

«`html
Оптимизация разреженных нейронных сетей для улучшения динамики обучения и эффективности
Разреженные нейронные сети направлены на оптимизацию вычислительной эффективности путем уменьшения количества активных весов в модели. Эта техника важна, поскольку она решает проблемы растущих вычислительных затрат, связанных с обучением и выводом в глубоком обучении. Разреженные сети улучшают производительность без плотных соединений, что позволяет сократить вычислительные ресурсы и энергопотребление.
Проблема и решение
Основная проблема, решаемая в данном исследовании, — это необходимость более эффективного обучения разреженных нейронных сетей. Разреженные модели страдают от нарушения распространения сигнала из-за значительного числа весов, установленных в ноль. Эта проблема усложняет процесс обучения, затрудняя достижение уровня производительности, сопоставимого с плотными моделями. Кроме того, настройка гиперпараметров для разреженных моделей затратна и занимает много времени из-за того, что оптимальные гиперпараметры для плотных сетей не подходят для разреженных. Этот дисбаланс приводит к неэффективным процессам обучения и увеличению вычислительной нагрузки.
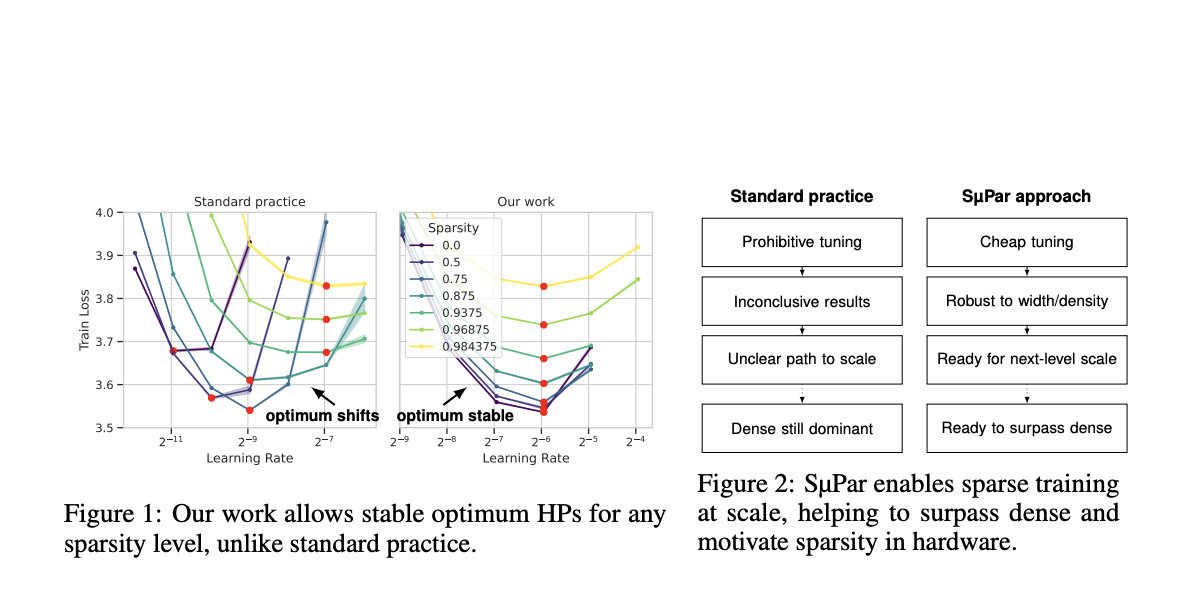
Существующие методы обучения разреженных нейронных сетей часто включают повторное использование гиперпараметров, оптимизированных для плотных сетей, что может быть менее эффективным. Разреженные сети требуют различных оптимальных гиперпараметров, и введение новых гиперпараметров для разреженных моделей дополнительно усложняет процесс настройки. Эта сложность приводит к запредельным затратам на настройку, подрывая основную цель сокращения вычислений. Кроме того, отсутствие установленных методов обучения для разреженных моделей затрудняет их эффективное масштабирование.
Новый подход
Исследователи Cerebras Systems представили новый подход под названием Sparse Maximal Update Parameterization (SμPar). Этот метод направлен на стабилизацию динамики обучения разреженных нейронных сетей, обеспечивая независимость масштабирования активаций, градиентов и обновлений весов от уровня разреженности. SμPar переопределяет гиперпараметры, позволяя одинаковым значениям быть оптимальными при различных уровнях разреженности и ширине модели. Этот подход значительно снижает затраты на настройку, позволяя оптимально настроенным гиперпараметрам для маленьких плотных моделей эффективно переноситься на большие разреженные модели.
SμPar корректирует инициализацию весов и скорости обучения для поддержания стабильной динамики обучения при различных уровнях разреженности и ширине модели. Он обеспечивает контроль над масштабами активаций, градиентов и обновлений весов, избегая проблем, таких как взрывной или затухающий сигнал. Этот метод позволяет гиперпараметрам оставаться оптимальными независимо от разреженности и ширины модели, облегчая эффективное и масштабируемое обучение разреженных нейронных сетей.
Результаты
Эффективность SμPar продемонстрировала превосходство по сравнению со стандартными практиками. SμPar повысил потери обучения до 8,2% в моделировании языка масштаба в сравнении с обычным подходом, использующим стандартную параметризацию плотных моделей. Это улучшение наблюдалось при различных уровнях разреженности, причем SμPar стал образовывать фронтир Парето для потерь, указывая на его устойчивость и эффективность. Согласно закону масштабирования Чинчиллы, эти улучшения приводят к увеличению вычислительной эффективности в 4,1 и 1,5 раза. Такие результаты подчеркивают эффективность SμPar в улучшении производительности и эффективности разреженных нейронных сетей.
Заключение
Данное исследование решает проблемы неэффективности текущих методов обучения разреженных сетей и представляет SμPar в качестве комплексного решения. Стабилизация динамики обучения и снижение затрат на настройку гиперпараметров позволяют SμPar обеспечивать более эффективное и масштабируемое обучение разреженных нейронных сетей. Этот прогресс обещает улучшить вычислительную эффективность моделей глубокого обучения и ускорить принятие разреженности в конструкции аппаратных средств. Новый подход переопределения гиперпараметров для обеспечения стабильности при различных уровнях разреженности и ширине модели является значительным шагом в оптимизации нейронных сетей.
Статья. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе LinkedIn.
Если вам нравится наша работа, вам понравится наш информационный бюллетень.
Не забудьте присоединиться к нашему 43k+ ML SubReddit. Также, посетите нашу платформу по событиям по ИИ.
Источник: MarkTechPost.
Развивайтесь с помощью искусственного интеллекта
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Sparse Maximal Update Parameterization (SμPar): Оптимизация разреженных нейронных сетей для улучшения динамики обучения и эффективности.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на ITinAI. Следите за новостями о ИИ в нашем Телеграм-канале ITinAINews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab. Будущее уже здесь!
«`



















