

EMOVA: Новая Omni-Modal LLM для Бесшовной Интеграции Видения, Языка и Речи
Практические Решения и Ценность
Omni-модальные большие языковые модели (LLM) находятся во главе исследований искусственного интеллекта, стремясь объединить несколько модальностей данных, таких как видение, язык и речь. Основная цель — улучшить интерактивные возможности этих моделей, позволяя им воспринимать, понимать и генерировать выводы на различных входах, как это делал бы человек. Эти достижения критически важны для создания более комплексных систем искусственного интеллекта для участия в естественных взаимодействиях, реагирования на визуальные подсказки, интерпретации вокальных инструкций и предоставления последовательных ответов в текстовом и речевом форматах.
Несмотря на прогресс в отдельных модальностях, существующим моделям искусственного интеллекта нужна помощь в интеграции возможностей видения и речи в единый каркас. Текущие модели либо сосредоточены на видение-языке, либо на рече-языке, часто не достигая безшовного понимания всех трех модальностей одновременно. Это ограничение затрудняет их применение в сценариях, требующих реального времени взаимодействия, таких как виртуальные ассистенты или автономные роботы. Дополнительно, текущие речевые модели сильно зависят от внешних инструментов для генерации вокальных выводов, что вводит задержку и ограничивает гибкость в управлении стилем речи. Вызов заключается в создании модели, способной преодолеть эти барьеры, сохраняя при этом высокую производительность в понимании и генерации мультимодального контента.
Ряд подходов был принят для улучшения мультимодальных моделей. Модели видение-язык, такие как LLaVA и Intern-VL, используют видео-кодеры для извлечения и интеграции визуальных особенностей с текстовыми данными. Речевые модели, такие как Whisper, используют речевые кодеры для извлечения непрерывных особенностей, позволяя модели понимать вокальные входы. Однако эти модели ограничены своей зависимостью от внешних инструментов Text-to-Speech (TTS) для генерации речевых ответов. Этот подход ограничивает способность модели генерировать речь в реальном времени и с эмоциональными вариациями. Более того, попытки создания омни-модальных моделей, таких как AnyGPT, полагаются на дискретизацию данных, что часто приводит к потере информации, особенно в визуальных модальностях, уменьшая эффективность модели на задачах с высоким разрешением.
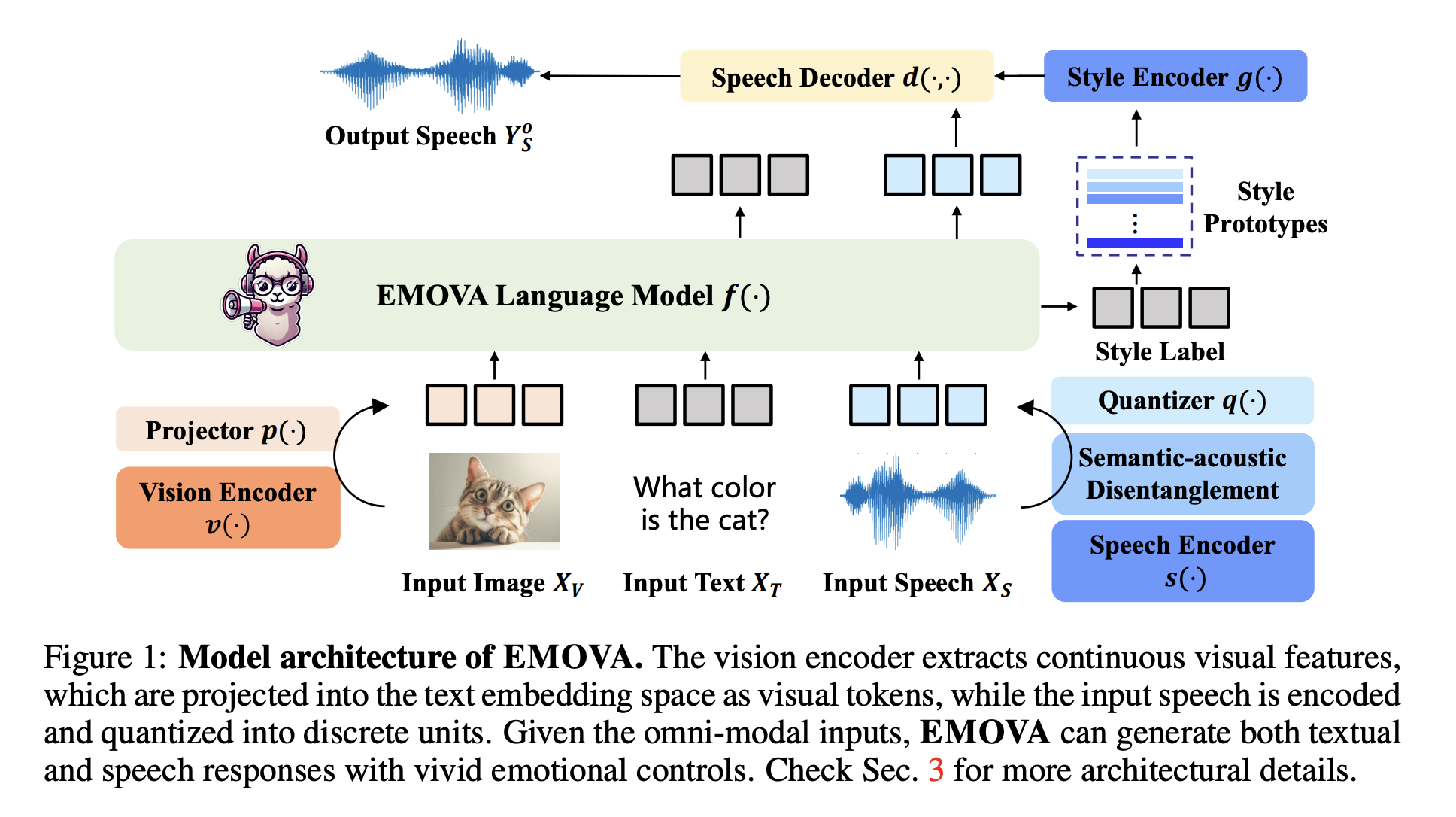
Исследователи из Гонконгского университета науки и технологий, Гонконгского университета, Лаборатории Huawei Noah’s Ark, Китайского университета Гонконга, Университета Сунь Ятсена и Южного университета науки и технологий представили EMOVA (Emotionally Omni-present Voice Assistant). Эта модель представляет собой значительное достижение в исследованиях LLM, путем бесшовного объединения возможностей видения, языка и речи. Уникальная архитектура EMOVA включает непрерывный видео-кодер и токенизатор речи-на-единицу, позволяя модели выполнять обработку речи и визуальных входов end-to-end. Используя семантически-акустический декомпозиционный токенизатор речи, EMOVA разделяет семантическое содержание (что говорится) от акустического стиля (как это сказано), позволяя ей генерировать речь с различными эмоциональными оттенками. Эта функция критически важна для систем реального времени разговорной речи, где способность выражать эмоции через речь добавляет глубину взаимодействиям.
Модель EMOVA включает несколько компонентов, разработанных для эффективной работы с конкретными модальностями. Видео-кодер захватывает высокоразрешенные визуальные особенности, проецируя их в пространство встраивания текста, тогда как речевой кодер преобразует речь в дискретные единицы, которые может обрабатывать LLM. Ключевым аспектом модели является механизм семантически-акустического декомпозиции, который разделяет смысл сказанного контента от его стилевых атрибутов, таких как высота или эмоциональный тон. Это позволяет исследователям ввести легкий стилевой модуль для управления речевыми выводами, делая EMOVA способной выражать различные эмоции и персонализированные стили речи. Кроме того, интеграция текстовой модальности в качестве моста для выравнивания изображения и речевых данных устраняет необходимость в специализированных омни-модальных наборах данных, которые часто сложно получить.
Производительность EMOVA была оценена на нескольких бенчмарках, демонстрируя ее превосходные возможности по сравнению с существующими моделями. На задачах речь-язык EMOVA достигла замечательной точности 97%, превзойдя другие передовые модели, такие как AnyGPT и Mini-Omni на 2.8%. На задачах видение-язык EMOVA набрала 96% на наборе данных MathVision, превзойдя конкурирующие модели, такие как Intern-VL и LLaVA на 3.5%. Более того, способность модели поддерживать высокую точность как в задачах речи, так и в задачах видения одновременно является беспрецедентной, поскольку большинство существующих моделей обычно преуспевают в одной модальности за счет другой. Эта комплексная производительность делает EMOVA первой LLM, способной поддерживать эмоционально насыщенные, реальном времени разговорные диалоги, достигая передовых результатов в нескольких областях.
В заключение, EMOVA закрывает критическую пропасть в интеграции возможностей видения, языка и речи в рамках одной модели искусственного интеллекта. Через инновационный механизм семантически-акустической декомпозиции и эффективную стратегию омни-модального выравнивания, она не только проявляет себя исключительно хорошо на стандартных бенчмарках, но и вводит гибкость в управлении эмоциональной речью, делая ее универсальным инструментом для продвинутых взаимодействий с искусственным интеллектом. Этот прорыв проложил путь для дальнейших исследований и разработок в области крупных омни-модальных языковых моделей, устанавливая новый стандарт для будущих достижений в этой области.



















