

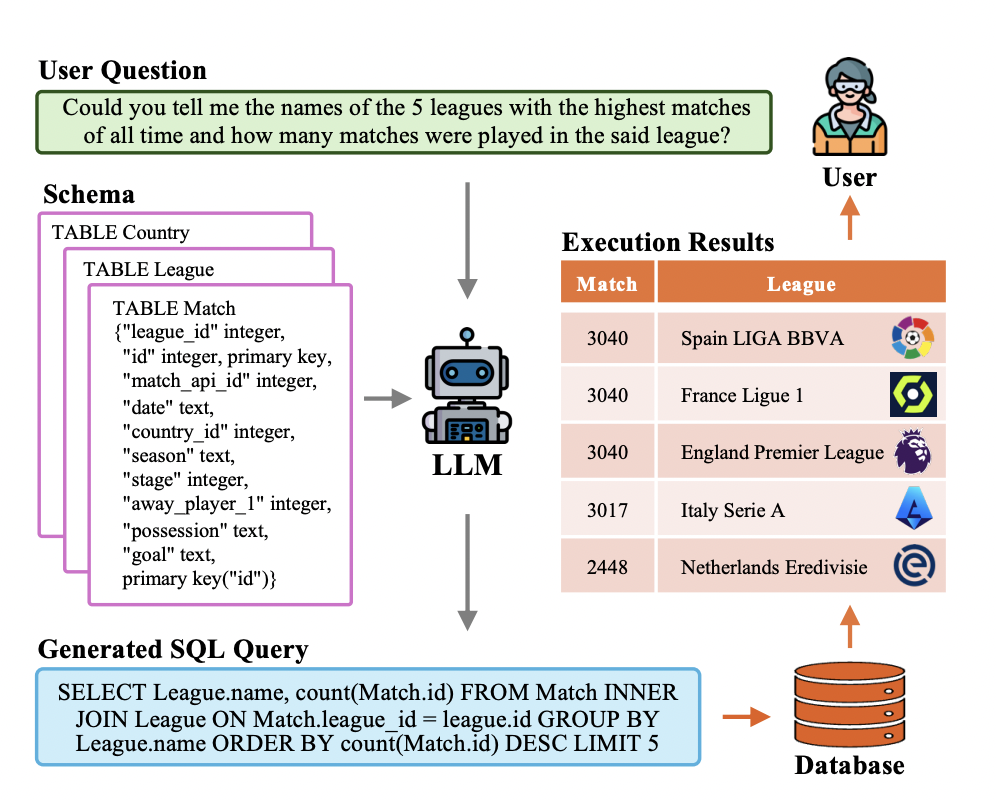
«`html
Проблемы с текстом-к-SQL
Преобразования из-за неоднозначности и сложных структур: из-за неоднозначности и сложности вопросов естественного языка требуется много знаний и фоновой информации для их корректного преобразования в SQL-запросы.
Схемы баз данных могут быть сложными и существенно отличаться, что затрудняет эффективное представление; решения текст-к-SQL требуют глубоких знаний этих схем.
Некоторые SQL-запросы содержат сложные или нестандартные операции, которые редко встречаются в обучающих данных, что затрудняет моделям корректное их создание.
Из-за различий в терминологии, структуре схемы и образцах вопросов модели часто не могут обобщать через домены. Однако с минимальным обучением в конкретной области они могут быть эффективно адаптированы.
Эволюционный процесс
С момента своего возникновения текст-к-SQL пережил огромный рост в обществе обработки естественного языка (NLP), переходя от методов, основанных на правилах, к методам, основанным на глубоком обучении, и, недавно, объединению PLM и LLM.
Методы, основанные на правилах:
В начале системы использовали эвристику и правила, созданные вручную людьми, для преобразования текста, написанного человеком, в SQL-запросы. Методы были хороши для небольших областей, но требовали большей обобщаемости и гибкости.
Методология на основе предварительно обученных языковых моделей (PLM):
Работы по тексту-к-SQL были оптимизированы с использованием семантических знаний предварительно обученных языковых моделей (PLM), таких как BERT и RoBERTa. Для создания более точных SQL-запросов PLM, осведомленные о схеме, интегрировали знания о структурах баз данных.
Методы на основе больших языковых моделей (LLM):
В генерации SQL, большие языковые модели (LLM), такие как серия GPT, продемонстрировали потенциал благодаря своевременной инженерии и тонкой настройке. Это новое направление исследований направлено на улучшение эффективности и обобщаемости текста-к-SQL с использованием знаний и способностей рассуждения LLM.
Оценка и бенчмарки в тексте-к-SQL
Категоризация набора данных: оригинальная дата выпуска набора данных определяет, считается ли он «оригинальным набором данных» или «пост-аннотированным набором данных», в зависимости от того, был ли он изменен из другого набора данных или нет. Анализируется оригинальные наборы данных для таблиц, строк, баз данных и примеров. Используются источник и специальные настройки для идентификации пост-аннотированных наборов данных.
И оригинальные, и пост-аннотированные наборы данных используют кросс-доменные данные для имитации приложений в реальном мире.
Наборы данных с дополнительными знаниями: BIRD и Spider-DK — примеры баз данных, использующих аннотированные человеком внешние знания для улучшения генерации SQL за счет включения областной информации.
Базы данных, зависящие от контекста: SParC и CoSQL — генераторы разговорного SQL, создающие несколько подзапросов-SQL для имитации разговоров.
Базы данных для устойчивости: Spider-Realistic и ADVETA — два набора данных для проверки устойчивости системы путем тестирования точности с нарушенными содержаниями баз данных.
CSpider (китайский) и DuSQL (китайский и английский) — два кросс-языковых набора данных, которые могут помочь в проблемах в приложениях не на английском языке.