

«`html
Transformers: новые инсайты для эффективного сокращения и улучшения производительности
Раскрытие скрытой линейности в Transformer Decoder
Transformer’ы значительно изменили обработку естественного языка, достигнув значительного прогресса в различных областях. Однако, несмотря на их широкое использование и достижения, исследования в области их работы продолжают углубляться, особенно в отношении линейной природы промежуточных встраиваемых трансформаций. Этот менее изученный аспект имеет значительные последствия для дальнейшего развития в данной области.
Линейное свойство декодеров трансформеров
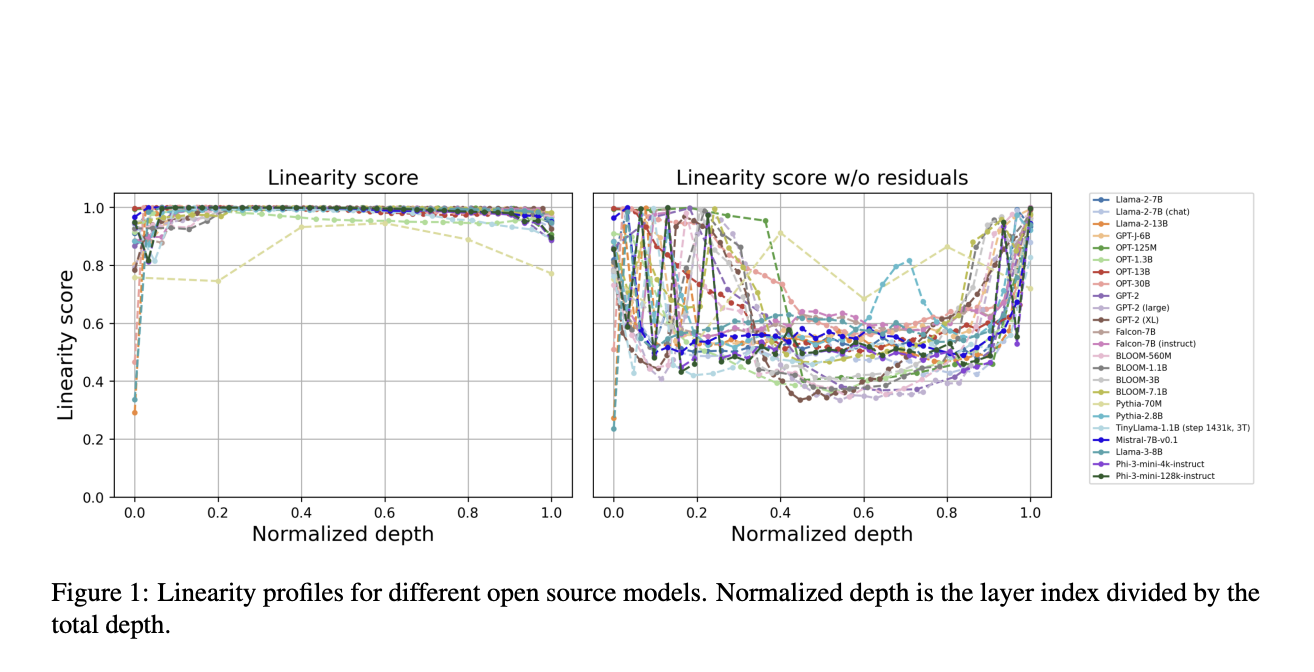
Исследователи из AIRI, Сколтеха, SberAI, НИУ ВШЭ и МГУ имени Ломоносова представили уникальное линейное свойство, специфичное для декодеров трансформеров, обнаруженное в моделях GPT, LLaMA, OPT и BLOOM. Они обнаружили почти идеальную линейную зависимость в трансформациях встраивания между последовательными слоями, вызывая сомнения в традиционном понимании. Удаление или приближение этих линейных блоков минимально влияет на производительность модели, что приводит к разработке алгоритмов сокращения глубины и новых техник дистилляции. Внедрение регуляризации на основе косинус-подобности во время предварительного обучения улучшает производительность модели на бенчмарках. Это позволяет уменьшить линейность слоев и предлагает исследование более эффективных архитектур трансформеров без ущерба для эффективности, решая значительную проблему их внедрения.
Исследование разреженности для сокращения модели
Исследования разреженности для сокращения моделей является значительной фокусировкой в машинном обучении. Предыдущие исследования изучали методы, такие как обратное распространение ошибки и тонкую настройку, чтобы понять разреженность в сверточных нейронных сетях. Техники, такие как дистилляция SquareHead и WANDA, были разработаны для решения вызовов разреженной тонкой настройки для LLM. Понимание внутренней структуры моделей трансформеров привело к новым идеям в их линейной сложности. В данном исследовании исследуются методики сокращения для LLM, специально использующие линейность слоев, основанных на декодере. Эти методы направлены на эффективное сокращение размера модели, сохраняя при этом высокую производительность на бенчмарк-задачах.
Заключение
Данное исследование предоставляет всестороннее исследование линейности декодеров трансформеров, раскрывая их врожденное почти линейное поведение в различных моделях. Исследователи наблюдают парадоксальный эффект, при котором предварительное обучение увеличивает нелинейность, в то время как тонкая настройка для конкретных задач может сократить её. Внедрение новых техник сокращения и дистилляции показывает, что модель трансформера может быть улучшена без ущерба производительности. Кроме того, косинус-основанный подход к регуляризации во время предварительного обучения улучшает эффективность модели и производительность на бенчмарках. Однако данное исследование ограничено своим фокусом на декодерах трансформеров. Его требуется дальнейшее исследование в области только кодировщиков или кодировщиков-декодеров, а также масштабируемость предложенных методик к различным моделям и областям.
Проверьте документ здесь. Весь кредит за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Твиттере. Присоединяйтесь к нашему каналу в Телеграме, каналу в Discord и группе в LinkedIn.
Если вам понравилась наша работа, вам обязательно понравится наша рассылка.
Не забудьте подписаться на наш подкаст с 42k+ подписчиков по машинному обучению.