

«`html
Преимущества автономного обучения с подкреплением DigiRL для обучения агентов управления устройствами
Продвижения в моделях зрение-язык (VLM) продемонстрировали впечатляющие способности к здравому смыслу, рассуждению и обобщению. Это означает, что разработка полностью автономного цифрового ИИ-ассистента, способного выполнять повседневные компьютерные задачи на естественном языке, возможна. Однако лучшие способности рассуждения и здравого смысла не автоматически приводят к интеллектуальному поведению ассистента. Ассистенты ИИ используются для выполнения задач, рационального поведения и исправления ошибок, а не просто для предоставления правдоподобных ответов на основе предварительных данных обучения. Поэтому требуется метод превращения способностей предварительного обучения в практических ИИ-агентов.
Тренировка мульти-модальных цифровых агентов
Первый метод — тренировка мульти-модальных цифровых агентов, который сталкивается с вызовами, такими как управление устройствами, выполняемое непосредственно на уровне пикселей в пространстве действий на основе координат, а также стохастический и непредсказуемый характер экосистем устройств и Интернета.
Среды для агентов управления устройствами
Второй метод — среды для агентов управления устройствами. Эти среды предназначены для оценки и предлагают ограниченный набор задач в полностью детерминированных и стационарных условиях.
Обучение с подкреплением (RL) для LLM/VLM
Последний метод — обучение с подкреплением для LLM/VLM, где исследования с RL для основных моделей фокусируются на одноходовых задачах, таких как оптимизация предпочтений, но оптимизация одноходового взаимодействия на основе экспертных демонстраций может привести к неоптимальным стратегиям для многошаговых проблем.
Результаты исследования
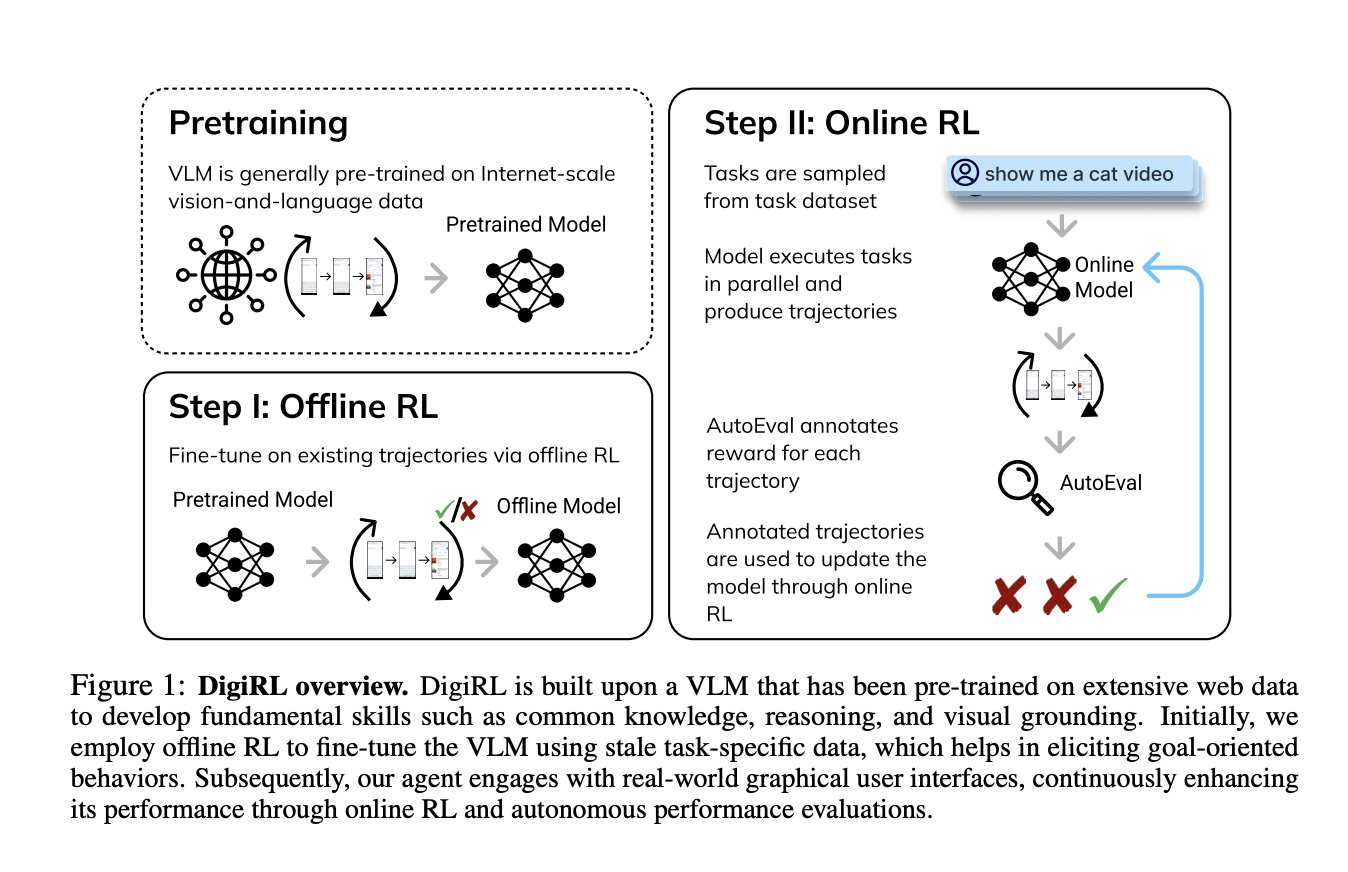
Исследователи из UC Berkeley, UIUC и Google DeepMind представили DigiRL (RL для цифровых агентов), новый автономный метод обучения с подкреплением для тренировки агентов управления устройствами. Полученный агент достигает передовой производительности на нескольких задачах управления устройствами Android. Процесс обучения включает две фазы: сначала начальная фаза оффлайн обучения с использованием существующих данных, затем фаза перехода от оффлайн к онлайн обучению, которая используется для настройки модели, полученной из оффлайн обучения, на онлайн данных. Для обучения онлайн RL была разработана масштабируемая и параллельная среда обучения на Android, которая включает надежный универсальный оценщик (средний уровень ошибок 2.8% по сравнению с человеческим суждением) на основе VLM.
Исследователи провели эксперименты для оценки производительности DigiRL на сложных задачах управления устройствами Android. Важно понять, может ли DigiRL производить агентов, которые могут эффективно учиться через автономное взаимодействие, сохраняя при этом возможность использовать оффлайн данные для обучения. Поэтому был проведен сравнительный анализ DigiRL по следующим пунктам:
- Агенты передовых моделей, построенные на собственных VLM с использованием нескольких техник подсказки и методов извлечения.
- Имитационное обучение на статических человеческих демонстрациях с тем же распределением инструкций.
- Метод фильтрованного клонирования поведения.
Агент, обученный с использованием DigiRL, был протестирован на различных задачах из набора данных Android in the Wild (AitW) с использованием реальных эмуляторов устройств Android. Агент достиг улучшения на 28.7% по сравнению с существующими передовыми агентами (увеличение уровня успешности с 38.5% до 67.2%) 18B CogAgent. Он также превзошел предыдущий лучший метод автономного обучения на основе фильтрованного клонирования поведения более чем на 9%. Более того, несмотря на наличие всего 1.3 млрд параметров, агент показал более высокую производительность, чем передовые модели, такие как GPT-4V и Gemini 1.5 Pro (успешность 17.7%). Это делает его первым агентом, достигшим передовой производительности в управлении устройствами с использованием автономного метода обучения с переходом от оффлайн к онлайн RL.
В заключение, исследователи предложили DigiRL, новый автономный метод обучения с подкреплением для тренировки агентов управления устройствами, который устанавливает новый уровень передовой производительности на нескольких задачах управления устройствами Android из набора данных AitW. Была разработана масштабируемая и параллельная среда обучения на Android для достижения этой цели с надежным универсальным оценщиком на основе VLM для быстрого сбора онлайн данных. Агент, обученный на DigiRL, достиг улучшения на 28.7% по сравнению с существующими передовыми агентами 18B CogAgent. Однако обучение было ограничено задачами из набора данных AitW, а не всеми возможными задачами управления устройствами. Поэтому будущая работа включает в себя разработку алгоритмических исследований и расширение области задач, сделав DigiRL базовым алгоритмом.
Ознакомьтесь с статьей. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 45k+ ML SubReddit.
Статья: «DigiRL: Новый автономный метод обучения с подкреплением RL для тренировки агентов управления устройствами» была опубликована на MarkTechPost.
«`


















