

«`html
LLM Эффективность и Продуктивность: Практические Решения
Проблемы и Решения
LLM (Large Language Models) отлично справляются с обработкой естественного языка, но сталкиваются с проблемами при развертывании из-за высоких вычислительных и памяти требований во время вывода. Недавние исследования [MWM+24, WMD+23, SXZ+24, XGZC23, LKM23] направлены на повышение эффективности LLM путем квантизации, обрезки, дистилляции и улучшения декодирования.
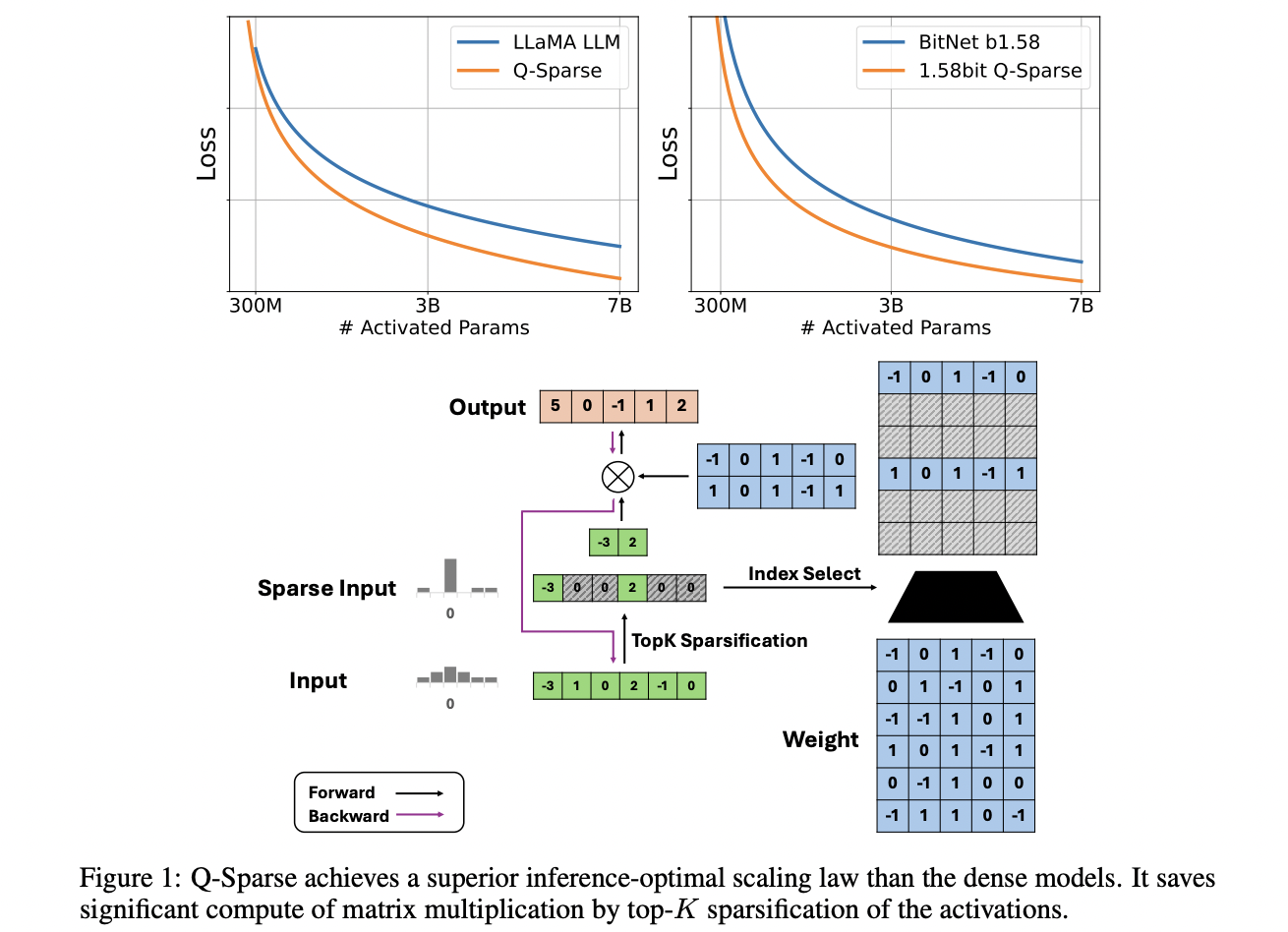
Решение: Q-Sparse, эффективный подход для обучения разреженно-активированных LLM, позволяет полную разреженность активации, существенно повышая эффективность вывода.
Преимущества и Особенности Q-Sparse
Q-Sparse обеспечивает полную разреженность активации, снижая вычислительные расходы и объем памяти. Он поддерживает модели полной точности и квантованные модели, включая 1-битные модели. Кроме того, Q-Sparse эффективен для обучения с нуля, продолжения обучения и тонкой настройки, обеспечивая эффективность и производительность в различных сценариях.
Эффективность и Практичность
Q-Sparse показывает сопоставимую производительность с плотными базовыми моделями, улучшая эффективность вывода через разреженность активации и оценщик прямого прохода. Он эффективен в различных сценариях и совместим с моделями полной точности и 1-битными моделями, что делает его ключевым подходом для повышения эффективности и устойчивости LLM.
Подробнее о статье можно узнать здесь.
Все авторские права на это исследование принадлежат его авторам. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу на Reddit.