

Эффективное применение MaskLLM для оптимизации работы с ИИ
Простым языком:
LLMs, из-за своих больших размеров параметров, могут вызывать неэффективность в развертывании из-за высоких требований к памяти и вычислениям. Решением является полупространственное обрезание, особенно схема разреженности N: M, которая повышает эффективность, сохраняя N ненулевых значений среди M параметров. Методы, такие как SparseGPT и Wanda, используют небольшие наборы калибровки и критерии важности для выбора избыточных параметров.
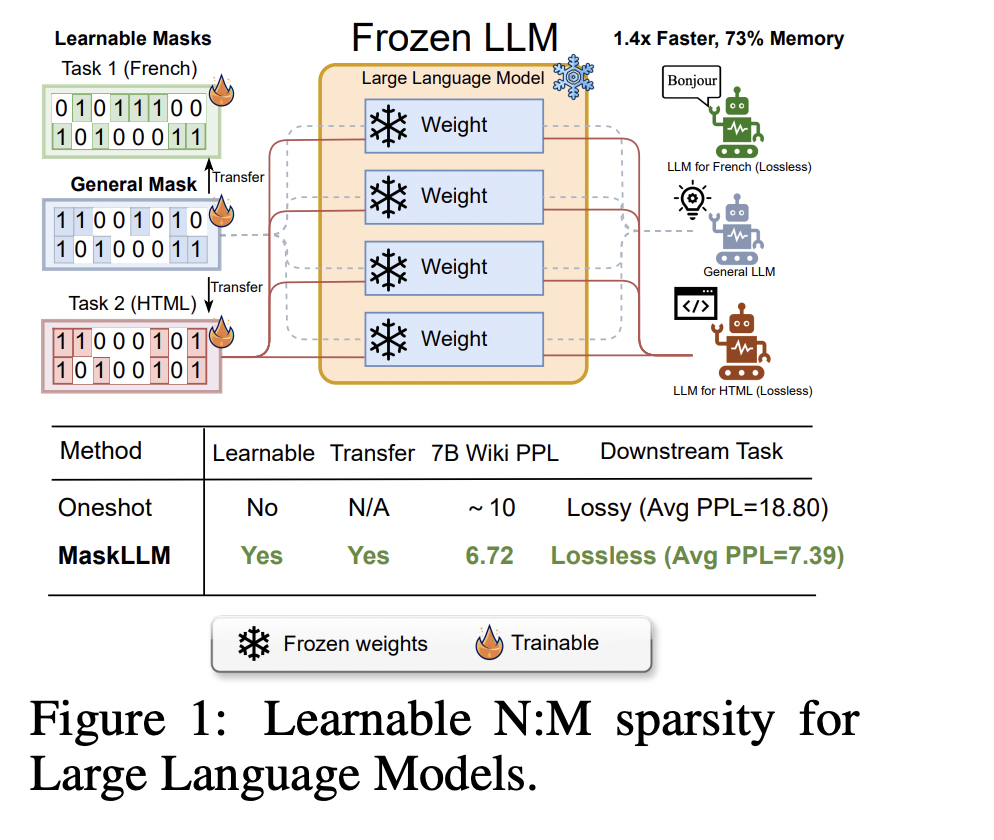
Исследователи из NVIDIA и Национального университета Сингапура представили MaskLLM, метод обучаемого обрезания, который применяет разреженность N: M к LLMs, снижая вычислительные издержки во время вывода. MaskLLM использует Gumbel Softmax для моделирования разреженности как обучаемого распределения, повышая точность маски и переносимость, что позволяет применять изученные образцы разреженности в различных задачах или областях.
Метод обрезания эффективен для сжатия LLMs за счет удаления избыточных параметров. Структурированное обрезание удаляет подструктуры, такие как головы внимания, неструктурированное обрезание обнуляет отдельные параметры, а полуструктурированное обрезание, такое как N: M разреженность, сочетает структурированные шаблоны с разреженностью мелкозернистого уровня для повышения эффективности и гибкости.
MaskLLM внедряет разреженность N: M для оптимизации LLMs путем выбора бинарных масок для блоков параметров, обеспечивая эффективное обрезание без значительного ухудшения производительности модели. Маски могут быть настроены для безошибочного выполнения задач на следующем уровне.
Если вам нужна помощь с внедрением ИИ, обращайтесь к нам на Telegram: https://t.me/itinai. Следите за новостями об ИИ в нашем Телеграм-канале: https://t.me/aisalesbotnews.














![Руководство по анализу цепочки создания стоимости [с шаблонами]](https://saile.ru/wp-content/uploads/2025/04/itinai.com_beautiful_Russian_high_fashion_Sales_representativ_bcd5566a-4c6e-4173-99a0-8b2fad9f6248_3-200x200.png)


