

«`html
Оптимизация проектирования белков с помощью улучшенных языковых моделей
Автогрессивные языковые модели белков (pLMs) стали революционными инструментами для проектирования функциональных белков с выдающимся разнообразием. Они успешно создают семейства ферментов, такие как лизоцимы и карбоангидразы. Эти модели генерируют последовательности белков, исследуя вероятностные распределения, выявляя внутренние закономерности в обучающих данных.
Проблемы и решения
Несмотря на свои возможности, pLMs сталкиваются с трудностями при нацеливании на редкие и ценные области, что ограничивает их эффективность в задачах, таких как инженерия ферментативной активности или связывания. Традиционные методы, такие как направленная эволюция, ограничены локальным исследованием и не имеют инструментов для управления долгосрочными эволюционными траекториями.
Методы обучения с подкреплением (RL) предлагают многообещающую основу для оптимизации pLMs, направляя их на улучшение конкретных свойств с помощью обратной связи от внешних источников, таких как предсказанная стабильность или связывающая способность. Применение RL в проектировании белков демонстрирует потенциал для эффективного исследования редких событий и балансировки между исследованием и эксплуатацией.
DPO_pLM: новое решение
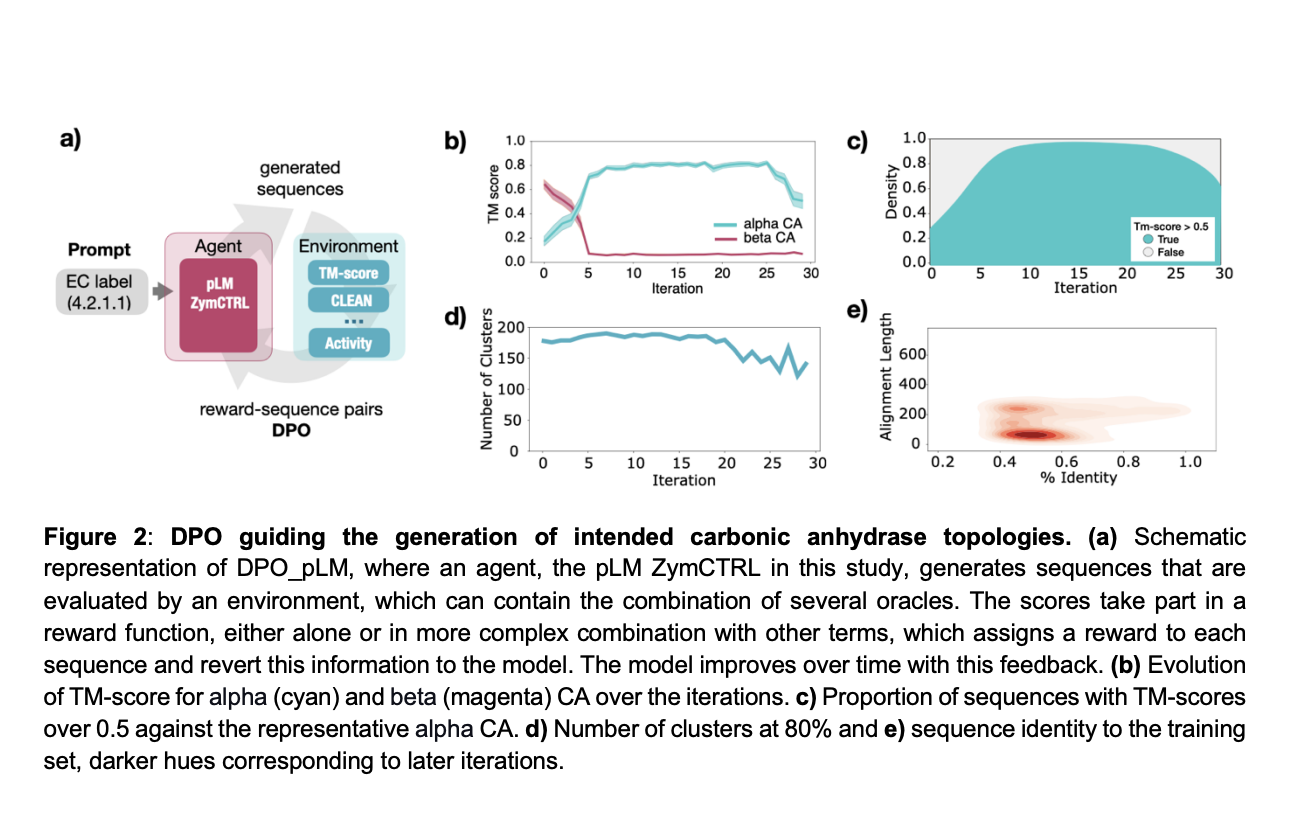
Исследователи из Universitat Pompeu Fabra и других ведущих учреждений разработали DPO_pLM, фреймворк RL для оптимизации последовательностей белков с помощью генеративных pLMs. DPO_pLM оптимизирует разнообразные свойства без дополнительных данных, сохраняя при этом разнообразие последовательностей. Он превосходит традиционные методы, снижая вычислительные затраты и предотвращая катастрофическое забывание.
DPO минимизирует функции потерь, а самонастройка (s-FT) итеративно улучшает ZymCTRL, генерируя и ранжируя лучшие последовательности. Обучение модели использует API Hugging Face, что позволяет эффективно управлять процессом.
Преимущества применения RL
pLMs генерируют последовательности, похожие на обучающие данные, и часто достигают высокой функциональности, несмотря на значительные отклонения. Применение RL, особенно методов, таких как DPO, позволяет итеративно настраивать pLMs с использованием обратной связи, что дает возможность генерировать последовательности с целевыми свойствами.
Заключение
pLMs отлично справляются с выборкой из распределений, но испытывают трудности с оптимизацией конкретных свойств. DPO_pLM преодолевает это ограничение, используя прямую оптимизацию предпочтений, что позволяет быстро и эффективно генерировать белки с заданными характеристиками.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ), грамотно используйте DPO_pLM для оптимизации проектирования белков.
Практические шаги для внедрения ИИ
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение и внедряйте ИИ постепенно.
- На основе полученных данных расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам в Телеграм.
Попробуйте AI Sales Bot — это AI ассистент для продаж, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить процесс продаж в вашей компании с решением от saile.ru — будущее уже здесь!
«`

















