

«`html
Проблемы анализа табличных данных и их решение с помощью ИИ
Проблемы анализа табличных данных
Табличные данные, которые преобладают во многих областях, таких как здравоохранение, финансы и социальные науки, содержат структурированные строки и столбцы, что облегчает управление и анализ данных. Однако разнообразие табличных данных, включая числовые, безусловные и текстовые, создает огромные вызовы для достижения надежной и точной прогностической производительности. Еще одной областью для улучшения в эффективном моделировании и анализе этого типа данных является сложность отношений внутри данных, особенно зависимости между строками и столбцами.
Решение с помощью ИИ
Главная проблема в анализе табличных данных заключается в том, что очень сложно обрабатывать их гетерогенную структуру. Традиционные модели машинного обучения далеко отстают, особенно для больших и сложных наборов данных. Эти модели требуют дополнительного руководства для обобщения при наличии разнообразия типов данных и взаимосвязей табличных данных. Эта проблема становится еще более сложной в связи с необходимостью высокой прогностической точности и надежности, особенно в критических областях, таких как здравоохранение.
Различные методы были применены для преодоления этих вызовов моделирования табличных данных. Ранние техники в основном полагались на традиционное машинное обучение, большинство из которых требовали много инженерии признаков для моделирования тонкостей данных. Известная слабость этих методов заключается в их неспособности масштабироваться по размеру и сложности входного набора данных. Более недавно методы из области обработки естественного языка (NLP) были адаптированы для табличных данных; более конкретно, архитектуры на основе трансформеров все чаще применяются. Эти методы начались с обучения трансформеров с нуля на табличных данных, но это имело недостаток в необходимости большого объема обучающих данных с серьезными проблемами масштабируемости. В этой связи исследователи начали использовать предобученные языковые модели (PLM) типа BERT, которые требовали меньше данных и обеспечивали лучшую прогностическую производительность.
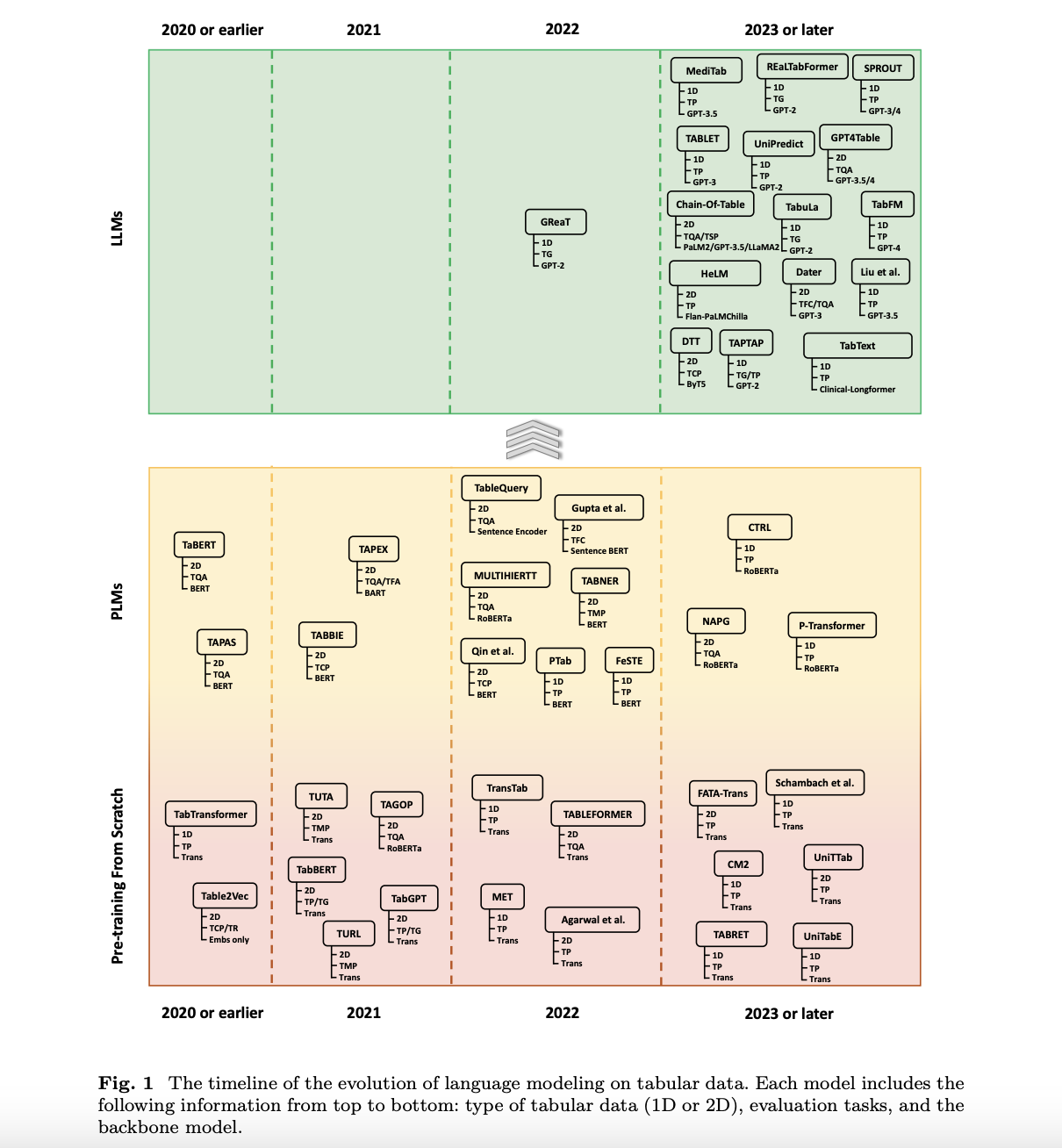
Исследователи из Национального университета Сингапура предоставили всесторонний обзор различных техник языкового моделирования, разработанных для табличных данных. Обзор систематизирует классификацию литературы и дополнительно выявляет сдвиг тенденций от традиционных моделей машинного обучения к передовым методам, использующим современные языковые модели, такие как GPT и LLaMA. Это исследование подчеркивает эволюцию этих моделей, показывая, как языковые модели стали радикальными в этой области, перенося ее в более сложные приложения в моделировании табличных данных. Эта работа важна для заполнения пробела в соответствующей литературе путем предоставления подробной таксономии структур табличных данных, ключевых наборов данных и различных методов моделирования.
Методология, предложенная исследовательской группой, категоризирует табличные данные на две основные категории: 1D и 2D. В то время как 1D табличные данные обычно содержат только одну таблицу, основная работа происходит на уровне строк, что, конечно, проще, но очень важно для задач, таких как классификация и регрессия. В отличие от этого, 2D табличные данные состоят из нескольких связанных таблиц, требуя более сложных методов моделирования для задач, таких как извлечение таблиц и вопросно-ответное моделирование таблиц. Исследователи изучают различные стратегии преобразования табличных данных в формы, которые их языковая модель может обрабатывать. Эти стратегии включают выравнивание последовательностей, обработку строк и интеграцию этой информации в запросы. С помощью этих методов языковые модели получают более глубокое понимание и способности обработки табличных данных для обеспечения надежных прогностических результатов.
Исследование показывает, насколько сильна способность крупных языковых моделей в большинстве задач табличных данных. Эти модели продемонстрировали заметное улучшение в понимании и обработке сложных структур данных в функциях, таких как вопросно-ответное моделирование таблиц и семантический анализ таблиц. Авторы иллюстрируют, как языковые модели обеспечивают стандартный рост во всех задачах на более высоких уровнях точности и эффективности, используя предобученные знания и передовые механизмы внимания, устанавливающие новые стандарты моделирования табличных данных во многих приложениях.
В заключение, исследование подчеркивает потенциал, который техники обработки естественного языка имеют для эффективного изменения самой природы анализа табличных данных в присутствии крупных языковых моделей. Систематизируя обзор и категоризацию существующих методов, исследователи предложили очень четкую дорожную карту для будущих разработок в этой области. Предложенные методологии преодолевают внутренние вызовы табличных данных и открывают новые передовые приложения с гарантией актуальности и эффективности, даже при увеличении сложности данных.
«`

















