

«`html
Оценка моделей искусственного интеллекта
Оценка моделей искусственного интеллекта, особенно больших языковых моделей (LLM), является быстро развивающейся областью исследований. Исследователи сосредоточены на разработке более строгих бенчмарков для оценки возможностей этих моделей в широком спектре сложных задач. Это важно для продвижения технологий искусственного интеллекта, поскольку предоставляет понимание сильных и слабых сторон различных систем искусственного интеллекта. Понимая эти аспекты, исследователи могут принимать обоснованные решения по улучшению и совершенствованию этих моделей.
Проблема оценки LLM
Одной из значительных проблем при оценке LLM является недостаточность существующих бенчмарков в полной мере отражать возможности моделей. Традиционные бенчмарки, такие как исходный набор данных Massive Multitask Language Understanding (MMLU), часто не предоставляют всестороннюю оценку. Эти бенчмарки обычно включают ограниченные варианты ответов и в основном фокусируются на вопросах, связанных с знаниями, которые не требуют обширного рассуждения. Это подчеркивает необходимость более сложных и всеобъемлющих наборов данных, способных лучше оценивать разнообразные возможности этих передовых систем искусственного интеллекта.
Новый набор данных MMLU-Pro
Исследователи из TIGER-Lab представили набор данных MMLU-Pro для решения этих ограничений. Этот новый набор данных разработан для предоставления более строгого и всестороннего бенчмарка для оценки LLM. MMLU-Pro значительно увеличивает количество вариантов ответов с четырех до десяти на каждый вопрос, улучшая сложность и реализм оценки. Включение большего количества вопросов, сфокусированных на рассуждениях, адресует недостатки исходного набора данных MMLU. Этот процесс включает ведущие исследовательские лаборатории по искусственному интеллекту и академические учреждения с целью установления нового стандарта в оценке искусственного интеллекта.
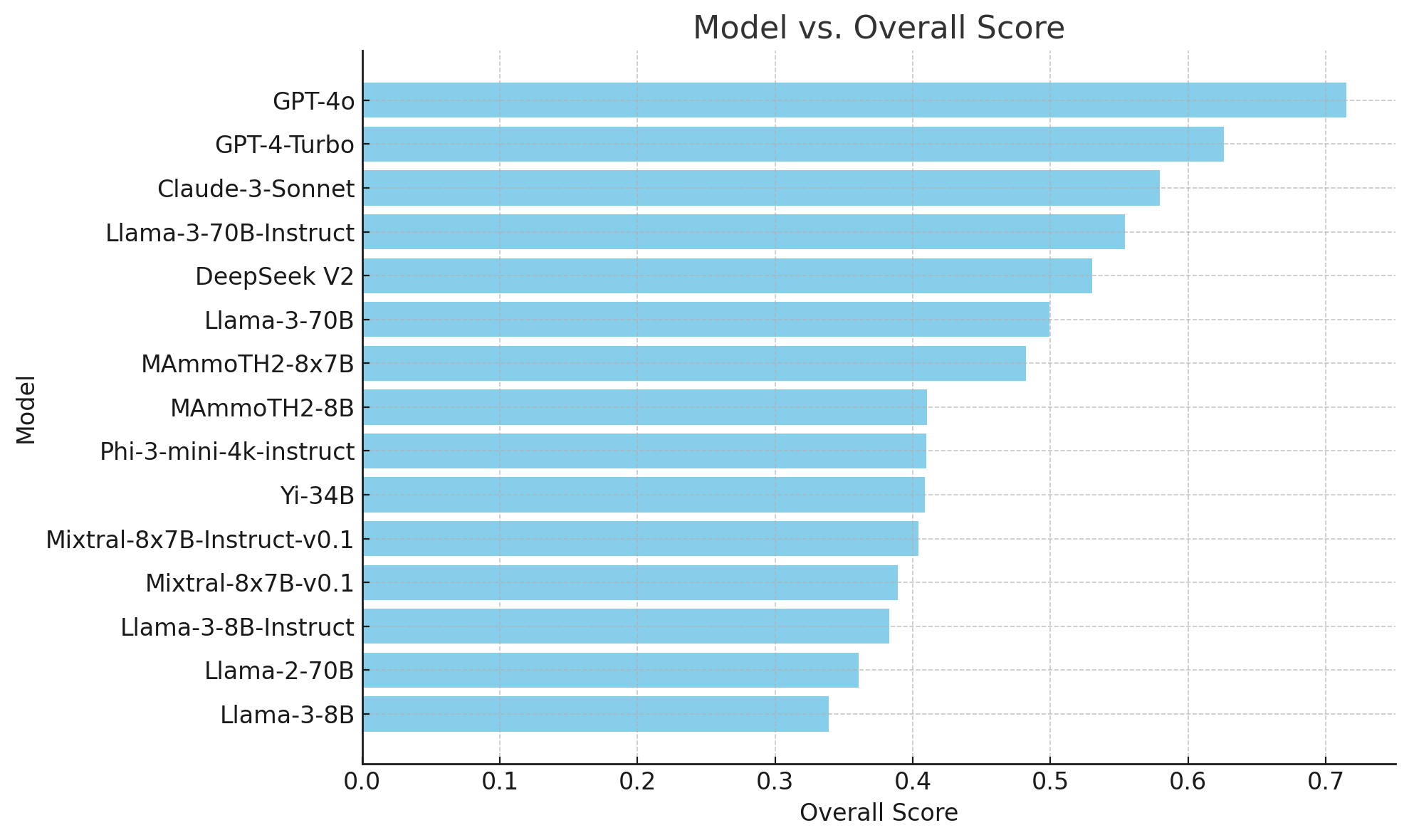
Результаты и значимость
Оценка производительности различных моделей искусственного интеллекта на наборе данных MMLU-Pro показала значительные различия по сравнению с исходными оценками MMLU. Это подчеркивает сложность MMLU-Pro, требующую более глубоких рассуждений и навыков решения проблем от моделей. Новый набор данных MMLU-Pro представляет собой значительное достижение в оценке искусственного интеллекта, предлагая более строгий бенчмарк, который вызывает LLM сложными вопросами, сфокусированными на рассуждениях.
Применение искусственного интеллекта в продажах и маркетинге
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте TIGER-Lab Introduces MMLU-Pro Dataset for Comprehensive Benchmarking of Large Language Models’ Capabilities and Performance.
Практические рекомендации
1. Проанализируйте, как ИИ может изменить вашу работу и определите моменты, когда ваши клиенты могут извлечь выгоду из AI.
2. Определите ключевые показатели эффективности (KPI), которые вы хотите улучшить с помощью ИИ.
3. Подберите подходящее решение из множества вариантов ИИ и внедряйте его постепенно, начиная с малого проекта и анализируя результаты и KPI.
4. Используйте AI Sales Bot для автоматизации ответов на вопросы клиентов, генерации контента и снижения нагрузки на первую линию.
5. Получайте советы по внедрению ИИ, следите за новостями о ИИ в нашем Телеграм-канале и на Twitter.