

Исследование OpenAI: оценка влияния o1 на вероятностные предвзятости LLM
Результаты исследования
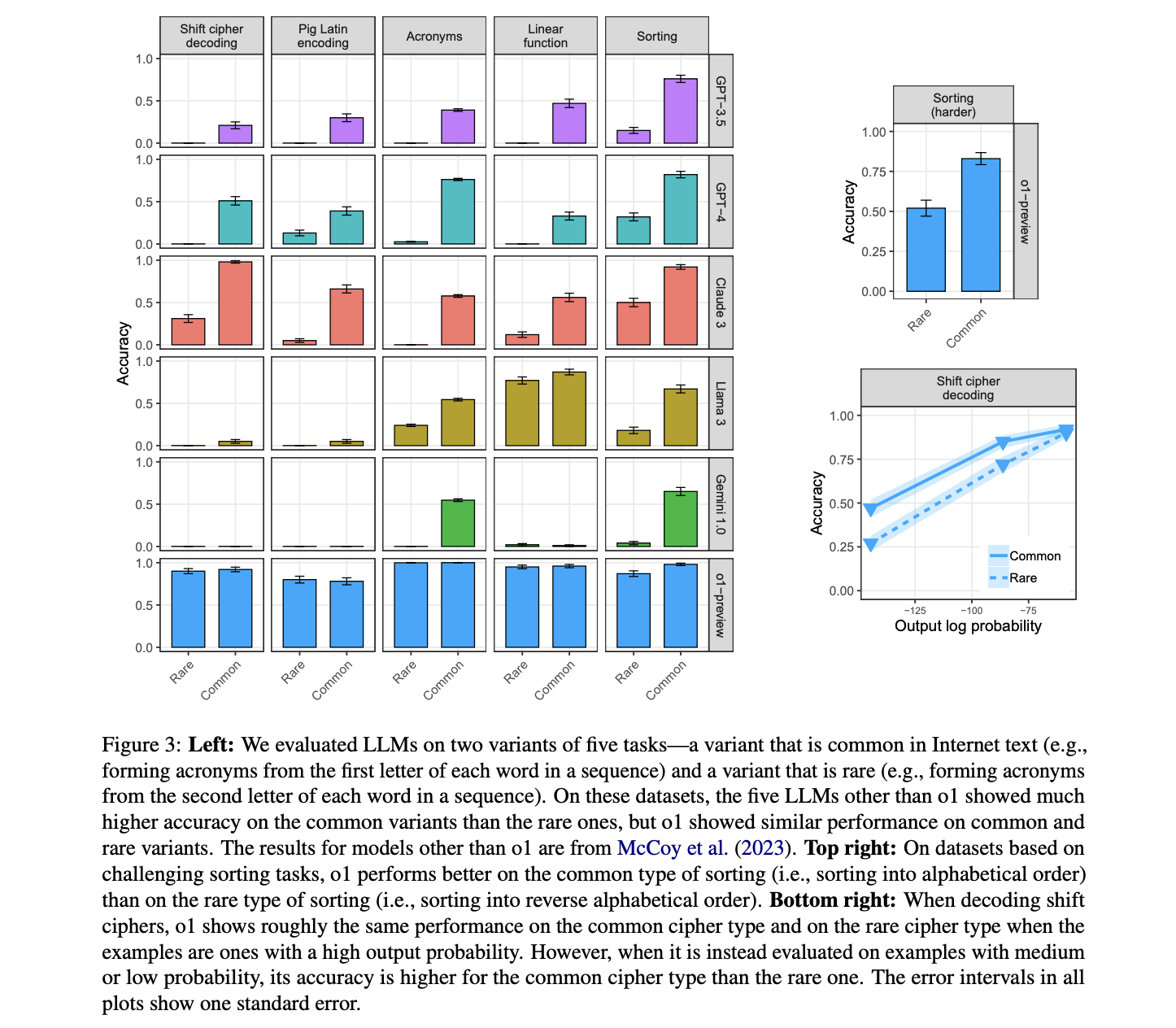
Исследование показало, что o1, несмотря на значительные улучшения по сравнению с предыдущими LLM, все еще чувствителен к вероятности вывода и частоте задач. О1 продемонстрировал более высокую точность на примерах с высокой вероятностью вывода по сравнению с низкой вероятностью. Например, в задаче сдвига шифра точность o1 варьировалась от 47% для случаев с низкой вероятностью до 92% для случаев с высокой вероятностью. Кроме того, o1 потреблял больше токенов при обработке примеров с низкой вероятностью, что указывает на увеличение сложности.
Что касается частоты задач, o1 изначально показал схожую производительность на обычных и редких вариантах задач, превзойдя другие LLM на редких вариантах. Однако, когда тестировали на более сложных версиях задач сортировки и сдвига шифра, o1 продемонстрировал лучшую производительность на обычных вариантах, что указывает на то, что эффекты частоты задач становятся заметными, когда модель доводится до предела.
Выводы исследователей
Итак, несмотря на значительные улучшения, o1 все еще чувствителен к вероятности вывода и частоте задач. Это соответствует телологической перспективе, учитывающей все оптимизационные процессы, применяемые к системе ИИ. Высокая производительность o1 в алгоритмических задачах отражает его явную оптимизацию для рассуждений. Однако наблюдаемые поведенческие шаблоны свидетельствуют о том, что o1, вероятно, также претерпел значительное обучение по предсказанию следующего слова.
Исследователи предлагают два потенциальных источника чувствительности o1 к вероятности: предвзятости в генерации текста, присущие системам, оптимизированным для статистического прогнозирования, и предвзятости в развитии цепочек мыслей, благоприятствующих сценариям с высокой вероятностью. Для преодоления этих ограничений исследователи предлагают внедрение компонентов модели, не полагающихся на вероятностные суждения, таких как модули выполнения кода Python.













![Полное руководство по вознаграждению за продажи [Новые данные]](https://saile.ru/wp-content/uploads/2025/04/itinai.com_beautiful_Russian_high_fashion_Sales_representativ_49598c66-36f0-4405-85f7-0503bed00755_3-200x200.png)


![Как создать успешные кампании по электронной почте [Примеры и лучшие практики]](https://saile.ru/wp-content/uploads/2025/04/itinai.com_beautiful_Russian_high_fashion_Sales_representativ_81976356-11a7-4f61-9064-75fe15742118_0-200x200.png)


