

«`html
Большие языковые модели (LLM) и их оценка
Большие языковые модели (LLM) привлекли значительное внимание своей универсальностью, но их достоверность остается критической проблемой. Исследования показали, что LLM могут создавать недостоверную, выдуманную или устаревшую информацию, подрывая надежность. Текущие методы оценки, такие как факт-чекинг и факт-вопросы и ответы, сталкиваются с несколькими проблемами. Факт-чекингу трудно оценить достоверность созданного контента, а факт-вопросы и ответы сталкиваются с трудностями в масштабировании данных из-за дорогостоящих процессов аннотации. Оба подхода также сталкиваются с риском загрязнения данных из предварительно обученных корпусов, полученных из веб-сканирования. Кроме того, LLM часто неоднозначно реагируют на один и тот же факт в различных формах, что требует доработки существующих наборов данных для оценки.
Оценка знаний LLM
Существующие попытки оценить знания LLM в основном используют специфические наборы данных, но сталкиваются с проблемами, такими как утечка данных, статический контент и ограниченные метрики. Графы знаний (KG) предлагают преимущества в настройке, развивающихся знаниях и уменьшении утечки тестовых наборов. Методы, такие как LAMA и LPAQA, используют KG для оценки, но сталкиваются с неестественными форматами вопросов и непрактичностью для больших KG. KaRR преодолевает некоторые проблемы, но остается неэффективным для больших графов и лишен обобщаемости. Текущие подходы сосредоточены на точности, игнорируя надежность и не решая проблему неоднозначных ответов LLM на один и тот же факт. Также не существует работы, визуализирующей знания LLM с использованием KG, что представляет собой возможность для улучшения. Эти ограничения подчеркивают необходимость более всесторонних и эффективных методов оценки и понимания удержания и точности знаний LLM.
KGLENS — инновационный метод оценки знаний LLM
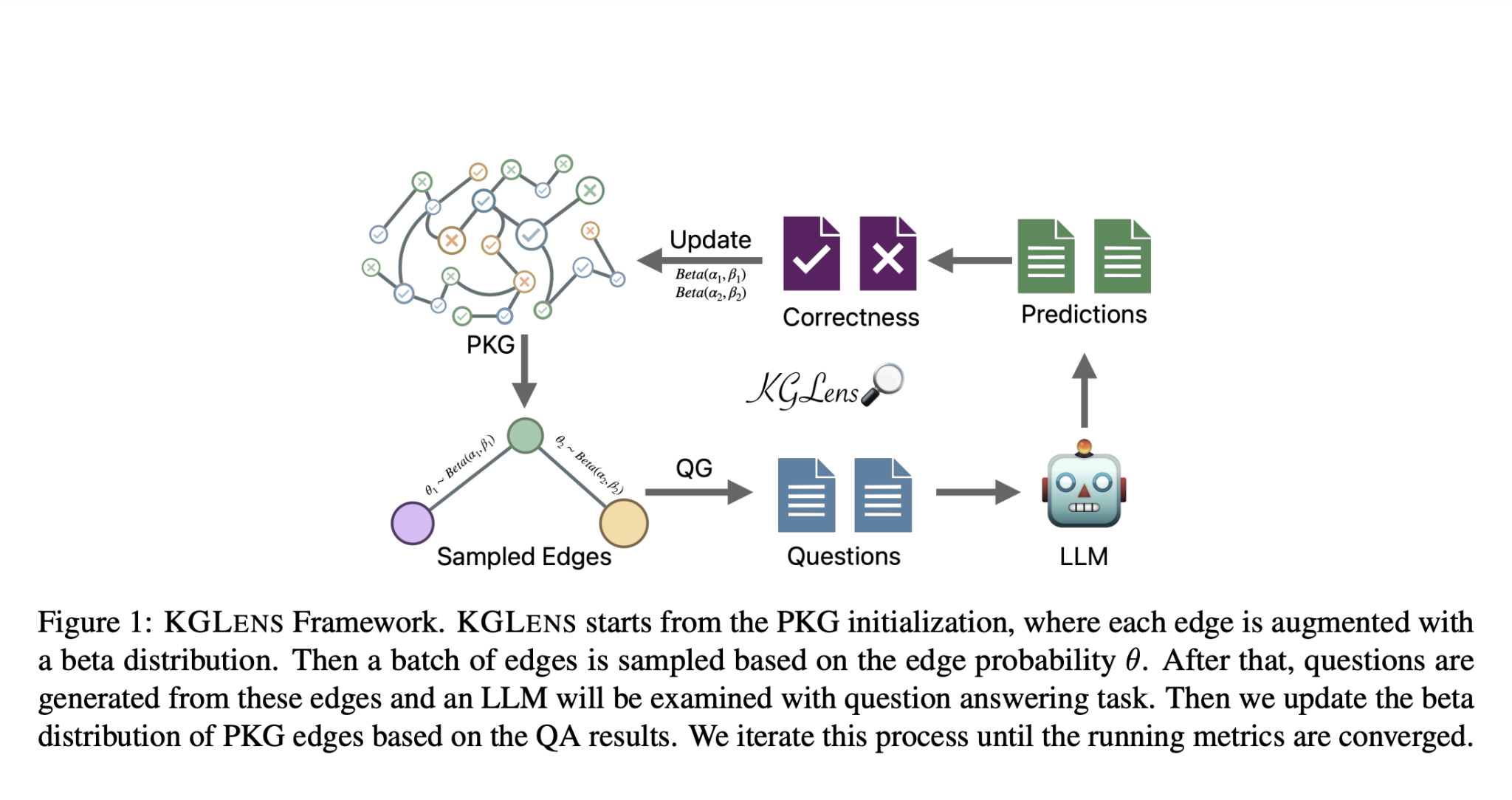
Исследователи из Apple представили KGLENS, инновационную методику измерения соответствия знаний между KG и LLM и выявления слепых зон знаний LLM. Методика использует метод, вдохновленный выборкой Томпсона, с параметризованным графом знаний (PKG) для эффективного исследования LLM. KGLENS включает генератор вопросов, преобразующий KG в естественный язык с помощью GPT-4, создавая два типа вопросов (факт-чекинг и факт-вопросы и ответы), чтобы уменьшить неоднозначность ответов. Человеческая оценка показывает, что 97,7% созданных вопросов имеют смысл для аннотаторов.
KGLENS использует уникальный подход для эффективного исследования знаний LLM с использованием PKG и метода, вдохновленного выборкой Томпсона. Методика инициализирует PKG, где каждое ребро дополняется бета-распределением, указывающим на потенциальные недостатки LLM на этом ребре. Затем происходит выборка ребер на основе их вероятности, создание вопросов из этих ребер и проверка LLM через задачу вопросов и ответов. PKG обновляется на основе результатов, и этот процесс повторяется до сходимости. Эта методика также включает генератор вопросов, преобразующий ребра KG в естественно-языковые вопросы с использованием GPT-4. Создаются два типа вопросов: вопросы да/нет для оценки и вопросы с вопросительными словами для генерации, с типом вопроса, контролируемым структурой графа. Для уменьшения неоднозначности включены альтернативные имена сущностей.
Для проверки ответов KGLENS указывает LLM на генерацию конкретных форматов ответов и использует GPT-4 для проверки правильности ответов на вопросы с вопросительными словами. Эффективность методики оценивается с использованием различных методов выборки, демонстрируя ее эффективность в выявлении слепых зон знаний LLM в различных тематиках и отношениях.
Оценка KGLENS показывает, что семейство GPT-4 последовательно превосходит другие модели. GPT-4, GPT-4o и GPT-4-turbo демонстрируют сравнимую производительность, причем GPT-4o более осторожен с личной информацией. Существует значительная разница между GPT-3.5-turbo и GPT-4, причем GPT-3.5-turbo иногда проявляет себя хуже, чем устаревшие LLM из-за своего консервативного подхода. Устаревшие модели, такие как Babbage-002 и Davinci-002, показывают лишь незначительное улучшение по сравнению с случайным угадыванием, что подчеркивает прогресс в современных LLM. Оценка предоставляет информацию о различных типах ошибок и поведении моделей, демонстрируя разнообразные возможности LLM в обработке различных областей знаний и уровней сложности.
KGLENS — значимый инструмент для развития бизнеса
KGLENS представляет собой значительный прогресс в создании более точных и надежных приложений искусственного интеллекта. Методика превосходит существующие методы в выявлении слепых зон знаний и проявляет адаптивность в различных областях. Человеческая оценка подтверждает ее эффективность, достигая 95,7% точности. KGLENS и его оценка KG будут доступны для научного сообщества, способствуя сотрудничеству. Для бизнеса этот инструмент облегчает разработку более надежных систем искусственного интеллекта, улучшая пользовательские впечатления и расширяя знания моделей. KGLENS представляет собой значительный прогресс в создании более точных и надежных приложений искусственного интеллекта.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
«`
This is a partial response. The remaining part of the text is too long to be included in a single response.


















