

«`html
Интеллектуальный ассистент для продаж и маркетинга
Мы помогаем компаниям использовать потенциал искусственного интеллекта (ИИ) для развития и оставания в числе лидеров на рынке
Искусственный интеллект, особенно в обучении больших мультимодальных моделей (LMM), сильно зависит от обширных наборов данных, которые включают последовательности изображений и текста. Они обеспечивают разработку сложных моделей, способных понимать и создавать мультимодальный контент. По мере усовершенствования возможностей ИИ-моделей возникает необходимость в обширных и высококачественных наборах данных, стимулируя исследователей к поиску новых методов сбора и обработки данных.
Одной из ключевых проблем в исследованиях в области ИИ является нехватка крупномасштабных, открытых, мультимодальных переплетенных наборов данных. Такие наборы данных необходимы для обучения моделей, без проблем интегрирующих текстовые и графические данные. Ограниченная доступность таких наборов данных затрудняет разработку надежных и высокопроизводительных открытых моделей, что приводит к разрыву в производительности между открытыми и закрытыми моделями. Решение этой проблемы требует инновационных подходов к созданию наборов данных, обеспечивающих необходимый масштаб и разнообразие.
Существующие методы создания мультимодальных наборов данных часто включают сбор и обработку данных из HTML-документов. Заметные наборы данных, такие как OBELICS, были инструментальны, но они ограничены по масштабу и разнообразию, в основном получая данные из HTML. Это ограничение влияет на разнообразие и качество данных, воздействуя на производительность и применимость результирующих ИИ-моделей. Исследователи нашли, что наборы данных, полученные исключительно из HTML-документов, должны улавливать полный спектр требуемого мультимодального контента для комплексного обучения моделей.
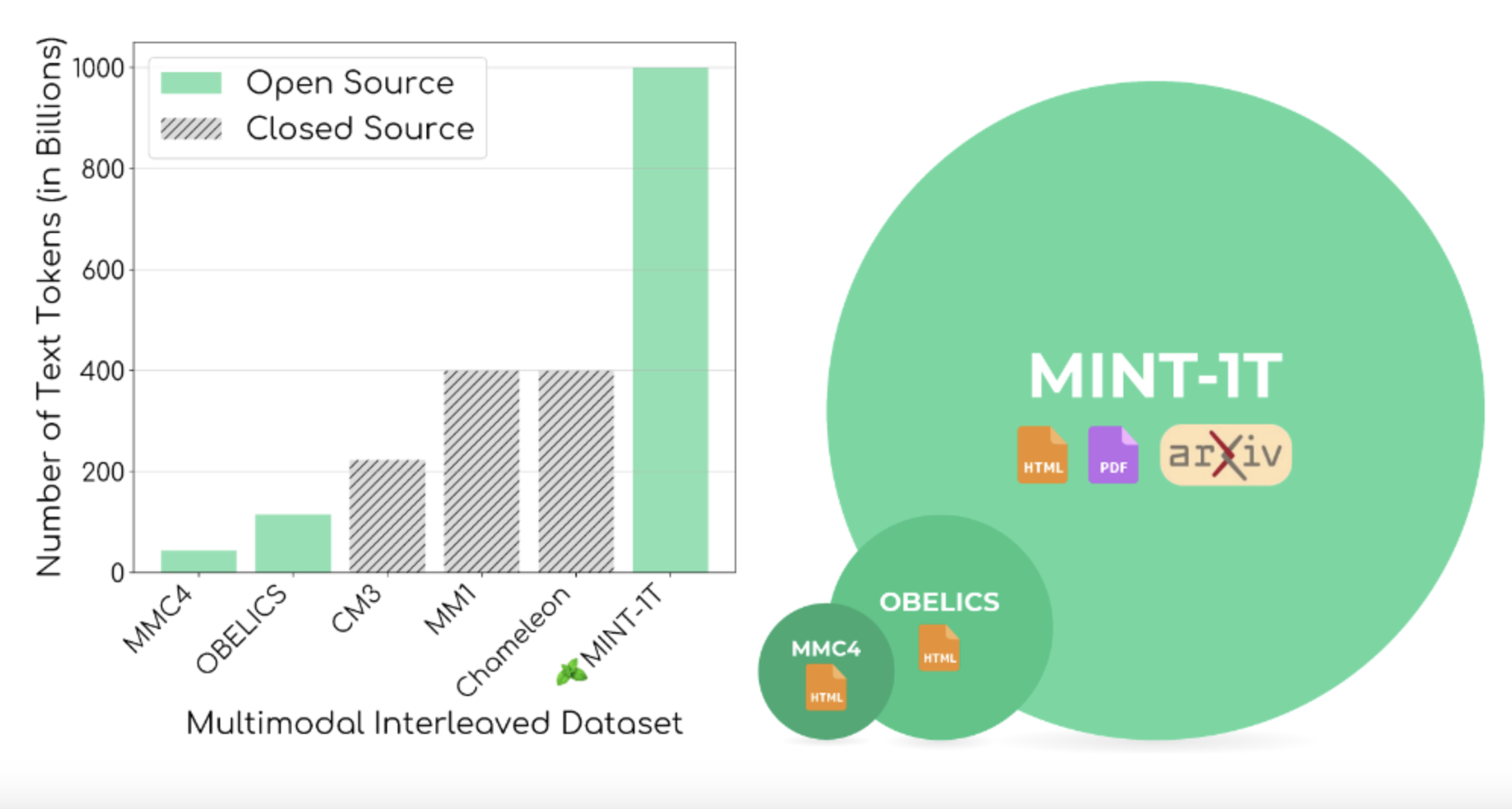
Исследователи из Университета Вашингтона, Salesforce Research, Стэнфордского университета, Университета Техаса в Остине и Университета Калифорнии в Беркли представили MINT-1T, наиболее обширный и разнообразный открытый мультимодальный переплетенный набор данных на сегодняшний день, отвечающий потребности в более крупных и разнообразных наборах данных. MINT-1T включает в себя один триллион текстовых токенов и 3,4 миллиарда изображений из HTML, PDF и научных статей ArXiv. Этот набор данных представляет собой увеличение в десять раз по сравнению с предыдущими наборами, значительно улучшая данные для обучения мультимодальных моделей. Университет Вашингтона и Salesforce Research сотрудничали в рамках этой инициативы, демонстрируя совместные усилия по замости разрыва в доступности наборов данных.
Создание набора данных MINT-1T включало тщательный процесс сбора, фильтрации и удаления дубликатов данных. HTML-документы были расширены для включения данных из более ранних лет, а PDF-файлы обрабатывались для извлечения читаемого текста и изображений. Научные статьи ArXiv были разбираются на изображения и текст с целью получения комплексной коллекции мультимодального контента. Для удаления низкокачественного, неанглоязычного и несоответствующего контента были использованы передовые методы фильтрации. Также были реализованы процессы удаления дубликатов для обеспечения качества и разнообразия набора данных.
Эксперименты показали, что LMM, обученные на наборе данных MINT-1T, соответствовали и часто превосходили производительность моделей, обученных на предыдущих ведущих наборах данных, таких как OBELICS. Включение более разнообразных источников в MINT-1T привело к лучшей обобщенности и производительности по различным показателям. Особенно стоит отметить, что набор данных значительно улучшил производительность в задачах визуального ответа на вопросы и мультимодального рассуждения. Исследователи обнаружили, что модели, обученные на MINT-1T, показывали лучшую производительность в различных демонстрациях, подчеркивая эффективность набора данных.
При создании набора данных MINT-1T были предприняты детальные шаги для обеспечения качества и разнообразия данных. Например, в набор данных вошли 922 миллиарда токенов HTML, 106 миллиардов токенов PDF и 9 миллиардов токенов ArXiv. В ходе процесса фильтрации удалялись документы с неподходящим контентом и неанглоязычные тексты, применялись инструменты, такие как Fasttext для идентификации языка и NSFW-детекторы для изображений. Процесс удаления дубликатов был крайне важен и включал использование битовых фильтров для устранения повторяющихся параграфов и документов, а также хэширование для удаления повторяющихся изображений.
В заключение, набор данных MINT-1T решает проблему нехватки разнообразных наборов данных. Представляя больший и более разнообразный набор данных, исследователи обеспечили разработку более надежных и высокопроизводительных открытых мультимодальных моделей. Эта работа подчеркивает важность разнообразия и масштаба данных в исследованиях в области ИИ и прокладывает путь для будущих улучшений и применений в области мультимодального ИИ. Обширный масштаб набора данных, включающий один триллион текстовых токенов и 3,4 миллиарда изображений, обеспечивает прочное основание для продвижения возможностей ИИ.
Подробнее о научной статье, деталях и GitHub можете узнать здесь. Вся заслуга за это исследование принадлежит ученым, участвующим в этом проекте.
Также не забудьте подписаться на наш Telegram-канал и следить за новостями в Twitter @itinairu45358.
Не забудьте присоединиться к нашему 47k+ ML SubReddit
Узнайте о предстоящих вебинарах по ИИ здесь
Важно! Новость о наборе данных! Один триллион токенов. Мультимодальный. Переплетенный. Открытый источник. Идеально подходит для обучения мультимодальных моделей и их предварительного обучения. Попробуйте прямо сегодня!
Блог: https://t.co/e36YvEBrcP
Набор данных: https://t.co/FHKhkAURdN

«`


















