

«`html
Превосходство Large Language Models (LLMs) в задачах естественной обработки языка
Большие языковые модели (LLMs) привели к значительным достижениям в различных задачах естественной обработки языка (NLP). Эти модели отлично справляются с пониманием и генерацией текста, играя ключевую роль в таких приложениях, как машинный перевод, сжатие текста и более сложные задачи рассуждения. Прогресс в этой области продолжает трансформировать способы понимания и обработки языка машинами, открывая новые возможности для исследований и разработок.
Решение проблемы различий в рассуждениях LLMs и человеческом экспертном уровне
Существенной проблемой в этой области является разрыв между способностями рассуждения LLMs и экспертным уровнем человека. Эта разница особенно заметна в сложных задачах рассуждения, где традиционные модели нуждаются в помощи для производства точных результатов. Проблема заключается в том, что модели полагаются на механизмы большинствовающего голосования, которые часто терпят неудачу, когда неправильные ответы доминируют в наборе сгенерированных ответов.
Практические решения для улучшения рассуждений LLMs
Существующие работы включают в себя методы, такие как Chain-of-Thought (CoT) prompting, Self-consistency, Complexity-based prompting, DiVeRSe и Progressive-Hint Prompting, которые направлены на улучшение способностей рассуждения LLMs путем повышения согласованности и точности сгенерированных ответов.
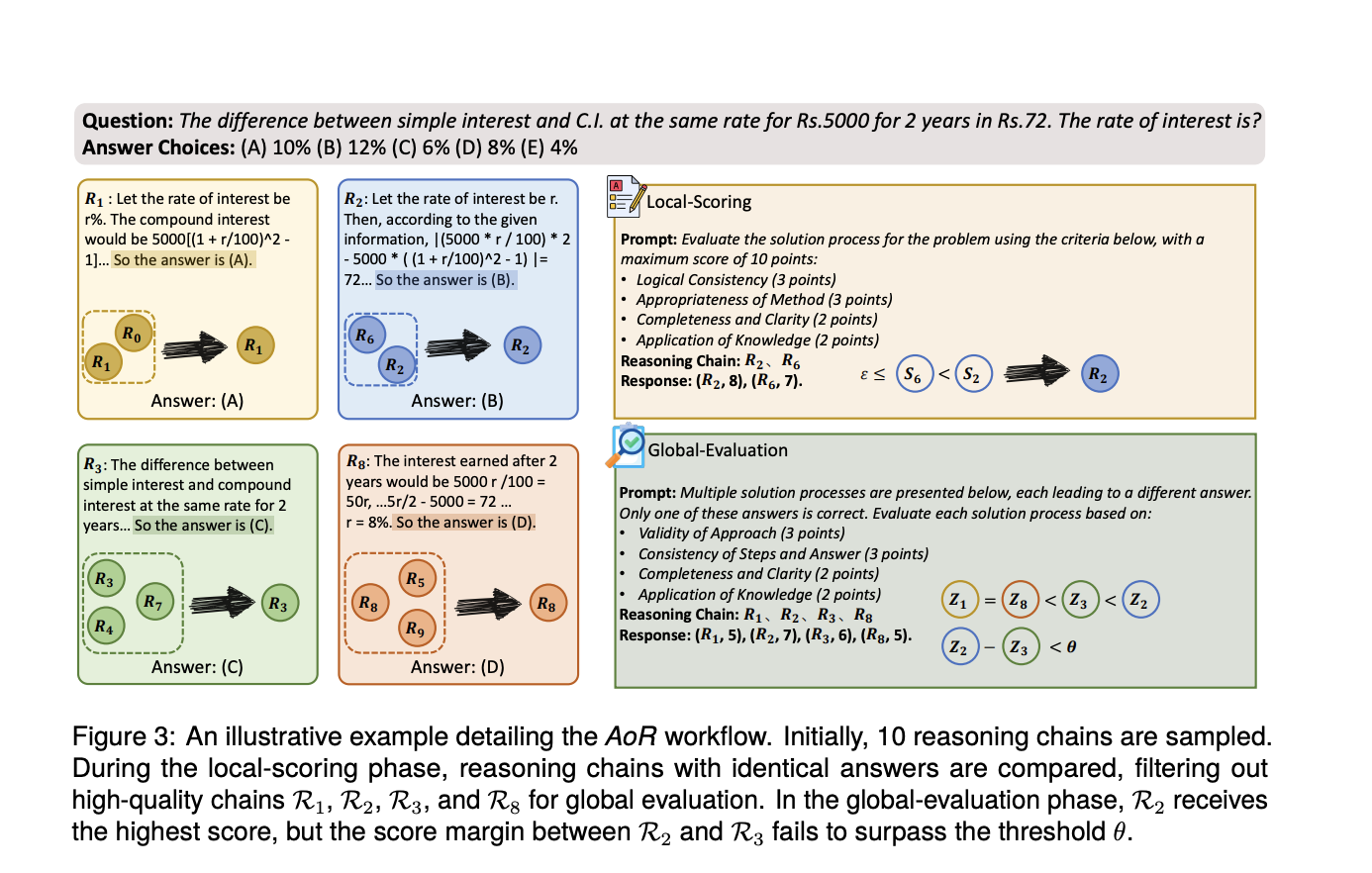
Исследователи из Университета Фудан, Национального университета Сингапура и Midea AI Research Center представили иерархическую агрегационную структуру рассуждений под названием AoR (Aggregation of Reasoning). Эта инновационная структура сдвигает фокус с частоты ответов на оценку цепочек рассуждений, что позволяет улучшить точность и надежность способностей рассуждения LLMs.
Фреймворк AoR демонстрирует значительное превосходство над традиционными методами ансамблей в сложных задачах рассуждения. Он также успешно адаптируется к различным архитектурам LLM, включая GPT-3.5-Turbo-0301, и показывает превосходную производительность. Особенно стоит отметить, что динамическая выборка AoR эффективно балансирует производительность с вычислительной стоимостью, снижая накладные расходы на 20% по сравнению с существующими методами, сохраняя при этом высокую точность.
В заключение, фреймворк AoR решает критическое ограничение в способностях рассуждения LLMs, представляя метод, который оценивает и агрегирует процессы рассуждения. Этот инновационный подход улучшает точность и эффективность LLMs в сложных задачах рассуждения, делая значительные шаги в сокращении разрыва между машинным и человеческим рассуждением.
Подробнее ознакомьтесь с документом. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в SubReddit.
Оригинальная статья: Beyond the Frequency Game: AoR Evaluates Reasoning Chains for Accurate LLM Decisions на сайте MarkTechPost.
«`



















