

«`html
Как оптимизировать использование KV-Cache для эффективной работы больших языковых моделей
Большие языковые модели (LLM) представляют собой подмножество искусственного интеллекта, фокусирующееся на понимании и генерации человеческого языка. Эти модели используют сложные архитектуры для понимания и создания текста, что облегчает их применение в областях обслуживания клиентов, создания контента и других сферах.
Проблема эффективности обработки длинных текстов
Одним из главных вызовов в работе с LLM является их эффективность при обработке длинных текстов. Архитектура Transformer, которую они используют, имеет квадратичную временную сложность, что существенно увеличивает вычислительную нагрузку, особенно при работе с расширенными последовательностями. Эта сложность создает существенное препятствие для достижения эффективной производительности, особенно при увеличении длины входных текстов. Решение этой проблемы критически важно для дальнейшего развития и применения LLM в реальных сценариях.
Решение с применением KV-Cache
Исследователи предложили механизм KV-Cache для решения этой проблемы, который хранит ключи и значения, генерируемые предыдущими токенами. Это позволяет снизить временную сложность с квадратичной до линейной. Однако KV-Cache увеличивает использование памяти GPU, что масштабируется с увеличением длины разговора, создавая новое узкое место. Текущие методы направлены на балансировку этой компромисса между вычислительной эффективностью и накладными расходами памяти, что делает эффективное использование KV-Cache необходимым.
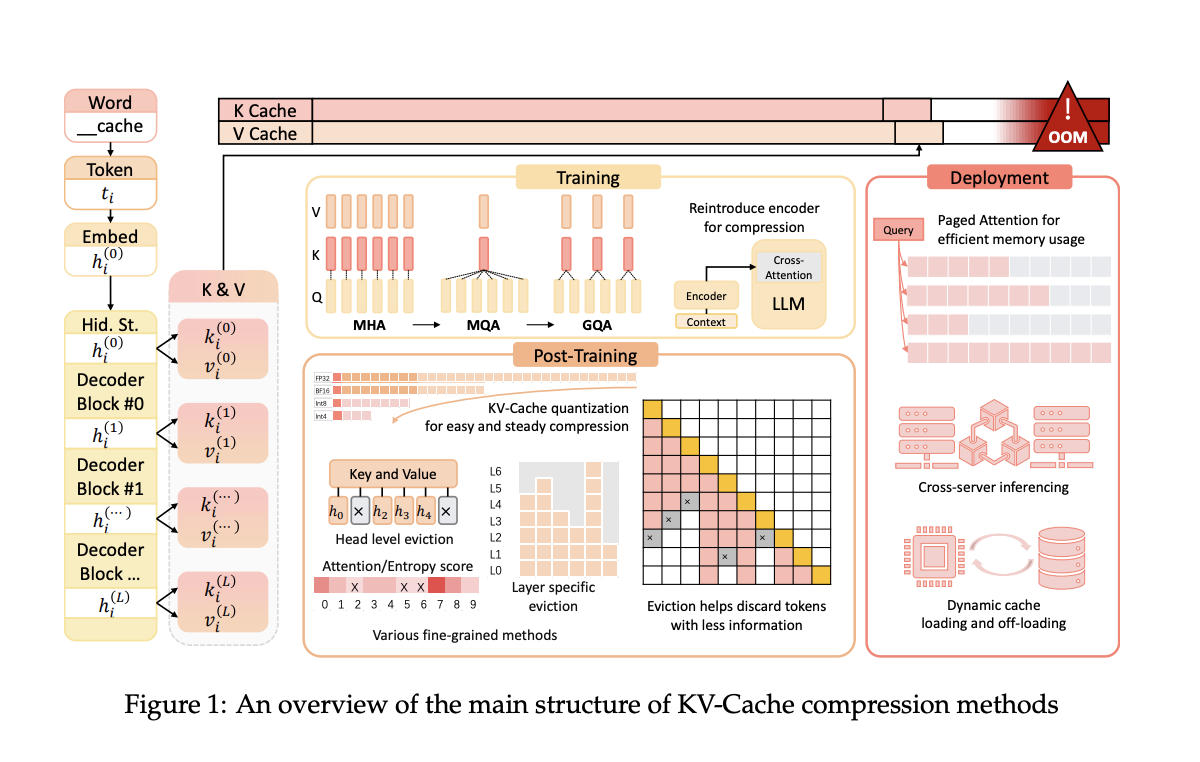
Оптимизация пространства KV-Cache
Команда исследователей из Университета Ухань и Шанхайского Университета Цзяотун предложила несколько методов сжатия KV-Cache. Эти методы оптимизируют использование пространства KV-Cache во время предварительного обучения, развертывания и вывода LLM, нацеливаясь на улучшение эффективности без ущерба производительности. Их подход включает модификацию архитектуры модели во время предварительного обучения для уменьшения размера векторов ключей и значений до 75%. Это позволяет сохранить преимущества механизма внимания при существенном снижении требований к памяти.
Предложенные методы включают архитектурные изменения во время предварительного обучения, которые уменьшают размер сгенерированных векторов ключей и значений. При развертывании фреймворки, такие как Paged Attention и DistKV-LLM, распределяют KV-Cache по нескольким серверам для улучшения управления памятью. Методы пост-обучения включают динамические стратегии вытеснения и техники квантования, которые сжимают KV-Cache без значительной потери возможностей модели.
Данные методы показали значительное улучшение эффективности памяти и скорости вывода. Например, метод GQA, используемый в популярных моделях, таких как LLaMA2-70B, обеспечивает более эффективное использование памяти за счет уменьшения размера KV-Cache при сохранении уровня производительности. Эти оптимизации продемонстрировали потенциал более эффективной обработки более длинных контекстов.
Исследование предоставляет комплексные стратегии для оптимизации KV-Cache в LLM, решая проблему накладных расходов памяти. Реализация этих методов позволяет добиться более высокой эффективности и производительности LLM, что открывает путь к более устойчивым и масштабируемым решениям в области искусственного интеллекта.
Подробнее о статье можно прочитать здесь.
Вся заслуга за это исследование принадлежит его авторам.
Не забудьте подписаться на наш Твиттер и присоединиться к нашей группе в ЛинкедИн. Если вам нравится наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу на Reddit.
Подробнее о предстоящих вебинарах по искусственному интеллекту можно узнать здесь.
«`















