

«`html
Искусственный интеллект в обработке временных рядов: новые возможности и практические решения
Искусственный интеллект стремительно развивается, с особым вниманием к улучшению моделей обработки и интерпретации сложных наборов данных, в частности временных рядов. Этот тип данных представляет собой последовательности точек данных, собранных во времени, и имеет важное значение в различных областях, включая финансы, здравоохранение и экологию. Возможность точного прогнозирования и классификации временных рядов может привести к более обоснованным решениям и лучшим результатам в этих областях.
Основные проблемы и практические решения
Одной из основных проблем обучения на последовательностях является работа с высокоразмерными шумными данными, которые часто сложно интерпретировать и обрабатывать. Традиционные модели машинного обучения нуждаются в помощи для извлечения значимых закономерностей из таких данных, что приводит к неоптимальным прогнозам и классификации. Эта проблема особенно остро проявляется в анализе временных рядов, где понимание порядка и взаимосвязи между точками данных критично.
Существующие методы анализа временных рядов, такие как Dynamic Time Warping (DTW) и традиционные Tsetlin Machines (TMs), имеют свои преимущества и недостатки. DTW широко используется для измерения сходства между последовательностями, но требует значительных вычислительных ресурсов и может быть сложен в реализации на больших наборах данных. Tsetlin Machines, известные своей простотой и интерпретируемостью, предлагают другой подход, но требуют настройки параметров для достижения оптимальной производительности. Эти ограничения подчеркивают необходимость более продвинутых и эффективных методов для работы с широким спектром задач обучения на последовательностях.
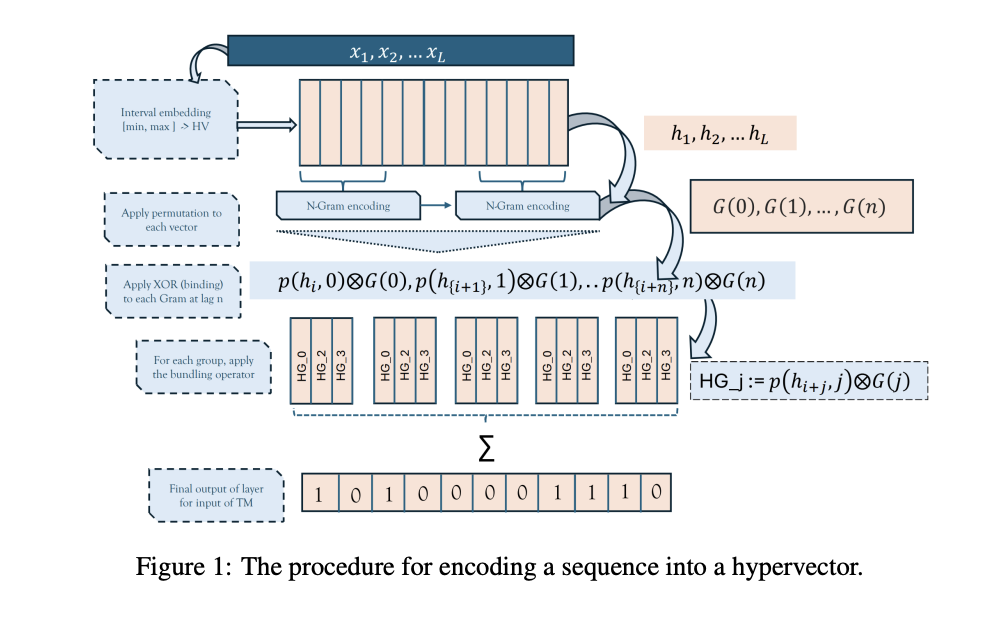
Исследователи из Университета Агдера представили новый подход, который объединяет Hyperdimensional Vector Computing (HVC) с Tsetlin Machines. Эта гибридная модель использует преимущества HVC в высокоразмерных пространствах с возможностями интерпретации и обучения Tsetlin Machines. Исследовательская группа разработала систему, которая кодирует последовательности в гиперразмерные векторы, эффективно отображая временные и пространственные взаимосвязи в данных. Этот инновационный подход направлен на создание более мощного и эффективного инструмента для обучения и генерации последовательностей.
Метод, предложенный исследователями, включает кодирование последовательностей в гиперразмерные векторы, которые затем обрабатываются Tsetlin Machines. Модель использует операции, такие как связывание, пакетирование и возмущение в гиперразмерном векторном пространстве для представления и анализа последовательностей. Этот подход позволяет системе генерировать новые последовательности, сохраняя характеристики исходных данных и при этом требуя минимальных вычислительных ресурсов. Например, модель может закодировать последовательность временных рядов в гиперразмерный вектор из 10 000 бит, требуя всего 1,22 МБ памяти, даже при масштабировании для обработки больших наборов данных.
Результаты и перспективы
Гибридная модель была тщательно протестирована на UCR Time Series Classification Archive, включающем 128 различных наборов данных временных рядов. Результаты были впечатляющими: модель превзошла или соответствовала современным стандартам в приблизительно 78% наборов данных. Исследователи сообщили, что метод HVTM достиг улучшения точности или поддержания конкурентоспособности в пределах 2% по сравнению с оптимальными стандартами, предоставленными методами на основе DTW. В частности, модель проявила себя в наборах данных, связанных с движением, изображениями и ЭКГ, превзойдя стандарты DTW как минимум на 60% в этих категориях. Однако она столкнулась с трудностями при очень коротких последовательностях (24-80 точек данных) и продемонстрировала сопоставимую производительность с DTW для средних последовательностей (277-500 точек данных).
Гибридная модель продемонстрировала высокую производительность в задачах прогнозирования. Исследователи экспериментировали с детерминированными и стохастическими моделями временных рядов, включая гармонические ряды, AR(1), ARMA(1,1) и сезонные AR модели. Эксперименты по прогнозированию включали генерацию прогнозов на 24 шага вперед, где HVTM продемонстрировала среднюю ошибку около 4% при 5-граммовом кодировании гармонических рядов. Ошибки для моделей AR(1) с коэффициентами 0,4 и 0,7 составили около 15% и 14% соответственно. Сезонные AR модели, представляющие более значительные трудности, имели ошибки примерно 31%, отражая сложность захвата сезонных закономерностей.
В заключение, исследование Университета Агдера в области обучения на последовательностях представляет гибридную модель, объединяющую Hyperdimensional Vector Computing с Tsetlin Machines. Этот подход улучшает точность и эффективность анализа временных рядов, делая его многообещающим инструментом для многих приложений. Возможность модели обрабатывать сложные наборы данных с минимальными требованиями к памяти делает ее подходящей для внедрения в ресурсоемких средах. По мере того как исследователи продолжают совершенствовать и расширять свой подход, эта гибридная модель может стать ценной альтернативой более ресурсоемким методам, открывая новые перспективы для будущего использования ИИ в обучении на последовательностях.
«`

















