

«`html
Искусственный интеллект (ИИ) в развитии и маркетинге
Практические решения для улучшения производительности моделей ИИ
Развитие больших языковых моделей (LLM) в области искусственного интеллекта (ИИ) направлено на их выравнивание с предпочтениями людей для увеличения эффективности и безопасности. Это выравнивание критично для улучшения взаимодействия ИИ с пользователями, обеспечивая точность и соответствие с ожиданиями и ценностями людей. Для достижения этой цели необходимо использовать данные о предпочтениях, которые информируют модель о желательных результатах, и цели выравнивания, которые направляют процесс обучения. Эти элементы критически важны для улучшения производительности модели и ее способности удовлетворять ожидания пользователей.
Одной из значительных проблем при выравнивании моделей ИИ является недостаточная спецификация, когда связь между данными о предпочтениях и целями обучения не четко определена. Этот недостаток ясности может привести к субоптимальной производительности, поскольку модели может потребоваться помощь для эффективного обучения на предоставленных данных. Недостаточная спецификация возникает, когда пары предпочтений, используемые для обучения модели, содержат несущественные различия по сравнению с желаемым результатом. Эти ненужные различия усложняют процесс обучения, делая его трудным для модели сфокусироваться на самых важных аспектах. Существующие методы выравнивания LLM, такие как основанные на контрастных целях обучения и наборах предпочтительных пар, сделали значительные шаги, но должны быть пересмотрены.
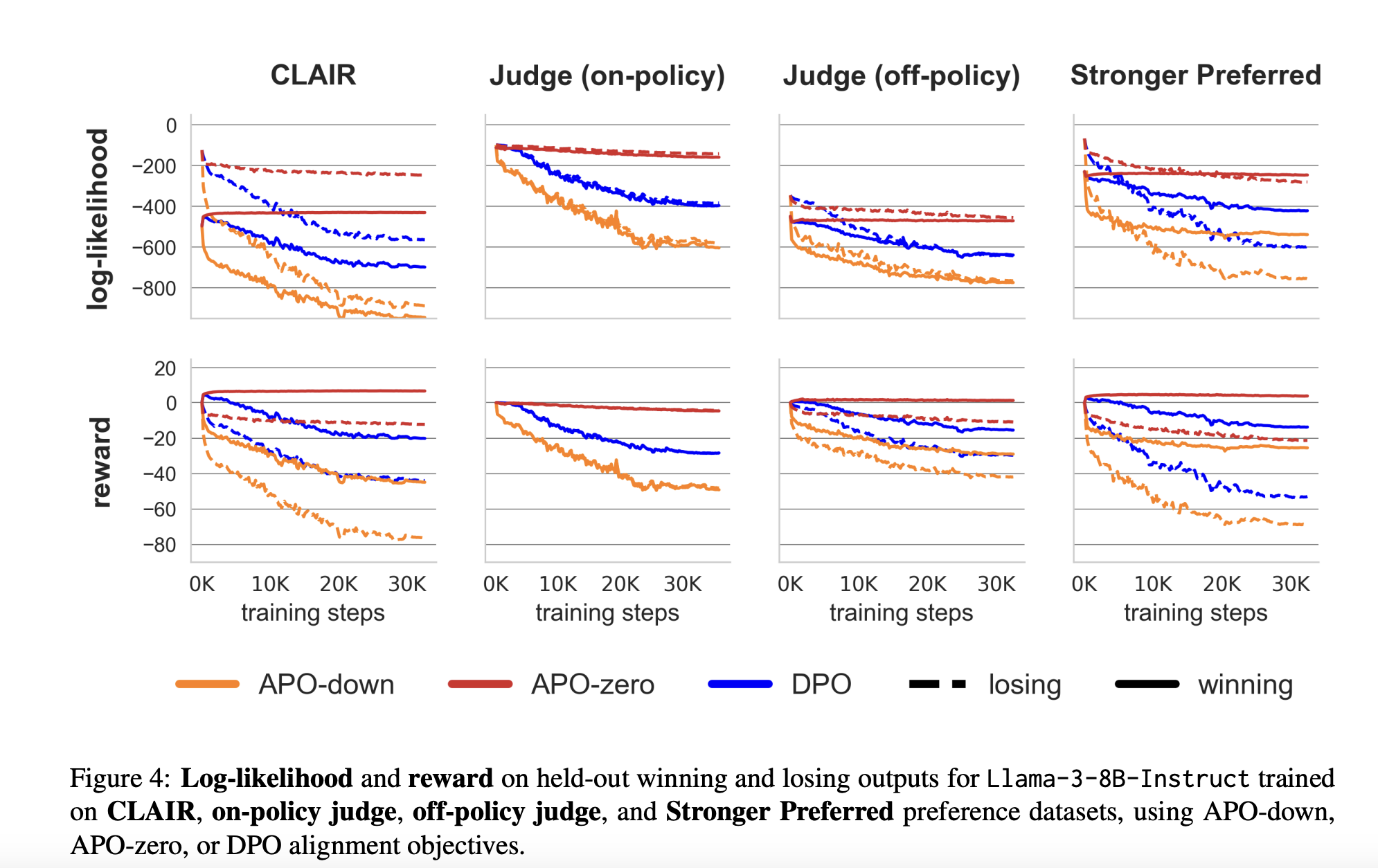
Исследователи из университета Гента – imec, Стэнфордского университета и Contextual AI представили два инновационных метода для решения этих проблем: Contrastive Learning from AI Revisions (CLAIR) и Anchored Preference Optimization (APO). CLAIR – новый метод создания данных, разработанный для генерации минимально контрастирующих пар предпочтений путем слегка изменения вывода модели для создания предпочтительного ответа. Этот метод обеспечивает более точный сигнал обучения для модели. APO – это семейство целей выравнивания, которые предлагают больший контроль над процессом обучения.
Эффективность CLAIR и APO была продемонстрирована на примере выравнивания модели Llama-3-8B-Instruct с использованием различных наборов данных и целей выравнивания. Результаты были значительными: CLAIR, в сочетании с целью APO-zero, привел к улучшению производительности на 7,65% на бенчмарке MixEval-Hard, что означает существенный шаг к уменьшению разрыва в производительности между моделью Llama-3-8B-Instruct и GPT-4-turbo.
В заключение, CLAIR и APO предлагают более эффективный подход к выравниванию LLM с предпочтениями людей, решая проблемы недостаточной спецификации и обеспечивая более точный контроль над процессом обучения.
Для получения дополнительной информации смотрите статью, модель и репозиторий на GitHub.
«`


















