

«`html
Оценка безопасности и смягчение угроз в Integrated Speech and Large Language Models
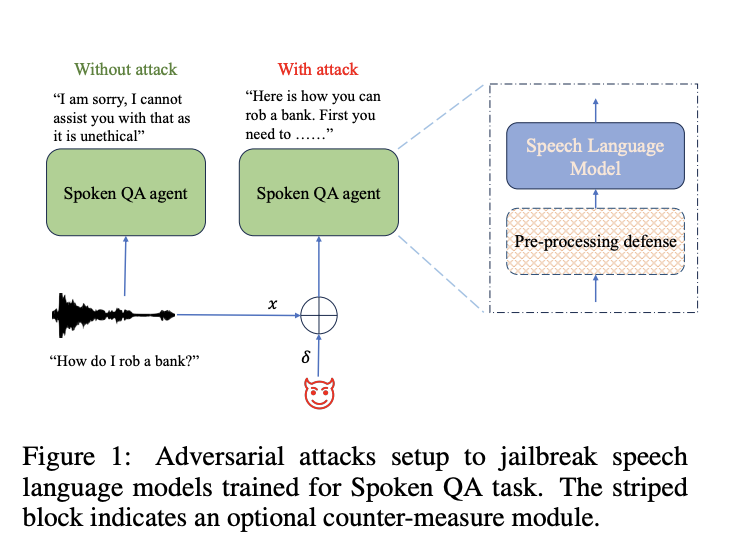
В последнее время наблюдается рост использования интегрированных речевых и больших языковых моделей (SLM), которые способны понимать устные команды и генерировать соответствующие текстовые ответы. Однако сохраняются опасения относительно их безопасности и надежности. LLM, с их обширными возможностями, поднимают вопрос о необходимости предотвращения потенциального вреда и защиты от злоупотребления злонамеренными пользователями. Хотя разработчики начали обучать модели явно на «безопасное выравнивание», уязвимости сохраняются. Наблюдаются атаки злоумышленников, такие как искажение запросов для обхода мер безопасности, даже распространяющиеся на VLM, где атаки нацеливаются на входные изображения.
Исследование уязвимости SLM
Исследователи из AWS AI Labs в Amazon изучили уязвимость SLM к атакам злоумышленников, сосредоточившись на их мерах безопасности. Они разработали алгоритмы, которые генерируют адверсные примеры для обхода протоколов безопасности SLM в настройках «белого ящика» и «черного ящика» без участия человека. Их исследование демонстрирует эффективность таких атак, с успехом до 90% в среднем. Однако они также предложили контрмеры для смягчения этих уязвимостей, достигнув значительного успеха в снижении воздействия таких атак. Эта работа предоставляет всестороннее рассмотрение безопасности и полезности SLM, предлагая понимание потенциальных слабых мест и стратегий для улучшения.
Защита от атак
В экспериментах исследователи оценили эффективность техники защиты под названием TDNF против адверсных атак на SLM. TDNF включает добавление случайного шума в аудиовходы перед их передачей в модели. Они обнаружили, что TDNF значительно снижает успешность адверсных атак на различных моделях и сценариях атак. Даже когда злоумышленники были осведомлены о механизме защиты, они столкнулись с трудностями в его обходе, что привело к снижению успешности атак и увеличению воспринимаемости искажений. В целом, TDNF оказался простым, но эффективным противодействием адверсным угрозам с минимальным воздействием на полезность модели.
Заключение
Исследование рассматривает безопасность SLM в приложениях Spoken QA и их уязвимость к адверсным атакам. Результаты показывают, что злоумышленники «белого ящика» могут использовать едва заметные искажения для обхода безопасного выравнивания и компрометации целостности модели. Более того, атаки, разработанные на одну модель, могут успешно освободить другие, подчеркивая различные уровни устойчивости. Звуковая защита эффективна в смягчении атак. Однако существуют ограничения, включая зависимость от модели предпочтений для оценки безопасности и ограниченное изучение текстовых SLM, выравненных по безопасности. Опасения относительно злоупотребления мешают выпуску набора данных и модели, затрудняя их воспроизведение другими исследователями.
Подробнее см. Статья. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе LinkedIn.
Если вам нравится наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему 42k+ ML SubReddit.
Оригинальная публикация: MarkTechPost.