

«`html
LLM-QFA Framework: Подход к обучению с учетом квантования для снижения затрат на обучение и развертывание больших языковых моделей (LLMs) в различных сценариях
Большие языковые модели (LLMs) сделали значительные прорывы в обработке естественного языка, но сталкиваются с проблемами из-за требований к памяти и вычислительных затрат. Традиционные методы квантования уменьшают размер модели, что помогает смягчить эти проблемы, но часто приводит к снижению производительности. Проблема усугубляется, когда LLM используются в различных ситуациях с ограниченными ресурсами. Это означает, что обучение с учетом квантования (QAT) необходимо проводить несколько раз для каждого приложения, что требует больших ресурсов.
Исследователи из Южно-Китайского университета технологий, Университета науки и технологии Гонконга, Университета Цинхуа и Salesforce AI Research предлагают LLM-QFA (Quantization-Aware Fine-tuning once-for-all for LLMs) для решения этих неэффективностей. Текущие методы обработки памяти и вычислительных неэффективностей LLM включают пост-обучение квантования (PTQ) и обучение с учетом квантования (QAT). PTQ сжимает модель без повторного обучения, обеспечивая быстрое развертывание, но часто за счет значительной потери производительности, особенно при низких битовых ширин. В то время как QAT интегрирует ошибки квантования во время обучения для поддержания производительности, это занимает много времени и требует больших вычислительных затрат. Предложенная структура направлена на обучение единого «один раз — для всех» супернета, способного генерировать различные оптимальные подсети, адаптированные для различных сценариев развертывания без повторного обучения.
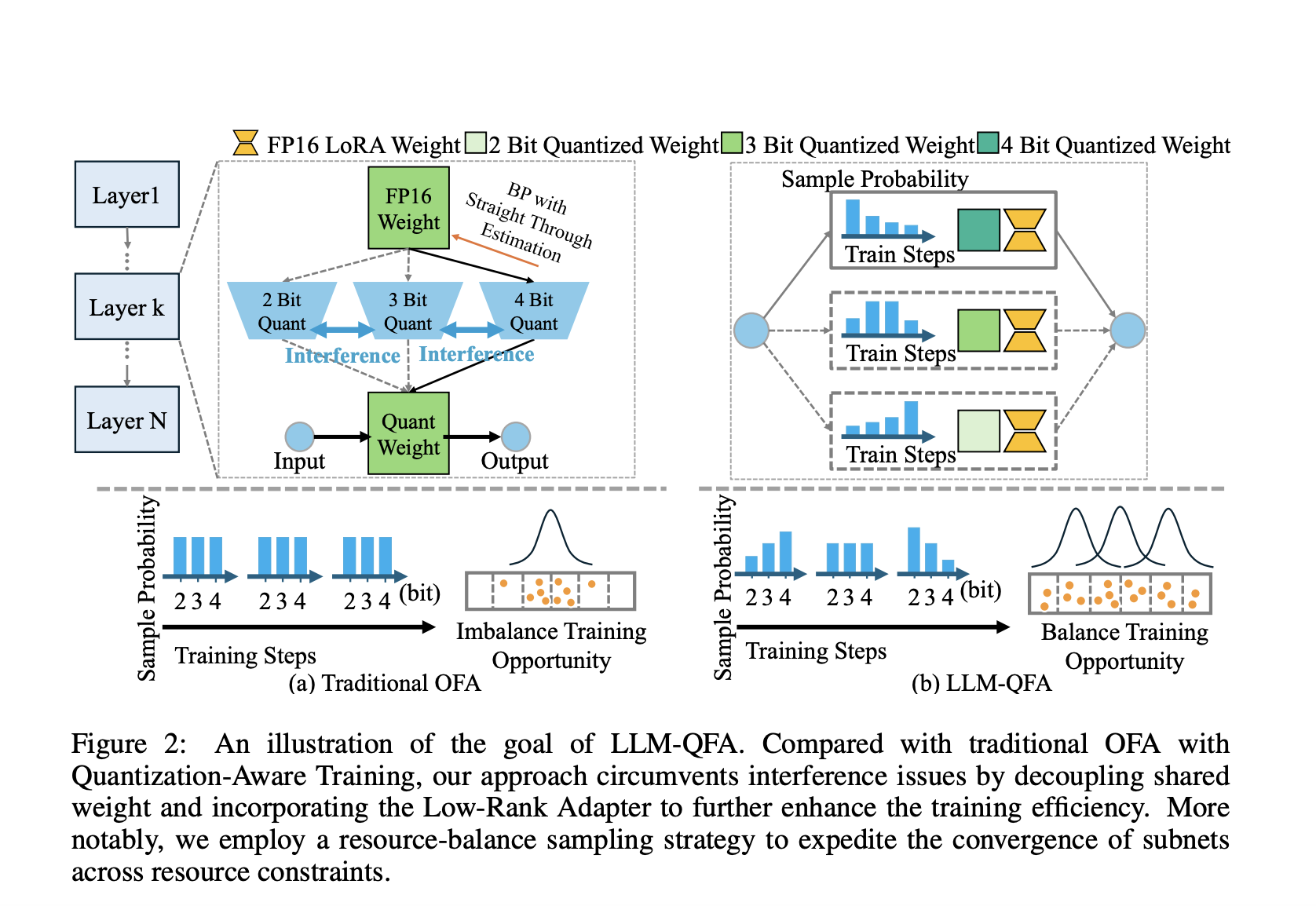
Фреймворк LLM-QFA решает проблемы вмешательства, вызванные совместным использованием весов в традиционном QAT, разделяя веса различных конфигураций квантования. Это достигается с использованием легких адаптеров низкого ранга, которые вносят незначительные дополнительные вычислительные затраты. В частности, метод включает квантование весов модели в различные битовые ширины (2, 3 и 4 бита) и применение адаптеров низкого ранга для каждой конфигурации. Во время тонкой настройки обновляются только адаптеры, соответствующие активной конфигурации квантования, тем самым избегая вмешательства между конфигурациями.
Фреймворк LLM-QFA адаптирует стратегию сбалансированной выборки ресурсов. Ранее равномерные стратегии выборки предпочитали подсети с средними битовыми ширинами, что приводило к несбалансированному обучению и недообучению подсетей с экстремальными конфигурациями битовых ширин. В отличие от этого, сбалансированная выборка ресурсов использует непараметрический планировщик для динамической корректировки коэффициента выборки, обеспечивая более сбалансированное распределение ресурсов для обучения среди подсетей. Этот сбалансированный подход помогает эффективно оптимизировать все подсети, что приводит к устойчивой производительности при различных ограничениях ресурсов.
Производительность LLM-QFA была оценена с использованием моделей LLaMA2 на бенчмарках MMLU и Common Sense QA. Результаты показали, что LLM-QFA способен поддерживать высокую производительность, существенно сокращая время развертывания по сравнению с традиционными методами QAT. Например, на бенчмарке MMLU LLM-QFA превзошел методы GPTQ и QA-LoRA, особенно при средних ограничениях битовых ширин, достигнув хорошего баланса между производительностью и эффективностью использования ресурсов. Фреймворк LLM-QFA также продемонстрировал последовательные улучшения на бенчмарках Common Sense QA, что дополнительно подтверждает его эффективность в различных сценариях развертывания.
В заключение, исследование решает критическую проблему эффективного развертывания больших языковых моделей в различных ограниченных ресурсами средах. Путем введения тонкой настройки без вмешательства с использованием адаптеров низкого ранга и стратегии сбалансированной выборки ресурсов предложенный фреймворк существенно снижает вычислительные затраты, связанные с традиционными методами QAT, сохраняя и улучшая производительность. Этот подход является значительным шагом в направлении сделать LLM более адаптивными и эффективными для реальных приложений, даже на ресурсоограниченных устройствах.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему 43k+ ML SubReddit. Также, ознакомьтесь с нашей платформой по AI-событиям.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте LLM-QFA Framework: A Once-for-All Quantization-Aware Training Approach to Reduce the Training Cost of Deploying Large Language Models (LLMs) Across Diverse Scenarios .
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot https://itinai.ru/aisales Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`
















