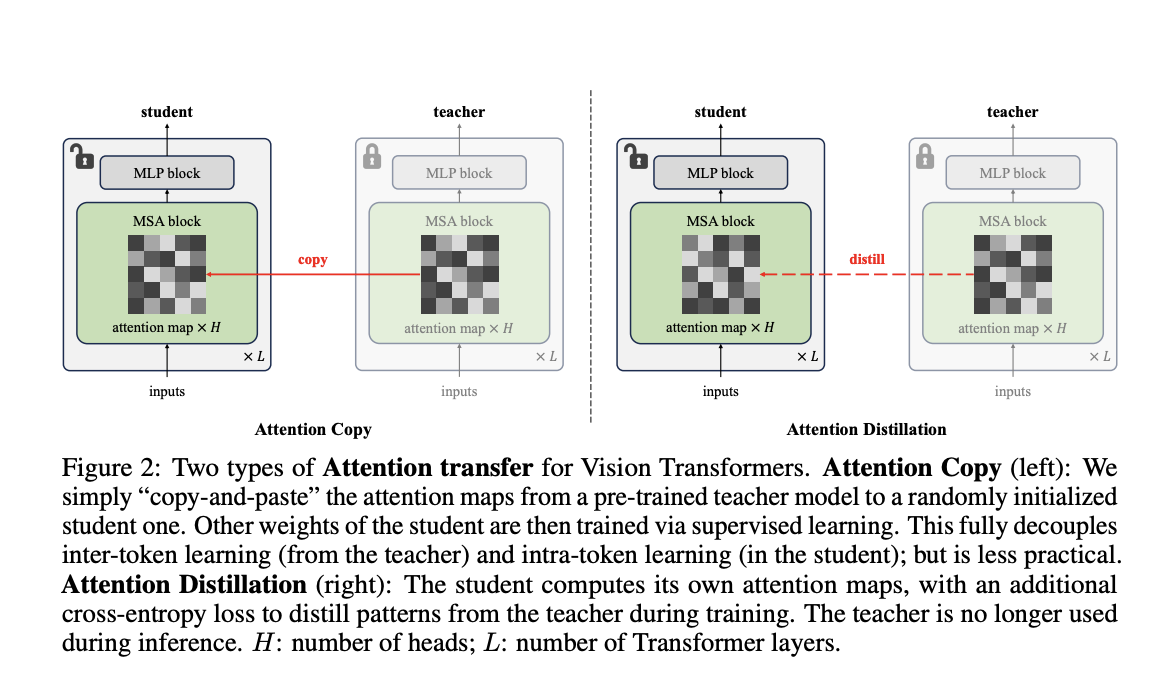
Методы Attention Transfer
Предложенная методология включает два метода: Attention Copy и Attention Distillation.
- Attention Copy: Паттерны внимания передаются от предобученной модели к студенту, который обучается с нуля на остальных параметрах.
- Attention Distillation: Студент обучается сопоставлять свои карты внимания с картами учителя через функцию потерь, что делает данный подход более практичным после обучения.
Преимущества методов
Эти методы показывают эффективность паттернов внимания в предобученных ViTs. Attention Distillation достигла точности 85.7% на наборе данных ImageNet-1K, что сопоставимо с полностью дообученными моделями. Attention Copy показала 85.1% точности, что подтверждает ее эффективность.
Заключение и дальнейшие шаги
Исследования показывают, что предобученные паттерны внимания могут быть достаточными для достижения высокой производительности в дальнейших задачах, что ставит под сомнение необходимость традиционных подходов к предобучению. Предложенный метод Attention Transfer открывает новые возможности для оптимизации использования ViTs в компьютерном зрении.
Практические шаги по внедрению ИИ в вашу компанию
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Выберите подходящее решение для автоматизации, начиная с небольших проектов.
- Расширяйте автоматизацию на основе полученных результатов и опыта.
Следите за новостями об ИИ и новыми возможностями, которые он предлагает. Будущее уже здесь!
«`


















