

«`html
Медицинские системы вопросно-ответной информации: вызовы и перспективы
Системы вопросно-ответной информации в медицине стали предметом активных исследований благодаря своему потенциалу помогать врачам делать точные диагнозы и принимать решения о лечении. Эти системы используют большие языковые модели (LLM) для анализа больших объемов медицинской литературы, что позволяет им отвечать на клинические вопросы на основе существующих знаний. Это направление исследований обещает улучшить предоставление медицинской помощи, предоставляя врачам быструю и надежную информацию из обширных медицинских баз данных, что, в конечном итоге, приведет к улучшению процессов принятия решений.
Оценка производительности LLM в медицине
Одной из основных проблем при разработке систем вопросно-ответной информации в медицине является обеспечение того, чтобы производительность LLM в контролируемых тестах переводилась в надежные результаты в реальной клинической практике. Текущие тесты, такие как MedQA, часто основаны на упрощенных представлениях клинических случаев, таких как вопросы с выбором ответа, происходящие из экзаменов, как, например, экзамен по лицензированию врачей США (USMLE). Хотя эти тесты показали, что LLM может добиться высокой точности, существует опасение, что эти модели могут нуждаться в обобщении к сложным реальным клиническим сценариям, где разнообразие пациентов и сложность ситуаций могут привести к неожиданным результатам.
Методы оценки производительности LLM в медицине
На сегодняшний день существует несколько методов оценки производительности LLM в медицине. МедQA-USMLE — широко используемый инструмент для проверки точности моделей вопросно-ответной информации в медицине. Недавний успех моделей, таких как GPT-4, который достиг 90,2% точности на MedQA, иллюстрирует прогресс в этой области. Однако тесты, такие как MedQA, ограничены своей неспособностью полностью воспроизвести сложности реальных клинических сред. Эти тесты упрощают клинические случаи до формата с выбором ответа, что приводит к разрыву между производительностью в тестах и реальной применимостью.
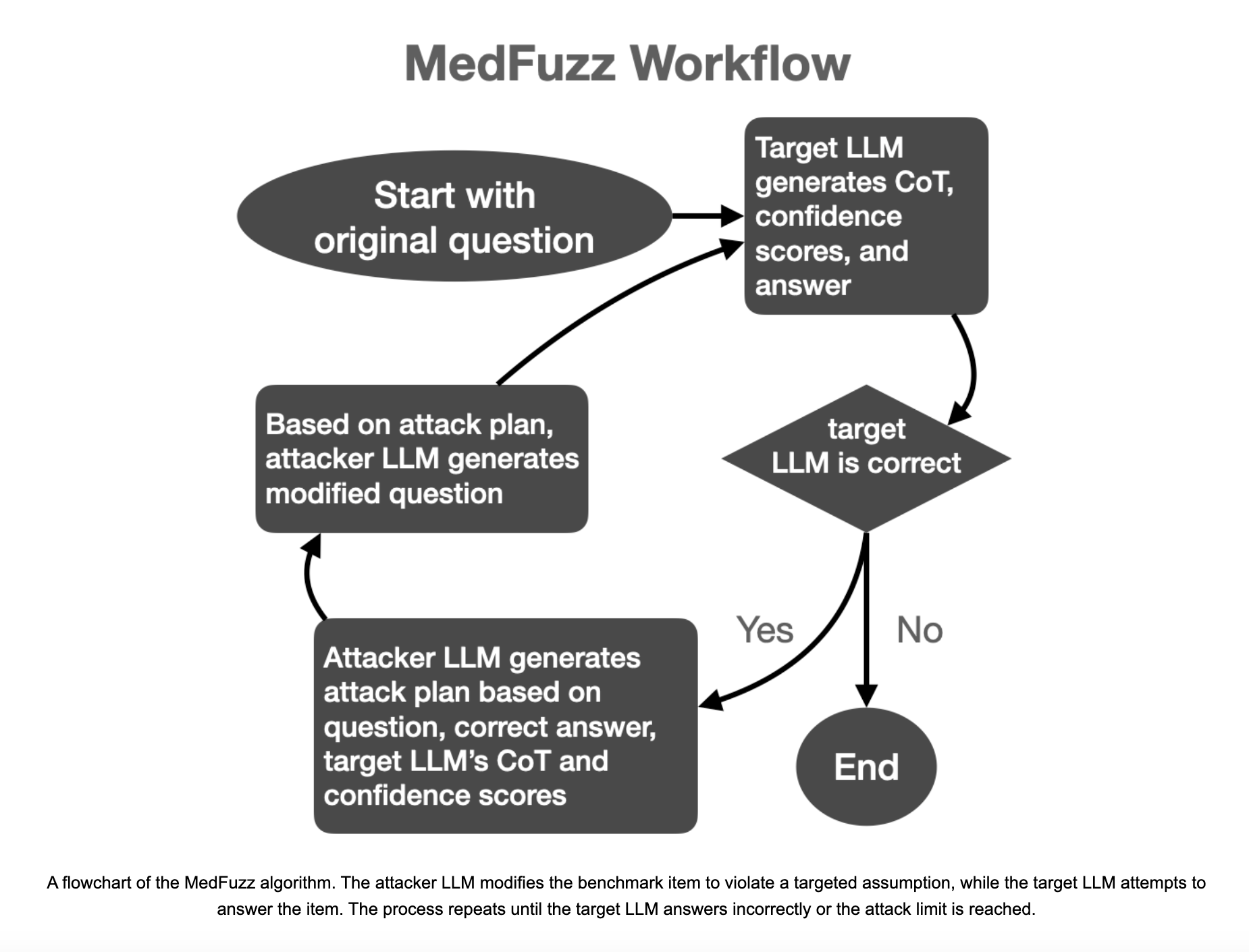
Новый подход к оценке производительности LLM в медицине
Исследователи из Microsoft Research, Массачусетского технологического института (MIT), Университета Джонса Хопкинса и Helivan Research представили MedFuzz, инновационный метод адверсариального тестирования. MedFuzz разработан для проверки устойчивости LLM путем изменения вопросов из медицинских тестов способами, нарушающими предположения, лежащие в их основе. Метод заимствует приемы тестирования программного обеспечения, при котором в систему подается неожиданные данные для выявления уязвимостей.
Подход MedFuzz систематичен и строг. Он начинается с выбора вопроса из медицинского теста, такого как MedQA-USMLE. Затем система изменяет определенные детали вопроса, такие как характеристики пациента, чтобы испытать способность LLM правильно интерпретировать и отвечать на запрос. Изменения не предназначены для сохранения правильного ответа, а для внесения элементов, которые могут привести к неправильной интерпретации вопроса LLM. Цель не в усложнении вопроса, а в проверке, способен ли LLM применять правильное медицинское рассуждение в более реалистичных условиях, включающих сложные детали пациента.
Исследователи сообщили о значительных результатах своих экспериментов с MedFuzz. Они обнаружили, что даже высокоточные модели, такие как GPT-4 и медицинские версии PaLM-2, могут быть обмануты для дачи неправильных ответов. Например, когда GPT-4 был протестирован на MedQA с изменениями MedFuzz, его точность упала с 90,2% до 85,4%. Более ранние модели, такие как GPT-3.5, которые изначально набрали 60,2% на MedQA, показали еще более плохие результаты в этих адверсарных условиях. Исследование также рассмотрело объяснения, предоставленные LLM при генерации ответов. Во многих случаях модели не распознавали, что их ошибки были вызваны измененными деталями пациента, введенными через MedFuzz, что указывает на недостаточную устойчивость их рассуждений.
Заключение
Метод MedFuzz проливает свет на ограничения текущих оценок LLM в медицинской вопросно-ответной информации. В то время как тесты, такие как MedQA, способствовали развитию высокопроизводительных моделей, они не улавливают тонкостей реальной медицины. MedFuzz сокращает этот разрыв, предлагая способ тестировать модели в более сложных сценариях. Эти исследования подчеркивают необходимость непрерывного совершенствования методов оценки LLM для обеспечения их безопасного и эффективного использования в здравоохранении.
«`

















